Im nächsten Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät» erzählt uns Daniel Ursprung, wissenschaftlicher Mitarbeiter am Historischen Seminar, von alternativen Leistungsnachweisen. In der Reihe geben Lehrende und Forschende der PhF uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen. Wir diskutieren den Begriff «Digital Humanities» von ganz verschiedenen Perspektiven aus.
Können Sie sich kurz vorstellen, Herr Ursprung?
 Mein Name ist Daniel Ursprung, ich bin wissenschaftlicher Mitarbeiter an der Abteilung für Osteuropäische Geschichte am Historischen Seminar. Dort bin ich in der Forschung und Lehre aktiv – in der letzten Zeit habe ich mich, v.a. im Bereich der Lehre, mit digitalen Technologien und deren Möglichkeiten auseinandergesetzt. Ich möchte den Studierenden einen niederschwelligen Einstieg in diese Technologien ermöglichen.
Mein Name ist Daniel Ursprung, ich bin wissenschaftlicher Mitarbeiter an der Abteilung für Osteuropäische Geschichte am Historischen Seminar. Dort bin ich in der Forschung und Lehre aktiv – in der letzten Zeit habe ich mich, v.a. im Bereich der Lehre, mit digitalen Technologien und deren Möglichkeiten auseinandergesetzt. Ich möchte den Studierenden einen niederschwelligen Einstieg in diese Technologien ermöglichen.
Können Sie uns ein Beispiel geben, was Sie in der Lehre anbieten?
Im Rahmen eines Lehrkredit-Projekts habe ich drei verschiedene Technologien ausprobiert, um damit alternative Formen von Leistungsnachweisen zu erstellen. Das ist einerseits der Einsatz von geospatial technologies, also die Arbeit mit geographischen Informationssystemen, die Raumanalysen und Kartenerstellung ermöglichen, etwa für historische Fragestellungen.
Wir haben andererseits auch Audiopodcasts erstellt – hier interviewten die Studierenden Forschende, die zum Thema der Lehrveranstaltung publiziert haben. Die Aufgabe für den Leistungsnachweis war es dann, aus den Interviews einzelne Sequenzen mit eigenem Input zu einem stimmigen Podcast zusammenzufügen.
In eine ähnliche Richtung gehen Videoessays. Dabei produzierten die Studierenden kurze Videofilme zu verschiedenen Themen der Lehrveranstaltung. Ausgangspunkt waren im Internet gefundene Videosequenzen, die mit zusätzlichen Materialien ergänzt wurden – z.B. Bilder, Statistiken, Karten oder sogar eigenem Videomaterial. Ziel war es, ein eigenes Storytelling zu entwickeln, um das Thema kurz und prägnant thesenartig zu vermitteln.
Haben Sie selber in diesen Bereichen gearbeitet – wie kamen Sie auf die Idee, diese Technologien in die Lehre zu bringen?
Das ist teilweise auch aus der Lehre heraus entstanden. In einer früheren Lehrveranstaltung zeigte ich als Auftakt zur Sitzung jeweils ein kurzes Video, quasi als Teaser zum Thema, ohne es aber weiter im Unterricht zu verwenden. Die Evaluation der Lehrveranstaltung zeigte dann, dass die Studierenden gerne mehr mit diesen Sequenzen gearbeitet hätten. So entstand die Idee, das Medium Video stärker und v.a. aktiver zu nutzen. Häufig ist es ja so, dass Videos zwar analysiert und als Quelle verwendet, sie aber in unseren geisteswissenschaftlichen Fächern selten selber produziert werden. Ich denke, es ist wichtig, die Medienkritik auch mal aus einer anderen Perspektive heraus zu stärken: wer selber ein Video produziert hat, sieht mit ganz anderen Augen und weiss aus Erfahrung, welche Grenzen das Medium für die Wissenschaftsvermittlung aufweist.
Bei den Podcasts war es so, dass ich selber gerne Wissenschaftspodcasts höre, zum Beispiel den Kanal New Books in History. Dort sind Interviews mit Autorinnen und Autoren wissenschaftlicher Werke zu finden, in denen man schnell viel darüber erfährt, was in der Forschung aktuell ist. Ich wollte so etwas Ähnliches auf einer niederschwelligen Ebene in der Lehre machen. Hier zeigte sich, dass diese Form ohne grosse technologische Voraussetzungen umsetzbar ist. Durch die Interviews konnten die Studierenden in Interaktion mit Wissenschaftlerinnen und Wissenschaftlern treten und so forschungsnahes Lernen erleben. Vor allem die Vorbereitung der Interviews erforderte eine intensive Beschäftigung mit dem Thema, war aber auch eine grosse Motivation.
Die Studierenden müssen dann auch wissenschaftliche Texte in eine ganz andere Form bringen können…
Genau – neben dem technologischen Aspekt gibt es immer den des Mediums: Was kann ein Medium leisten und wo sind seine Grenzen? Wie lassen sich wissenschaftliche Inhalte vermitteln und wo sind Vor- und Nachteile der einzelnen Kanäle? Hier geht es mir auch immer um eine kritische Haltung: Digitales soll kein Selbstzweck sein, sondern digitale Technologien sind Werkzeuge, bei denen immer zu überlegen ist, ob sie sich für die geplante Arbeit eignen oder ob analoge Methoden vorzuziehen sind.
So ist es etwa bei Podcasts schwierig, Schauplätze im Raum zu verorten: es gibt schlicht keine Möglichkeit, Visuelles wie eine Karte einzublenden. Genau umgekehrt ist es bei den Videos – hier muss der visuelle Raum ständig gefüllt werden, auch wenn kein passendes Bild- oder Videomaterial vorliegt. Das kann u.U. noch schwieriger sein als nichts zeigen zu können und zwingt zur Reflexion unserer Sehgewohnheiten. In der Praxis ist es nicht ganz einfach, all diese verschiedenen Medien wie Ton, Bild, Schrift sinnvoll zu kombinieren, ohne dass es langweilig oder umgekehrt überfordernd oder sogar manipulativ wird. Selber ein Video zu erstellen kann helfen, die Kritikfähigkeit zu schärfen, indem solche Probleme bewusst werden. Nicht so sehr ein professionelles Video ist Ziel dieser Art von Leistungsnachweis, sondern die kritische Reflexion darüber, welche Darstellungsformen in verschiedenen Medien funktionieren und welche Möglichkeiten für die Wissenschaftsvermittlung sich dabei eröffnen. Nicht zuletzt ist es auch eine Motivation für den Lernprozess.
Wissenschaft hat immer auch den Aspekt des Storytellings: Ob ich einen schriftlichen Text produziere oder einen Podcast macht dramaturgisch einen Unterschied. Und ein Storytelling hinzukriegen, das für das jeweilige Medium funktioniert, ist nicht ganz einfach. Die grundsätzlichen Überlegungen etwa zu den eingesetzten Stilmitteln sollen auch helfen, Erfahrungen zu sammeln, die dann auch wieder für das klassische Schreiben hilfreich sein können: welche Vorteile bietet mir der Text und wie gestalte ich ihn interessant, leicht verständlich und dennoch wissenschaftlich adäquat?
Interaktive Karte eines Cholera-Ausbruchs in Soho (London) 1854, Darstellung der Todesfälle mit Heatmap sowie nach Radius und Höhe skalierten räumlichen Säulendiagrammen: digitales Remake einer damals von Hand erstellten Karte von John Snow, ein Klassiker aus der Anfangszeit räumlicher Analysen. Deutlich ist zu erkennen, welche der Wasserpumpen für die Infektion verantwortlich war. Die Karte lässt sich per Mausklick drehen und vergrössern, einzelne Säulen können angewählt werden.
Mich würde auch das Kartenprojekt sehr interessieren – gerade räumliche Daten sind im technischen Umgang ja nicht einfach. Wie führen Sie Studierende an diese Themen heran?
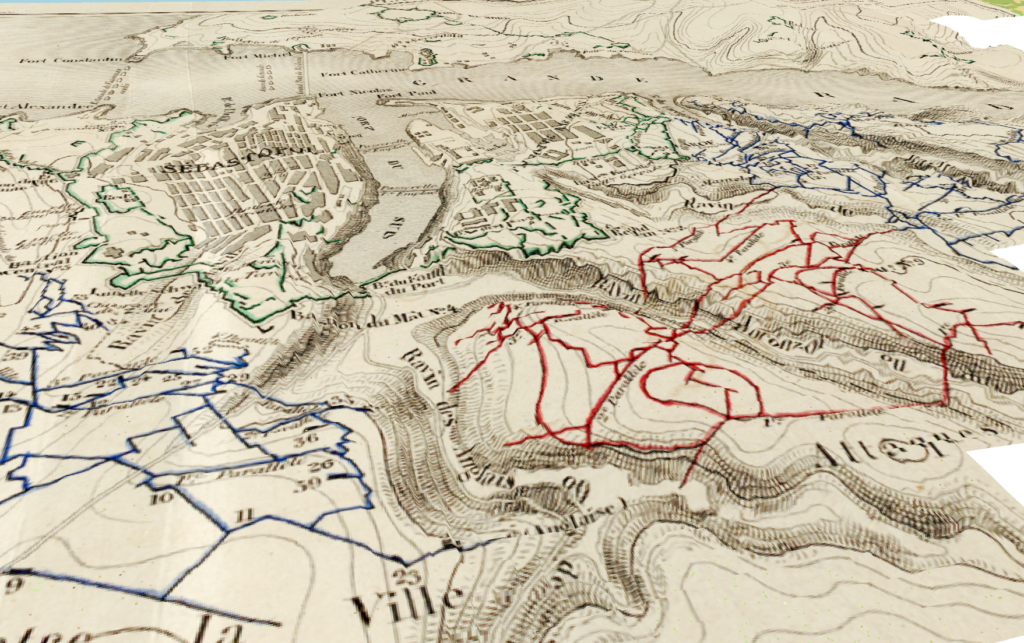
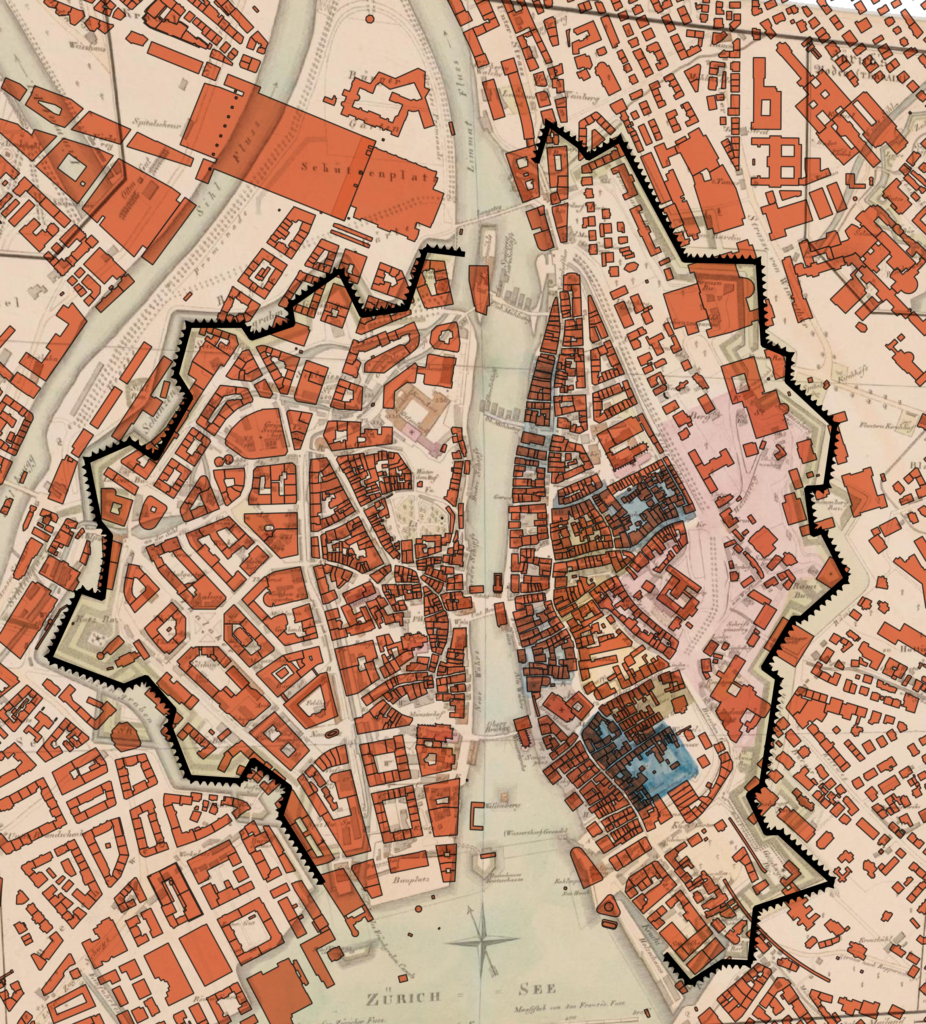
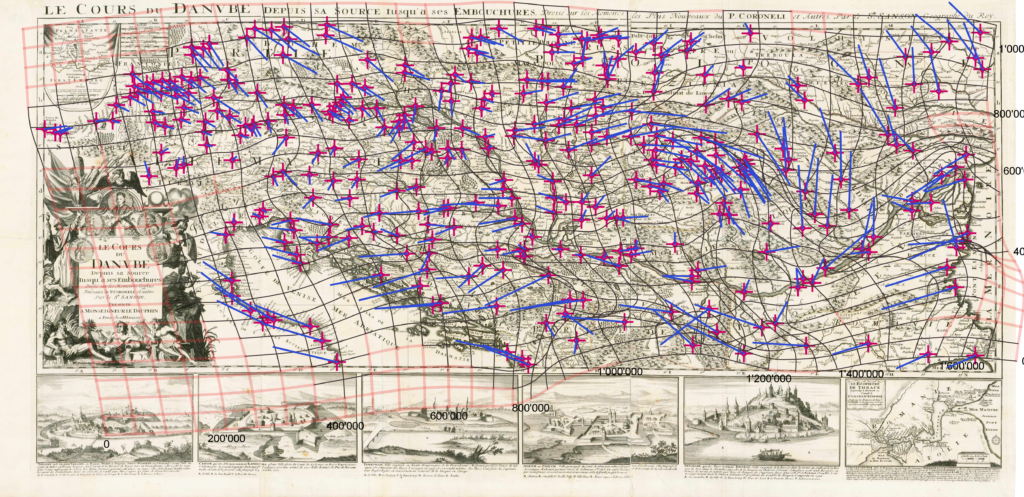
In der Osteuropäischen Geschichte müssen wir fast immer mit Karten arbeiten, weil diese Räume vielen Leuten nicht auf Anhieb bekannt sind. Geschichtskarten aber werden kaum reflektiert und oft unkritisch genutzt: Wie und auf welcher Grundlage sie entstanden sind, ist meist intransparent. Seltsamerweise wird das fast nie thematisiert. Der Aufwand, eine gute Karte zu erstellen, ist mitunter ähnlich hoch wie für einen guten Aufsatz – bei der Karte aber fehlt der wissenschaftliche Apparat. Auch wird selten thematisiert, was eine Karte darstellen kann und was nicht. Wo führt eine kartographische Darstellung in die Irre? In Publikationsprojekten hatte ich schon die Gelegenheit, zu eigenen Texten Karten extern erstellen zu lassen. Damit gebe ich aber einen Teil der Kontrolle an eine/n Kartographin/en ab. Mit den heutigen technischen Möglichkeiten müsste es doch möglich sein, einfache Karten selber zu erstellen, dachte ich mir. In einer Lehrveranstaltung zur Geschichte der Kartographie habe ich dann erstmals digitale Technologien genutzt für die Arbeit mit Karten aus früheren Jahrhunderten. So bin ich dann auf QGIS gestossen, eine open source Software, mit der sich fast alles realisieren lässt, was im Bereich GIS möglich ist. Damit können zwar auch Karten erstellt werden, das Spektrum an Einsatzszenarien aber ist sehr viel breiter. In der Lehre einfache Karten zu erstellen ist ein guter Ausgangspunkt für einen intuitiven Einstieg in die wissenschaftliche Arbeit mit digitalen Technologien. Darauf aufbauend können dann schrittweise zentrale Fragen des Umgangs mit digitalen Technologien generell erarbeitet werden wie Modellierung, Management, Analyse und Visualisierung von Daten, Verständnis und Reflexion digitaler Verarbeitung bis hin zu Computational Thinking und Beurteilung der Folgen, die das dann letztlich wiederum für die eigene wissenschaftliche Arbeit hat.
Von den drei ausprobierten Formaten sehe ich im Bereich der spatial humanities das grösste Potential für die Lehre. Dies aus mehreren Gründen: Alle kennen Karten aus dem Alltag, sei es gedruckt oder auch als Navigation auf dem Handy. Mit einfachen Übungen, ohne grosse technische Kenntnisse, lässt sich mit QGIS bereits ein kleines Einstiegsprojekt erstellen, um die Schwellenangst vor dem Einsatz digitaler Methoden zu überwinden und den Bezug zum Fach aufzuzeigen. Davon ausgehend lässt sich die Komplexität dann steigern.
Wir haben zum Beispiel als Einstieg die Reiseroute einer Pilgerreise aus dem 15. Jahrhundert von Bayern nach Jerusalem auf einer Karte visualisiert. Die Frage war dann, welche Erkenntnisse sich aus einer solchen Visualisierung gewinnen lassen. Sie ermöglichen einen ganz anderen Zugang und machen auf Aspekte aufmerksam, die bei der reinen Textlektüre leicht übersehen werden. Ausserdem liegt eine Karte nicht einfach vor, sondern ist aufgrund eigener Entscheidungen entstanden und kann beliebig verändert werden.
Für die Schulung von digital skills in der akademischen Lehre haben geographische Informationssysteme (GIS) den Vorteil, dass damit fast alle digitalen Kernkompetenzen trainiert werden können: Wie werden z.B. aus historischen Quellen maschinenlesbare Daten für eine Datenbank, d.h. die Frage der Datenmodellierung. Welche Schritte sind hier auch aus methodischer und theoretischer Sicht notwendig? Hier kommt das digitale und fachwissenschaftliche zusammen. Manchmal können bestehende Daten übernommen werden. Da stellen sich Fragen zur Herkunft der Daten, wie vollständig, akkurat und präzise sie sind sowie danach, wer sie warum erstellt hat und was sie repräsentieren. Dann ist natürlich wichtig zu fragen, wie Algorithmen funktionieren – was machen sie mit den Daten, welches sind die einzelnen Schritte? Und wie ist der gesamte Verarbeitungsprozess zu gestalten und kritisch zu bewerten? Auch hinter der Software stehen ja letztlich immer bestimmte gesellschaftliche Interessen und Sichtweisen – welche Implikationen hat das für die wissenschaftliche Arbeit?
Könnten Sie uns ein Beispiel geben, wie sie bei der Datenmodellierung konkret vorgegangen sind?
Für das Beispiel der Pilgerreise haben die Studierenden den Quellentext erst einmal ohne Vorgaben aufbereitet. Es handelt sich um kurze Tagebucheinträge, die beschreiben, an welchem Tag die Reisenden wo waren, wie weit sie gereist sind, wo sie übernachtet haben etc. Die Studierenden haben dann die Orte aufgeschrieben und zunächst auf Google Earth visualisiert. Interessant war dann zu sehen, wie unterschiedlich die Ergebnisse ausfallen. Sofort entstand etwa die Frage, wie sich Zeit modellieren lässt: Nehmen wir etwa Zeitpunkte oder Zeiträume? Wie gehe ich damit um, wenn unklar ist, was in der Zwischenzeit passiert ist? Die Frage, wie eine solche Reise visualisiert wird, ist nicht ganz so trivial wie es scheinen mag und öffnet den Blick für grundlegende methodische Fragen. Das ist ein guter Anlass, um über verschiedene Zeitkonzeptionen, ein Thema der Geschichtsphilosophie, zu sprechen. Digitale Arbeitsweisen können also auch Ausgangspunkt sein, sich durchaus auf klassisch-analoge Weise über grundlegende Konzepte des eigenen Fachs Gedanken zu machen.
Gerade bei historischen Fragestellungen existieren oft nur vage Angaben. Bei Reiseberichten sind vielfach nur Etappenorte bekannt, nicht aber der konkrete Verlauf der historischen Verkehrswege. Oder wenn in einer Quelle «hinter dem Hügel» oder «in der Nähe des Baches» steht, ist nicht einmal der Ort ganz klar. Auch hier ist dann zu überlegen, wie solche historische Unschärfe passend zu modellieren ist. Oft merkt man erst, wie viele Informationen eigentlich gar nicht vorhanden sind, wenn man versucht, diese Informationen in eine digitale Form zu bringen. So treten Inkonsistenzen zu Tage, die bei der reinen Lektüre nicht offensichtlich sind.
Die Frage ist immer, was sind die relevanten Informationen, und dies wiederum bedeutet stets: Was ist mein Erkenntnisinteresse? In Übungen mit den Studierenden sollen diese Informationen dann in strukturierter Form erfasst werden. Dabei lässt sich gut zeigen, wie wichtig es ist, die Daten möglichst kleinteilig auf verschiedene Felder aufzuteilen, damit sie in einer Datenbank gut verarbeitet werden können. Hier kann ich dann quasi durch die Hintertür ein wenig Datenbanktheorie einführen, nicht in einem grossen theoretischen Rahmen, sondern immer ausgehend von einem empirischen Fallbeispiel und einer Fragestellung. So lassen sich induktiv und vom fachwissenschaftlichen Kontext ausgehend digitale Themen anschaulich vermitteln.
Denken Sie, dass geisteswissenschaftliche Studierende heute also mit Daten umgehen und algorithmisch denken können sollten?
Das hängt immer von der Fragestellung ab – es gibt nach wie vor viele Bereiche, in denen diese Technologien nicht zwingend notwendig sind. Analoge und digitale Methoden haben beide ihre Daseinsberechtigung. Digitale Technologien sind Werkzeuge, die in gewissen Fällen ganz neuartige Fragestellungen ermöglichen. Es ist zumindest gut zu wissen, was überhaupt möglich ist, welche zusätzlichen Arten des Umgangs mit den vorhandenen Quellen existieren und welches wissenschaftliche und didaktische Potenzial darin steckt. Dabei helfen wenigstens rudimentäre Kenntnisse über oder zumindest ein Verständnis für digitale Technologien und die Chancen, die sie eröffnen, um unser methodisches Repertoire zu erweitern.
Würden Sie auch in diese Richtung argumentieren, wenn Sie den Begriff «Digital Humanities» definieren müssten?
Ich weiss nicht, inwiefern eine Definition sinnvoll ist. Für mich ist es kein geschlossener Ansatz oder eine klare Disziplin, sondern ein kontextbezogener Einsatz von digitalen Technologien, der Hand in Hand geht mit den klassischen Methoden der Fachwissenschaft. In der Geschichtswissenschaft kennen wir die sogenannten Hilfswissenschaften (und das ist nicht despektierlich gemeint) wie Paläographie oder Diplomatik. Ich glaube, das Digitale hat, zumindest in der Geschichtswissenschaft, diese Funktion: Ich suche mir das passende Werkzeug für den jeweiligen wissenschaftlichen Kontext. Wichtig ist es, immer kritisch zu bleiben. Die Frage ist: kann ich die Fragestellung mit einer digitalen besser beantworten als mit einer analogen Methode? Oder kann ich andere Fragen beantworten, wenn ich digital arbeite – Fragen, die ich mit analogen Mitteln so nicht bearbeiten kann?
Um diese Entscheidung zwischen analogen und digitalen Methoden fällen zu können, muss man die Kompetenz aber schon haben…
Wie fast immer in der Wissenschaft ist hier Neugier und Offenheit entscheidend. Gerade in der Geschichtswissenschaft ist das Spektrum methodischer und theoretischer Arbeitsweisen enorm breit, niemand nutzt alle verfügbaren Ansätze. Und Historiker/innen sind in aller Regel keine Programmierer/innen. Aber natürlich ist es so: Je mehr Kompetenzen jemand mitbringt, desto eher können auch innovative Fragestellungen entwickelt werden. Ich vergleiche das in der Geschichtswissenschaft immer mit den Sprachkompetenzen – je mehr Sprachen ich spreche, desto mehr Quellen kann ich nutzen. Im Digitalen ist es genauso. Zumindest ist es hilfreich zu wissen, was mit digitalen Technologien überhaupt möglich ist, ohne das unbedingt selber umsetzten zu können. Gerade in Forschungsteams sind vielleicht Personen dabei, die programmieren können.
Stichwort Forschung: Hier ist es einfacher als in der Lehre, Leute mit Interesse an interdisziplinären Projekten zu finden, weil das Reputation gibt und finanziert wird. Ein gemeinsamer Antrag wird eingereicht und gemeinsame Publikationen verfasst. In der Lehre wird es schwieriger, wenn ich nur punktuell externe technologische Expertise einbeziehen möchte: Wer ist bereit, mir für eine Lehrveranstaltung z.B. eine Netzwerkanalyse zu programmieren? So etwas wird in der Wissenschaftslandschaft kaum honoriert. Und Dozierende können unmöglich neben ihrer eigenen Fachwissenschaft auch noch technologisch breit versiert sein.
Ich sehe das als Herausforderung für die Zukunft der digitalen Lehre – wie geht man auf institutioneller Ebene damit um? Gibt es Lösungen, bei Bedarf auch in der Lehre für spezifische technische Hilfestellung Kompetenzen anderer Fächer niederschwellig abrufen zu können? Denn digitale Methoden sollen in der Lehre nicht als separater Bereich parallel geführt werden, sondern auch punktuell in reguläre Lehrveranstaltungen eingebettet werden – embedded digital teaching sozusagen. Dazu braucht es aber halt oft externe Expertise.
Auf der Ebene der Infrastruktur werden zentrale Dienste wie S3IT langsam aufgebaut, auf die man als Forschende zugreifen kann. Aber Sie reden jetzt eigentlich eher von «Personellem», von Denk- und Arbeitskraft…
Für die Forschung ist das Angebot der S3IT sicher richtig, wenn es um Infrastruktur für Big Data und so weiter geht. Im Bereich Lehre sind es zum Teil andere Herausforderungen.
Ich wünsche mir für die meisten Bereiche eigentlich genau so ein Angebot, wie es das Team DLF anbietet – wo etwa kompetent Fragen beantwortet werden danach, welches Tool sich für Videoschnitt eignet, wie es funktioniert etc. Doch natürlich existieren immer auch spezifische Einsatzszenarien, die so eine Stelle gar nicht alle abdecken kann. Die Universität ist aber so vielfältig, dass bestimmt irgendwo jemand sitzt, die/der genau dabei helfen könnte – eben zum Beispiel, eine Netzwerkanalyse programmieren zu helfen. Die Schwierigkeit besteht darin, die entsprechende Person zu finden und sie dazu zu bringen, interdisziplinäre «Entwicklungshilfe» zu leisten, wenn dabei anders als in der Forschung wenig Aussicht auf Reputation besteht. Mir schwebt etwa vor, dass vielleicht Studierende der Computerwissenschaften in der Funktion «teach the teacher» hier Aufgaben übernehmen könnten und zum Beispiel niederschwellig während ein bis zwei Sitzungen im Semester bei der technischen Umsetzung helfen.
Hinzu kommt, dass ein Semester eigentlich zu kurz ist, um ein geisteswissenschaftliches Modul anzubieten, in dem neben den fachwissenschaftlichen Methoden und Inhalten auch noch substanzielle Software- oder Medien-Skills vermittelt werden müssen. Auch die Unterschiede der Voraussetzungen zwischen den Studierenden sind zum Teil enorm. Wo wäre der ideale Ort im Curriculum für die Vermittlung praktischer Software-Skills? In geisteswissenschaftlichen Fächern wird das ja kaum honoriert und basiert auf dem Engagement und Interessen der Einzelnen.
Die Kurse der Zentralen Informatik bieten hier ein gutes Angebot. Doch sind sie einerseits curricular nicht eingebunden. Andererseits besteht auch Bedarf an stärker fachwissenschaftlich ausgerichteten Angeboten, die spezifisch auf die Humanities und ihre Einsatzszenarien eingehen. Ein Beispiel wäre, die Datenbankprogrammierung ausgehend von Quellentexten zu lernen anstatt vom Klassiker «Adressdatenbank». Oder wieso soll ich als Geisteswissenschaftler Python programmieren lernen? Um diese Frage zu beantworten muss ich die Möglichkeiten kennen, die mir diese Programmiersprache in meinem Fachgebiet eröffnet. In einem traditionellen Python-Kurs erfahre ich dazu wenig. Wenn aber inspirierende Beispiele aus der Wissenschaft existieren, eröffnen sich neue Horizonte. Ein gutes online Selbstlernangebot ist etwa die Seite The Programming Historian – vergleichbare Übungen können auch in Lehrveranstaltungen ohne spezifischen digitalen Fokus eingebaut werden.
Es bräuchte «Forschungsgeschichten» als Vorbilder… und eine Vernetzung von ganz unterschiedlichen Disziplinen, die einander aushelfen können. Für die Lehre wäre auch ein Projektpool interessant, in dem Projekte mit Informatikbedarf und Studierende mit Informatikkenntnissen «gematcht» werden. Mit den Projekten könnten die Studierenden so eine Art «überfakultäre Projektcredits» erwerben. Oft ist es ja auch so, dass man im Rahmen eines Moduls ein Projekt nach technologischen Vorgaben programmieren muss, aber keine inhaltliche Idee hat.
Ich fürchte, dafür bräuchte es dann wohl wieder eine Studienreform… Es ist schon die Frage, ob dies curricular eingebettet werden oder eher über Tutorate und Geldwerte abgewickelt werden soll. Für Studierende ist interdisziplinäre Zusammenarbeit auf Einsteigerlevel in der Lehre vielleicht noch interessanter als für Forschende, die schon etabliert sind. Wichtig ist, dass Ideen entwickelt werden und auch zirkulieren.
Haben wir ein Thema vergessen oder möchten Sie etwas ergänzen?
Wichtig ist, dass gerade die Studierenden in den traditionell wenig technikaffinen Geisteswissenschaften möglichst früh (also bereits im Bachelor) die Gelegenheit erhalten, digitale Technologien im jeweiligen Fach anzuwenden. Mein Anliegen ist es immer, digitale Methoden möglichst niederschwellig einzubringen, um auch Leute anzusprechen, die keine Technikfreaks sind. Im weiteren Studienverlauf ist dann noch genügend Zeit, das bei Interesse selber zu vertiefen. Nach einer ersten Einführung ist die Schwellenangst hoffentlich überwunden.
Allerdings finde ich es auch ganz wichtig, dass kein Zugzwang entsteht: Der Einsatz digitaler Werkzeuge soll nicht überhöht oder gegen klassische Arbeitsweisen ausgespielt werden. Die akademische Lehrfreiheit muss unbedingt auch die Methodenfreiheit umfassen, stets das jeweils passende Instrument zu wählen.
Foto Titelbild (Portrait): Frank Brüderli
Im Beitrag erwähnte Links und Technologien:
https://newbooksnetwork.com/category/history/
https://programminghistorian.org/