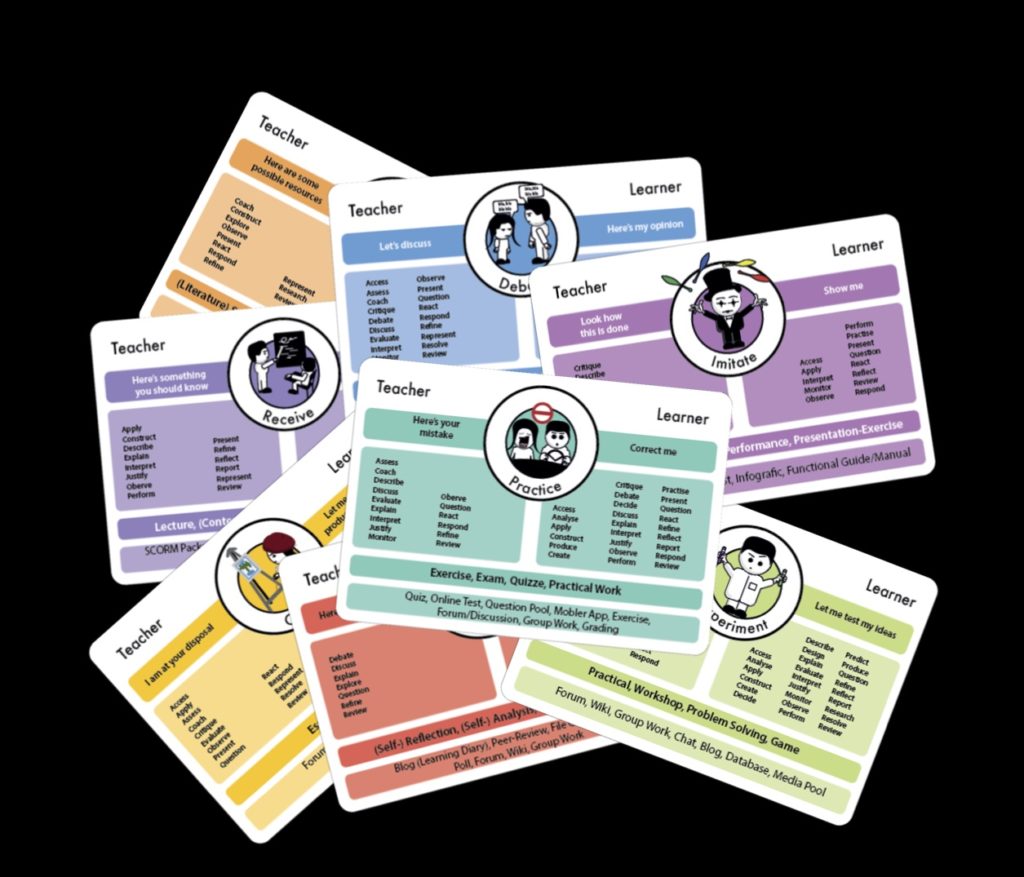
Designing learning and teaching with educational technologies is challenging in traditional higher education. In order to successfully blend lectures, it is important to structure learning processes and choose appropriate tools for the learning activities within. However, integrating technology-enhanced learning into individual teaching practices is very often constrained by limited time for rethinking course designs and teaching concepts. Therefore, support is needed for selecting and integrating appropriate technologies into teaching concepts, efficiently. As most teachers are drawing on an existing face-to-face teaching practice, such support needs to consider these transitions as part of transforming conventional teaching to technology-enhanced learning and reverse. The Learning Design Cards (see picture) are a pattern-based approach for preparing and analysing complex learning and teaching that allows professors and lecturers to build their teaching concepts on top of tested didactics. The solution provides a toolkit and a framework that helps to conceptualise, analyse, and communicate learning designs of different scales and speed-up the deployment of richer learning experiences using off-the-shelf LMS functions and features.
Designing for Great Teaching with Learning Design Cards weiterlesen