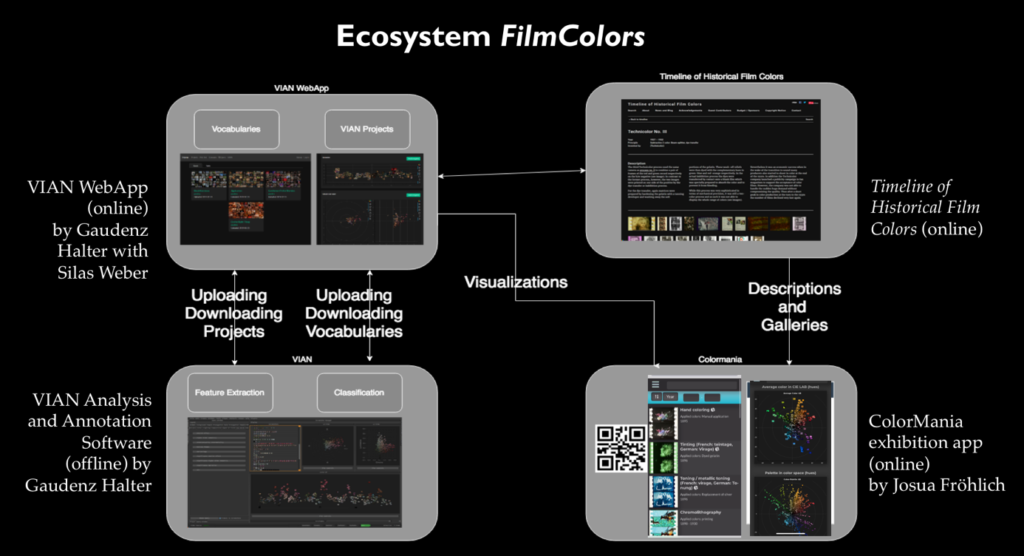
Das neue Text Crunching Center (TCC) hilft bei Textanalysen und bei Fragen wie: Wie komme ich zu meinen Daten? Wie muss ich sie für meine Forschungsfrage aufbereiten, oder – welche Fragen kann ich an meine Daten stellen? Angesiedelt am Institut für Computerlinguistik und konzipiert als Dienstleistungszentrum – wir hören in diesem Beitrag, für wen das TCC gedacht ist und welche Dienstleistungen angeboten werden.
Bitte stellen Sie sich vor!
 [Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert.
[Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert.
 [Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.
[Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.
Vielen Dank für die Vorstellung – wie ist denn nun das Text Crunching Center entstanden?
[GS] Entstanden ist das Text Crunching Center dadurch, dass das Institut für Computerlinguistik bzw. Martin Volk inzwischen so viele Anfragen im Gebiet Text Mining und Textanalyse erhält, dass es nicht mehr länger möglich ist, diese alle selbst zu bearbeiten.
Das Text Crunching Center bietet in diesem Gebiet Dienstleistungen an: Bei allem, was mit Text Mining, Sentimentanalyse, Textanalyse im Allgemeinen – generell mit Methoden der Digital Humanities oder Machine Translation – zu tun hat, können wir Projekte unterstützen. Auch allgemeine Unterstützung für Digitalisierungsprozesse oder Textverarbeitung wie OCR, aber auch Beratung zu Tools, Software oder Best Practices bieten wir an. Wir helfen ebenfalls gerne beim Schreiben von Projektanträgen, geben Coaching und Unterricht in der Textanalyse, oder können fertige (Software-)Lösungen anbieten.
[TE] Wir sind die Ansprechpartner für alle, die in ihren Projekten mit viel Text umgehen müssen, das technische Knowhow aber nicht haben und nicht genau wissen, wo sie anfangen sollen. Man kann z.B. zu uns kommen, wenn man einfach Text vor sich hat und eine Idee braucht, was man damit mit der Maschine alles anfangen könnte.
Könnten Sie mir ein konkretes Beispiel einer Anfrage geben – wie muss man sich den Ablauf vorstellen, wenn man auf Sie zukommt?
[TE] Wenn z.B. jemand aus einem bestimmten Forschungsgebiet untersuchen möchte, was der öffentliche Diskurs zu einem Thema ist – nehmen wir mal das Thema «Ernährung». Dazu möchten sie dann gerne Social Media Daten auswerten, die technische Umsetzung ist gehört aber nicht zu ihrem Fachgebiet. In dem Fall kann man zu uns gelangen und wir beraten in einem ersten Schritt: Wir klären die Fragen, wie man überhaupt an Daten gelangen kann, was man mit den Daten machen könnte. Es kann so weit gehen, dass wir einen Prototypen erstellen, mit dem sie dann direkt ihre Daten auswerten und Forschungsergebnisse erhalten können.
Welche konkreten Möglichkeiten würden Sie in den Personen in diesem Beispiel vorschlagen und wie würden sie es umsetzen?
[GS] In diesem konkreten Beispiel haben wir Twitter-Daten mit Hilfe von Text Mining gesammelt und ein Coaching angeboten. Die R Skripts haben wir ebenfalls geschrieben, die Personen aber zusätzlich so weit gecoacht, dass sie diese schliesslich selbst anwenden konnten. Die über das Text Mining erhaltenen Daten werden mit den Skripts exploriert und verschiedene Outputs generiert. Dabei haben wir «klassische» Digital Humanities Methoden angewendet wie z.B. Distributionelle Semantik, Topic Modeling, oder auch analysiert, wie in den Tweets bestimmte linguistische Merkmale gebraucht werden.
[TE] Es kommt immer auf die Kunden darauf an: In diesem Beispiel wollten die Kunden die Anwendung gerne selber lernen. Wenn sie dafür aber keine Zeit oder kein Interesse daran gehabt hätten, hätten wir auch alles selbst implementieren können: Also das fertige System oder die aufbereiteten Daten.
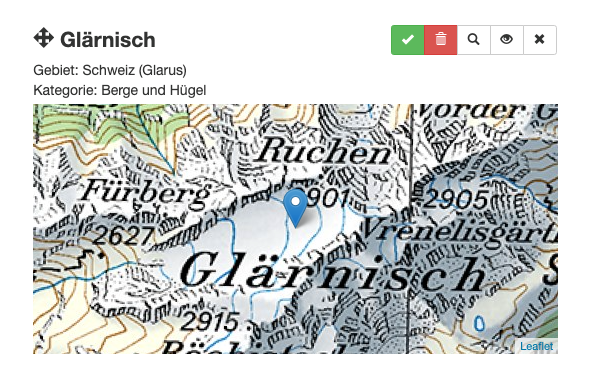
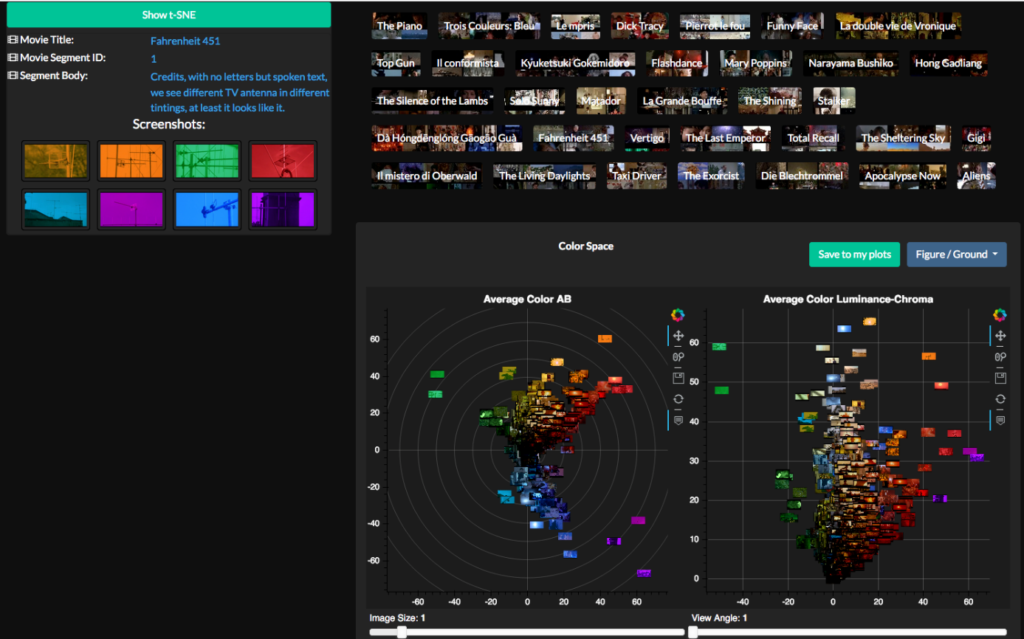
[GS] Ein Produkt, das dabei entstanden ist, ist eine «konzeptuelle Karte» von Bier, Cidre und Wein. Es ist eine semantische Karte, in der ähnliche Konzepte näher beieinander liegen als Konzepte, die inhaltlich weiter voneinander entfernt sind. Rund um den Cidre liegen beispielsweise die Begriffe «Äpfel», «Jahreszeit», «Wärme» usw. Man sieht auch, dass die Essenskultur mit «dinner», «cooking», etc. viel näher am Konzept «Wein» liegt als bei «Bier» oder «Cidre». Solche automatisch erstellten Karten vereinfachen stark, sind aber anschaulich und gut interpretierbar, deshalb zeigen wir sie als ein Beispiel unter vielen.
Eine ähnliche Karte etwa entstand in einem anderen Projekt aufgrund von Daten ausgewählter Reden von Barack Obama und Donald Trump. Barack Obama spricht etwa mehr von «opportunity» oder «education», während Donald Trump davon eher weiter weg ist und eher über China und Deals spricht, und wer ihm alle angerufen haben. «Peace and Prosperity» als Vision versprechen natürlich beide.
Nun rein technisch gefragt – wie entsteht so eine konzeptuelle Karte? Die Verbindungen stellen die Distanzen zwischen den Konzepten dar, nehme ich an – mit welcher Methode bestimmen Sie denn die Ähnlichkeiten?
[GS] Es handelt sich um eine Methode der distributionellen Semantik: Man lernt aus dem Kontext. D.h. dass Wörter, die einen ähnlichen Kontext haben, auch semantisch ähnlich sind. Gerade bei grossen Textmengen führt so ein Ansatz zu guten Ergebnissen. Es gibt da verschiedene Methoden, um dies zu bestimmen – gemeinsam ist ihnen jedoch der kontextuelle Ansatz.
In diesem konkreten Beispiel wurde mit Kernel Density Estimation gearbeitet. Man zerlegt dafür den Korpus zunächst in kleine Teile – hier waren es etwas 2000. Für jedes Wort prüft man dann, wie das gemeinsame Auftreten in den 2000 «Teilen» ist. Wörter, die sehr häufig miteinander auftreten, kommen dann das Modell. Dabei werden nicht die absoluten Zahlen verwendet, sondern Kernel-Funktionen gleichen die Zahlen etwas aus. Daraus kann schliesslich die Distanz zwischen den einzelnen Konzepten berechnet werden. In diesem Prozess entsteht ein sehr hochdimensionales Gebäude, das für die Visualisierung auf 2D reduziert werden muss, um es plotten zu können. Da dies immer eine Vereinfachung und Approximierung ist, braucht es immer die Interpretation.
Wie wichtig ist es für Ihre Aufgabe, dass Sie einen breiten disziplinären Hintergrund haben?
[TE] Man darf nicht denken, dass die Texttechnologie das «Wunderheilmittel» für alle Probleme ist. In einer Beratung geben wir immer eine realistische Einschätzung darüber ab, was möglich ist und was nicht.
Daher ist die Frage sehr relevant. Man muss einen gemeinsamen Weg zwischen der computerlinguistischen und der inhaltlichen Seite finden. Es ist wichtig, dass wir beide durch unseren Werdegang viele Disziplinen abdecken und schon in vielen verschiedenen Bereichen mitgearbeitet haben.
Gerade in einem Projekt aus der Biomedizin, in dem es darum ging, welche Auswirkungen bestimmte Chemikalien auf gewisse Proteine haben, hat mein biologisches Wissen aus dem Biologie-Leistungskurs und einem Semester Studium sehr geholfen. Als Laie würde man diese Texte überhaupt nicht verstehen, deshalb könnte man auch keine geeignete Analyse entwerfen. Insbesondere auch auf der Ebene der Fehleranalyse ist das Disziplinen-Wissen wichtig: Möchte man herausfinden, warum das entwickelte System in manchen Fällen nicht funktioniert hat, hat man ohne disziplinäres Wissen wenig Chancen.
Deshalb ist es wichtig, dass wir realistische Einschätzungen darüber abgeben können, was umsetzbar ist – manche Fragen sind aus computerlinguistischer Sicht schlicht nicht auf die Schnelle implementierbar.
[GS] Dennoch können oft neue Einsichten generiert werden, oder auch nur die Bestätigung der eigenen Hypothesen aus einer neuen Perspektive… Die datengetriebenen Ansätze ermöglichen auch eine neue Art der Exploration: Man überprüft nicht nur eine gegebene Hypothese, sondern kann aus der Datenanalyse neue Hypothesen generieren, indem man Strukturen und Muster in den Daten erkennt.
Hier hat sich bei mir ein Kreis geschlossen: Aus der Literaturwissenschaft kenne ich das explorative Vorgehen sehr gut. Dagegen ist ein rein computerlinguistisches Vorgehen schon sehr anders. Mit Ansätzen der Digital Humanities kommt nun wieder etwas Spielerisches in die Technologie zurück. Die Verbindung von beidem erlaubt einen holistischeren Blick auf die Daten.
Wie würden Sie denn Digital Humanities beschreiben?
[GS] Es ist wirklich die Kombination der beiden Ansätze: «Humanities» kann man durchaus wortwörtlich nehmen. Gerade in der Linguistik ist damit auch ein Traum wahr geworden, wenn man an Ferdinand de Saussures Definition von Bedeutung denkt. «La différence», die Bedeutung, ergibt sich nicht daraus, was etwas «ist», sondern was es im Zusammenhang, im Ähnlich-Sein, im «Nicht-genau-gleich-sein» mit anderen Dingen ist. In der Literaturwissenschaft wird dieser Umstand in der Dekonstruktion mit der «différance» von Jacques Derrida wieder aufgenommen. Die distributionale Semantik hat genau das berechenbar gemacht. Es ist zwar einerseits sehr mathematisch, andererseits ist für mich dieser spielerische Zugang sehr wichtig.
Die genaue philosophische Definition von Digital Humanities ist für mich dagegen nicht so wichtig: Doch die Möglichkeiten, die sich mit den digitalen Methoden ergeben – die sind toll und so viel besser geworden.
[TE] Die Humanities, die bisher vielleicht noch nicht so digital unterwegs waren, geraten momentan auch etwas unter Druck, etwas Digitales zu benutzen…
Mein Eindruck war bisher nicht nur der eines «Müssens», sondern auch eines «Wollens» – doch der Einstieg in die Methodik ist einfach sehr schwierig, die Schwelle sehr hoch.
[TE] … und gerade hier können wir einen sehr sanften Einstieg mit unseren Beratungen bieten: Wenn jemand noch gar keine Erfahrung hat, aber ein gewisses Interesse vorhanden ist. So muss niemand Angst vor der Technologie haben – wir begleiten das Projekt und machen es für die Kunden verständlich.
[GS] Aber auch Kunden, die schon ein Vorwissen haben und bereits etwas programmieren können, können wir immer weiterhelfen…
Gilt Ihr Angebot nur für Lehrende und Forschende oder auch für Studierende?
[TE] Das Angebot gilt für alle, auch für externe Firmen. Für wissenschaftliche Projekte haben wir aber natürlich andere, günstigere Tarife.
[GS] Die Services werden zum Selbstkostenpreis angeboten. Ein Brainstorming, d.h. ein Einstiegsgespräch können wir sogar kostenlos anbieten. Auch für die anschliessende Beratungs- oder Entwicklungsarbeit verlangen wir keine überteuerten Preise. Für unser Weiterbestehen müssen wir allerdings eine gewisse Eigenfinanzierung erreichen.
Wo soll das Text Crunching Center in einigen Jahren stehen?
[TE] Natürlich möchten wir personell noch wachsen können… Wir bilden uns dauernd weiter, um state-of-the-art-Technologien anbieten zu können. Die Qualität der Beratung soll sehr hoch sein – das wünschen wir uns.
[GS] … und wir wollen die digitale Revolution unterstützen, Workshops anbieten, das Zusammenarbeiten mit dem LiRI oder mit Einzeldisziplinen verstärken. Letztlich können alle von der Zusammenarbeit profitieren, indem man voneinander lernt und Best Practices und Standardabläufe für gewisse Fragestellungen entwickelt. Auch die Vernetzung ist ein wichtiger Aspekt – wir können helfen, für ein bestimmtes Thema die richtigen Experten hier an der UZH zu finden.
Ich drücke Ihnen die Daumen! Vielen Dank für Ihr Gespräch!
Links:
Text Crunching Center: https://www.cl.uzh.ch/en/TCC.html
Ein Anwendungsbeispiel aus Projekten des TCC: https://www.cl.uzh.ch/en/TCC/Teasers.html
Openbook zu Statistik für Linguisten (Gerold Schneider und Max Lauber): https://dlf.uzh.ch/openbooks/statisticsforlinguists/
Ferdinand de Saussure: https://de.wikipedia.org/wiki/Ferdinand_de_Saussure
Jacques Derrida: https://de.wikipedia.org/wiki/Jacques_Derrida
Kernel Density Estimation: https://de.wikipedia.org/wiki/Kerndichteschätzer
NCCR Democracy: http://pwinfsdw.uzh.ch/
LiRi: https://www.liri.uzh.ch/en.html
Off Topic:
Ein eigenes Openbook bei Digitale Lehre und Forschung publizieren: https://dlf.uzh.ch/openbooks/erste-schritte/