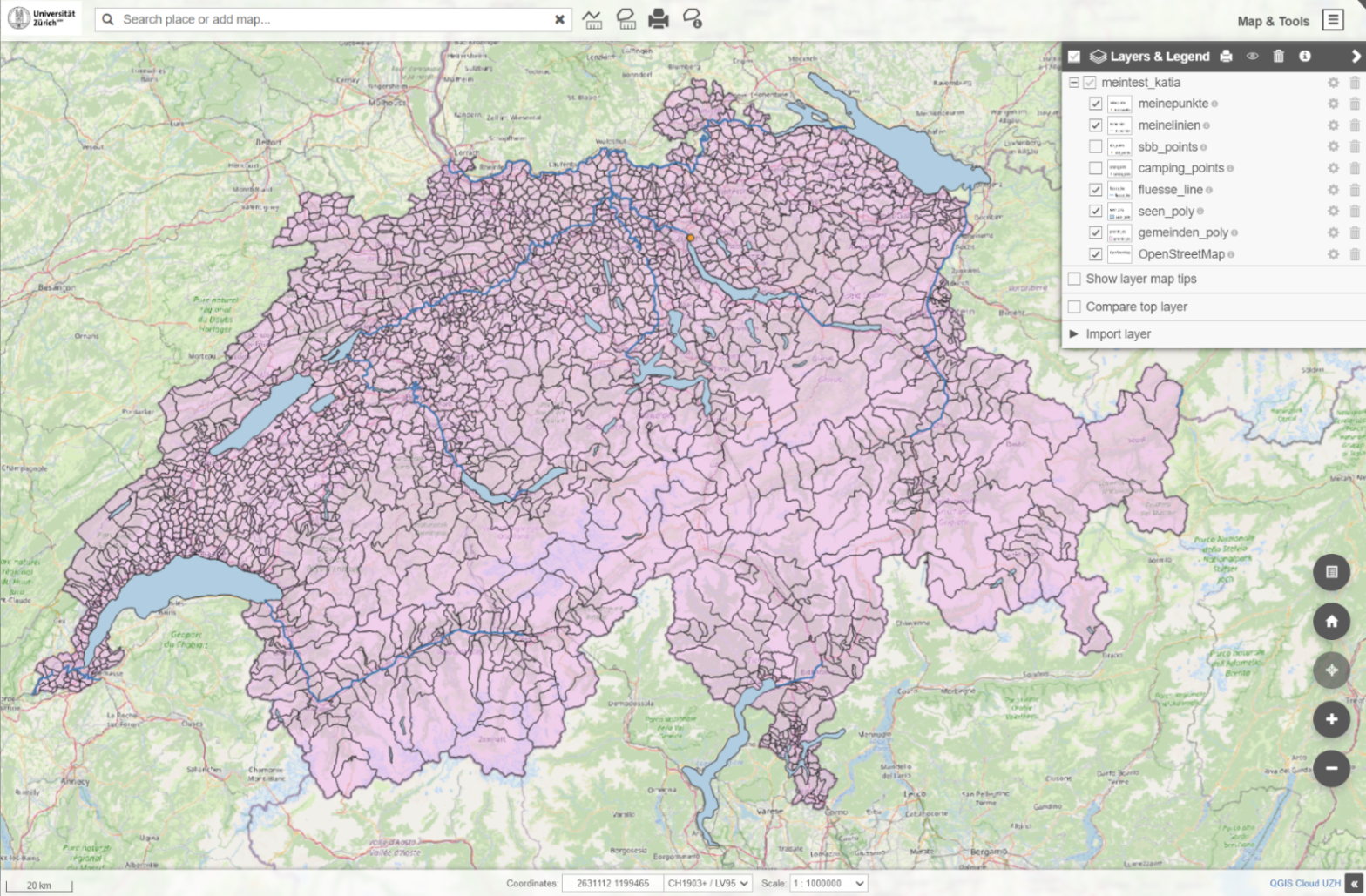
Die QGIS Cloud der UZH ist bereit! In der Cloud können Studierende und Forschende Karten und Geodaten publizieren, mit anderen teilen – oder sich von anderen inspirieren lassen. Was die QGIS Cloud alles kann und was Nutzer*innen wissen müssen, erklärt Leyla Ciragan vom DLF und GIS Hub.
Leyla, was ist die QGIS Cloud genau?
Mit derQGIS Cloudstellen wir an der UZH eine Geodaten-Infrastruktur zur Verfügung. Wer zum Beispiel eine Karte mit der QGIS Desktop Software erstellt hat, kann diese über ein Plugin online stellen und so mit anderen teilen. Auch die zur Karte gehörigen Daten lassen sich so einfach teilen und/oder in andere Projekte einbinden. Dabei kann ich die Sichtbarkeit, d.h. mit wem ich meine Daten teilen möchte, selbst steuern: nur mit meinem Forschungsteam, meinen Seminarteilnehmenden oder ganz öffentlich. Die Sichtbarkeit ist ein Beispiel dafür, wie wir die QGIS Cloud zusammen mit der Entwicklerfirma Sourcepole auf die Bedürfnisse an der UZH zugeschnitten haben.
Weshalb braucht die UZH eine QGIS Cloud?
Wir haben festgestellt, dass sich viele Personen an der UZH, die nicht aus den klassischen GIS-Disziplinen wie Geografie oder Informatik kommen, mit räumlichen Fragen befassen. Ich denke an Linguist*innen oder Sozialwissenschaftler*innen. Wir möchten diesen Personen die Möglichkeit geben, ihre Webmaps einfach und unkompliziert, d.h. ohne Programmierkenntnisse publizieren zu können. Wir möchten aber auch (fachfremde) Dozierende ansprechen, die QGIS Cloud in der Lehre zu nutzen. Zum Beispiel könnte eine Karte Teil eines Leistungsnachweises sein. Wir haben uns für die QGIS Cloud entschieden, weil QGIS als open source Lösung für alle zugänglich ist – auch wenn sie einmal nicht mehr an der UZH studieren oder forschen. Um auf die Frage zurückzukommen: Ob die UZH wirklich eine QGIS Cloud braucht, möchten wir genau mit diesem Projekt herausfinden. Besteht eine hohe Nachfrage, können wir die Kapazitäten ausbauen.
Wer kann die QGIS Cloud nutzen?
Alle an der UZH, weil der Zugang über die Switch edu-ID läuft. Mit dieser ID kann man sich einmalig für die QGIS Cloud registrieren und diese danach nutzen. Um Karten oder Daten aus der QGIS Desktop-Software heraus zu teilen, braucht es zusätzlich zur QGIS Software das QGIS Cloud Plugin.
Was muss ich bei der Nutzung der QGIS Cloud beachten?
Ganz wichtig: den Datenschutz. Ich sollte nur Daten öffentlich teilen, die auch öffentlich sind. Wenn ich zum Beispiel auf dem Open Data Portal der Stadt Zürich das Baumkataster herunterlade und die Bäume auf einer Karte anzeigen lasse, ist das unkritisch. Bei sensiblen Daten, die ich selbst erhoben oder von anderen Forscher*innen erhalten haben, muss ich genau abklären, wie ich diese Daten verwenden und veröffentlichen darf. In diesem Fall ist es sinnvoller, die Daten zum Beispiel nur innerhalb meiner Forschungsgruppe zu teilen.
Was passiert mit meinen Daten, wenn ich sie in der Cloud teile?
Es gibt keine Übersichtsseite, die mir alle hochgeladenen Daten und Karten zeigt. Die Daten werden über einen Link oder einen QR-Code geteilt, d.h. sie sind nur darüber zugänglich. Und mit wem ich meine Daten teile, kann ich steuern. Missbrauch ist theoretisch möglich, aber wenn ich mir gut überlege, mit wem ich die Daten teile, dann kann ich das Risiko dafür miniminieren. Hinzu kommt, dass jemand zwar mit meinen Daten arbeiten kann, doch die Änderungen werden nicht an meinen originalen Daten vorgenommen, sondern auf einer Kopie.
Wo finde ich eine Anleitung oder ein Tutorial?
Wir haben ganz vieleVideo-Tutorialsproduziert, die verschiedene Funktionen der QGIS Cloud Schritt für Schritt in wenigen Minuten erklären. Dazu gehören wie ich mich registrieren kann, wie ich das QGIS Plugin herunterlade, wie ich eine Karte teile und danach im Browser aufrufe etc.
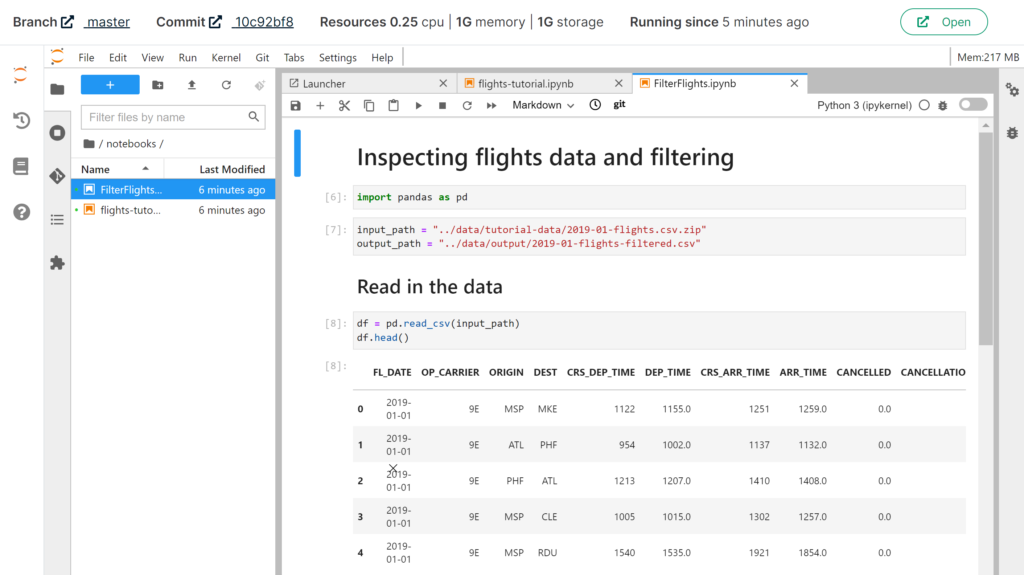
Renku wurde vom Swiss Data Science Center als Web-Plattform (Renkulab) und Terminal (Renku Client) entwickelt, um zu ermöglichen, kollaborativ Daten zu generieren, bearbeiten, speichern und zu teilen. Zudem können Code, ganze Workflows und virtuelle Maschinen verwaltet werden.
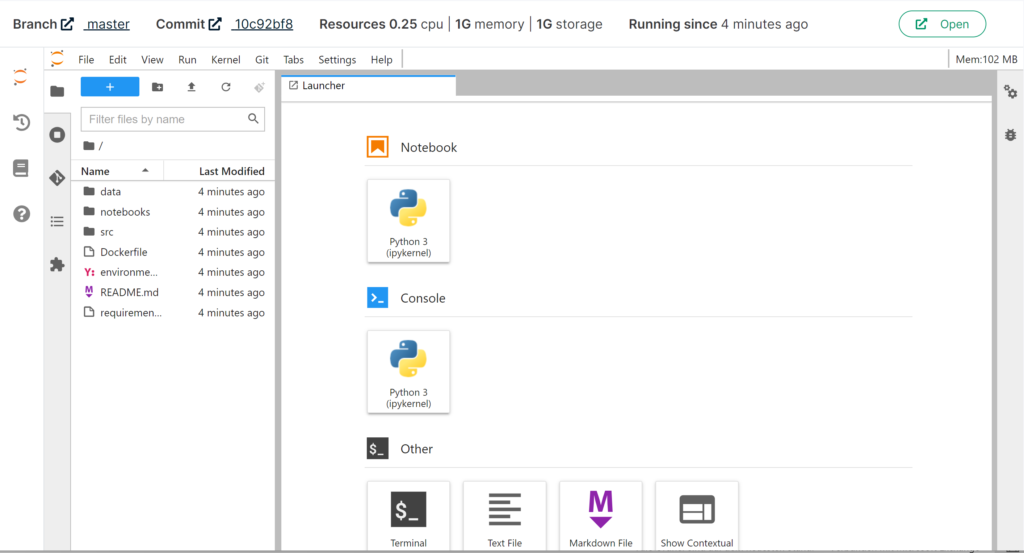
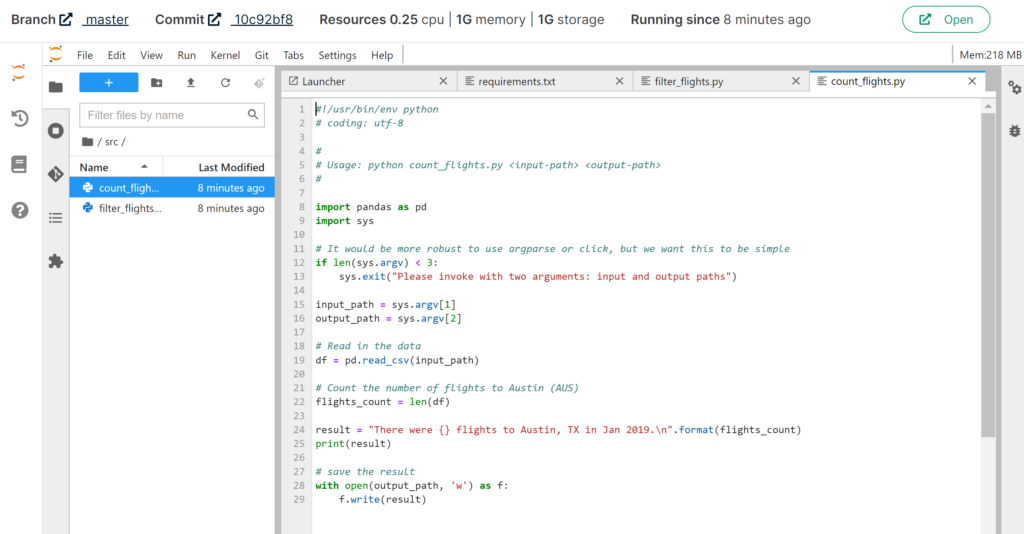
In Renkulab werden direkt im Browser Juypter Lab oder RStudio Sessions gestartet, die aus Docker Containern laufen. Notwendige Packages und Libraries werden ganz einfach über ein Requirements-File installiert. Um die Daten nachvollziehbar und sicher zu speichern, werden diese über ein integriertes GitLab verwaltet. Im Renku CLI, dem eigenen Terminal, können aber auch verschiedene renku commands verwendet werden, um Daten zu speichern, auf Gitlab zu pushen, und vieles mehr.
Für einen einfachen Anwendungsfall kann Renkulab auch von Anfänger*innen verwendet werden, die sich v.a. die mühsame Installation mehrerer Programmiersprachen und Tools ersparen möchten. Erfahrenere Anwender*innen wählen zwischen verschiedenen Programmiersprachen, arbeiten direkt mit git commands, schreiben eigene Skripts oder stellen sie in sogenannten renku-Workflows zusammen.
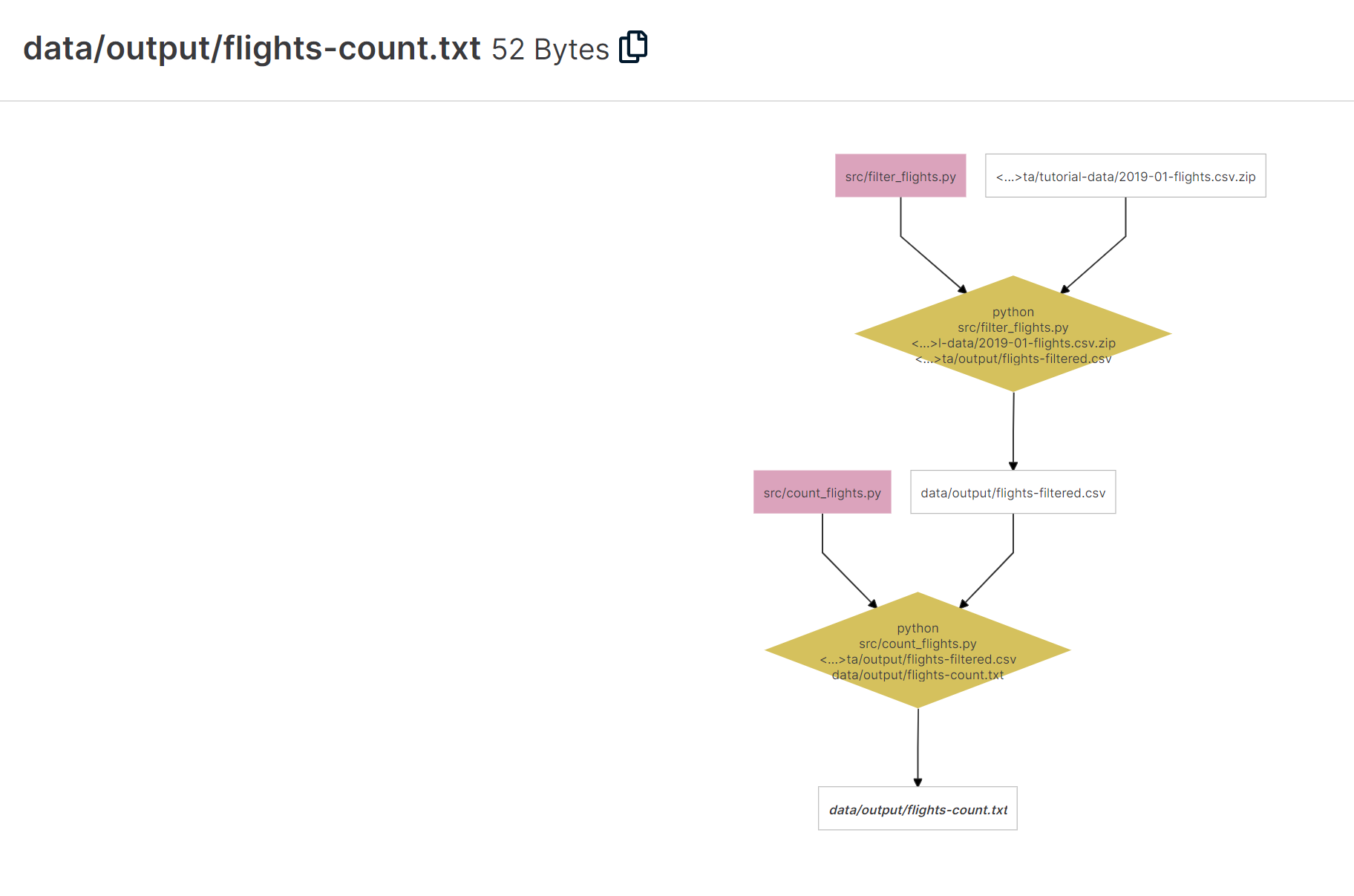
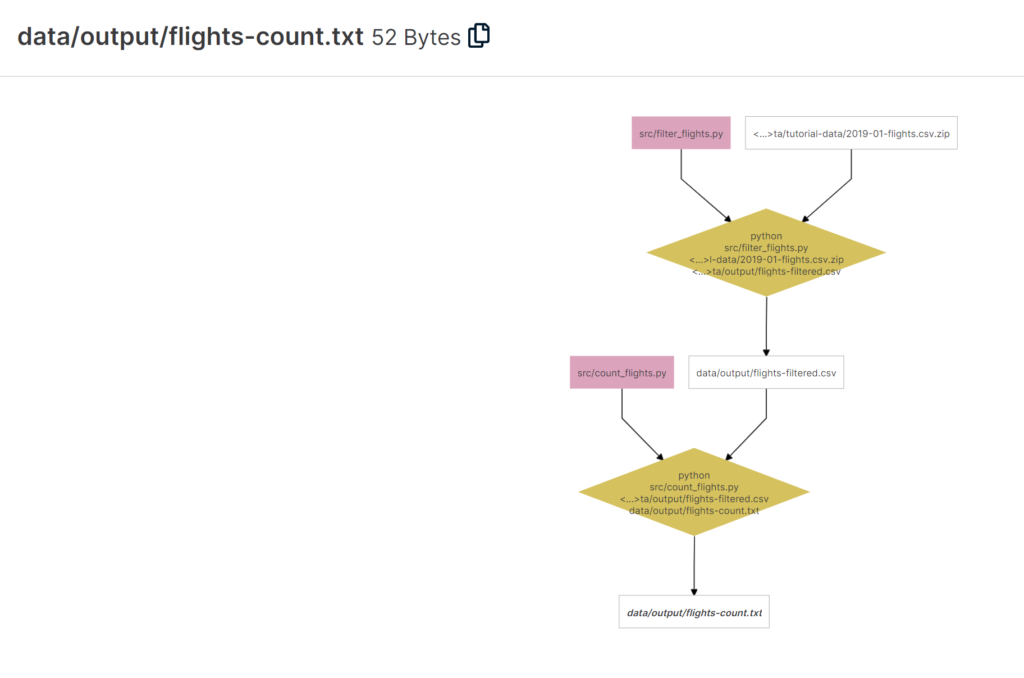
Ein grosser Vorteil von Renkulab ist ausserdem der Knowledge Graph. Was ist das und wozu dient er? Angenommen, die verwendeten Daten stammen von einer Online-Quelle, wurden in mehreren Schritten durch verschiedene Skripts bearbeitet und generieren nun den gewünschten Output. Wie oft kommt es vor, dass man nicht mehr reproduzieren kann, wie dieser Output genau entstanden ist, weil man verschiedene Ansätze ausprobiert hat? Der Knowledge Graph löst nun genau dieses Problem, indem er in einem Diagramm jeden Verarbeitungsschritt visualisiert und den Output dadurch nachvollziehbar und reproduzierbar macht.
Gerade für Einführungen in die Programmierung, Gruppenarbeiten in einem Seminar oder auch den Austausch für eine Forschungsgruppe ist Renku sehr gut geeignet.
Ein Tutorial führt Klick für Klick durch die Möglichkeiten von Renku – es lohnt sich, das auszuprobieren!
Für jede Session wird die Rechenpower und die Umgebung gewählt.Jupyter Lab läuft innerhalb eines Gitlab Accounts.Ein Jupyter Notebook ermöglicht es, schön lesbare Tutorials oder Aufgaben mit Python zu erstellen.Auch eigene Python Skripts können natürlich verwendet werden.Der Knowledge Graph visualisiert nicht nur die Datenherkunft, sondern auch die einzelnen Verarbeitungsschritte.
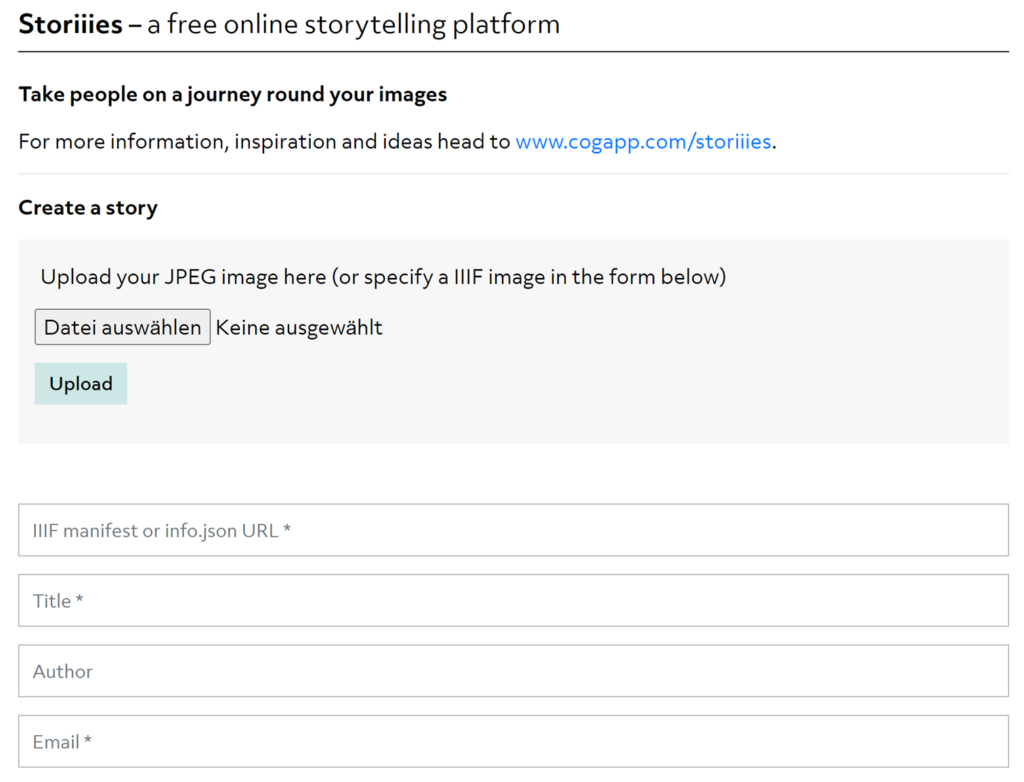
Storiiies ist eine von Cogapp entwickelte browserbasierte Applikation, die ursprünglich als Showcase für eine IIIF Konferenz entwickelt wurde, um die Möglichkeiten von IIIF und Storytelling zu zeigen.
Einzelne Showcases wurden in verschiedenen Versionen erstellt: Als einfache Webseite, die nur scrollbar ist, oder interaktiver IIIF Viewer, der Details des Bildes hervorhebt, indem er sich an eine bestimmte Stelle im Bild bewegt. Dazu wurde einfach definiert, an welche x-/y-Koordinate gesprungen werden soll und welche Dimension der Ausschnitt haben soll. In einer durchscheinenden Textbox kann die Ansicht nun kommentiert werden.
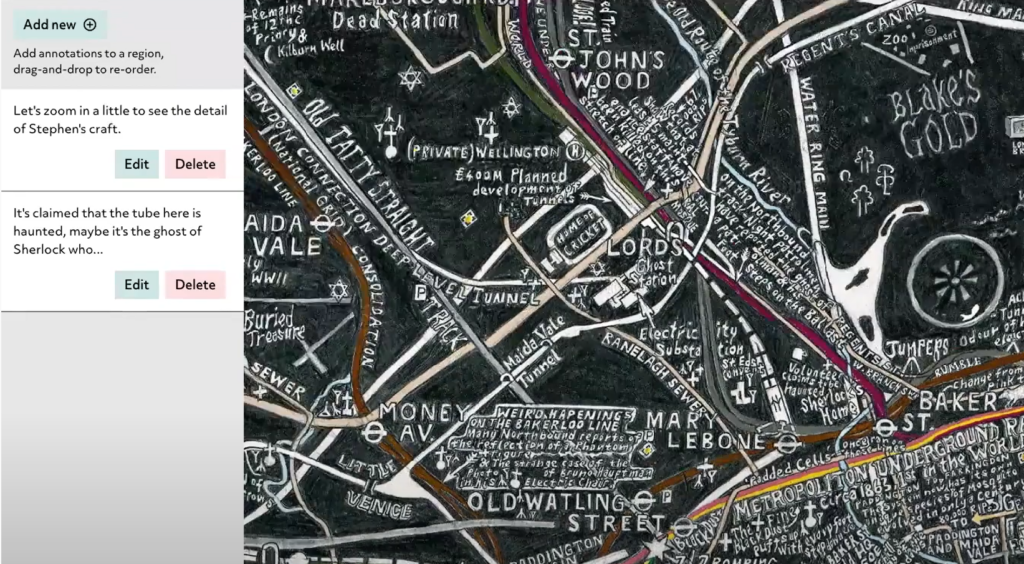
Ein Showcase, der mit Storiiies umgesetzt wurde. Quelle: Storiiies Die gleiche Story – mit Zoom auf ein Detail.
Nun ist der Storiiies Editor frei zugänglich – wobei die Anbieter weder die Weiterentwicklung noch die Aufrechterhaltung des Angebots garantieren. Dennoch könnte sich diese App eignen, um z.B. studentische Arbeiten zu präsentieren. Da die IIIF-Bilder durch den offenen Standard von überall her integrierbar sind, ist dies sehr einfach und unkompliziert möglich (vgl. dazu den Blogbeitrag Was ist IIIF?).
In einem einfachen Formular wird ein IIIF Manifest angegeben oder ein eigenes Bild hochgeladen, danach kann die Story entwickelt werden.
Mit einem Webformular ist der Einstieg sehr einfach gestaltet. Quelle: Storiiies Editor
Man bewegt sich an die gewünschte Stelle im Bild und zoomt hinein – mit «Add new» wird ganz einfach eine neue Annotation zu dieser Stelle erfasst.
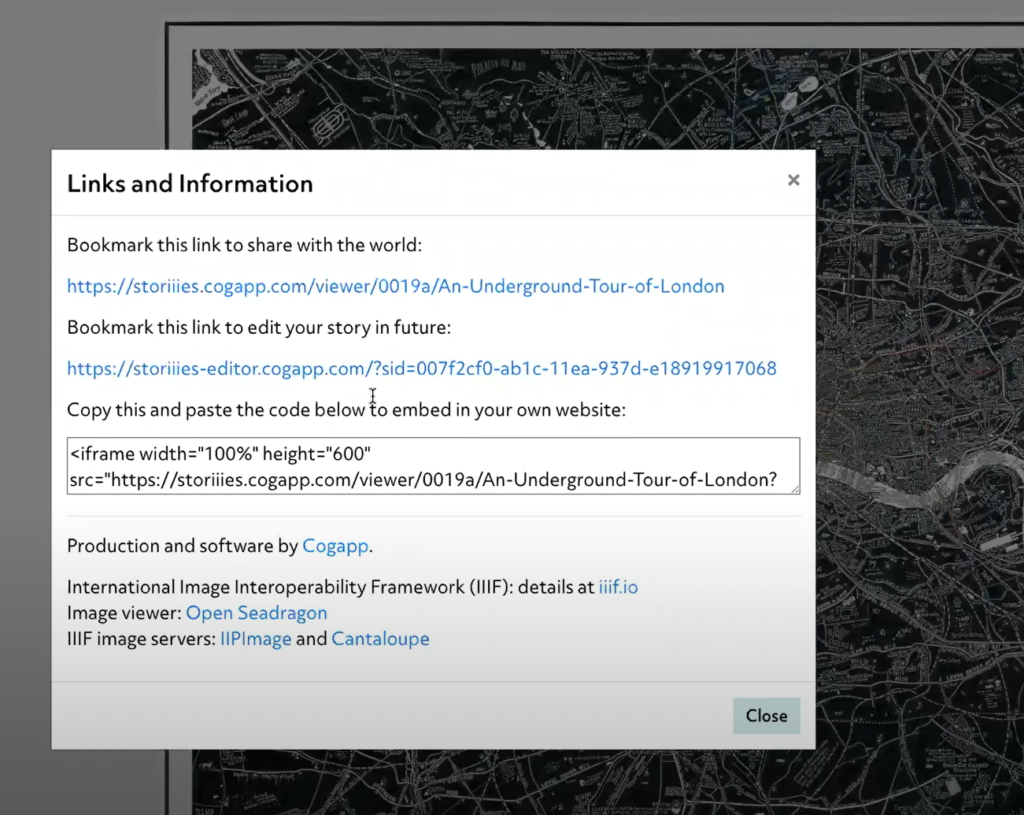
Die Story kann schliesslich über eine URL geteilt oder mit einem iframe in andere Seiten eingebettet werden..
Aus einem Tutorial von Cogapp. Quelle: ebd.
Im Hintergrund wird ein JSON-Manifest erstellt, dem eine Annotationsliste beigefügt ist, ebenfalls als JSON. Die URL im Manifest kann wiederum in einem anderen IIIF-Viewer aufgerufen werden, z.B. Mirador – das Bild mit den Annotationen kann mit jedem IIIF Viewer angesehen werden.
Das JSON Manifest, das durch den Editor generiert wurde. Quelle: ebd.
Systemvoraussetzungen: Keine, da browserbasiert. Funktioniert auf jedem Browser.
Vorausgesetzte Kenntnisse: Keine. Die Oberfläche ist intuitiv und auch für Einsteiger geeignet. Will man genauer wissen, wie dieManifests aufgebaut sind, sollte man sich ein wenig mit JSON auskennen.
Das International Image Interoperability Framework wurde von einem Konsortium entwickelt, um hochauflösenden und zoombaren Digitalisate mit einheitlichen Metadaten zu versehen und so frei zugänglich zu machen. Über die offene API werden Digitalisate nicht mehr in lokalen Applikationen gezeigt, sondern «barrierefrei» geteilt.
Wie funktioniert das genau? Wird ein Digitalisat von einer Institution kuratiert, d.h. zunächst hochauflösend digitalisiert, im Internet auf speziellen Bildservern bereitgestellt und mit den korrekten Metadaten erfasst, bekommt dieses Digitalisat (ein sogenanntes IIIF Manifest) eine URI (Unified Resource Identifier), die immer mit einer JSON Datei endet, dem manifest.json dieses spezifischen Digitalisats.
Diese URL kann nun mit einem IIIF Viewer auf dem eigenen Computer aufgerufen werden, und schon kann man sich ein hochaufgelöstes Dokument ansehen oder auch annotieren.
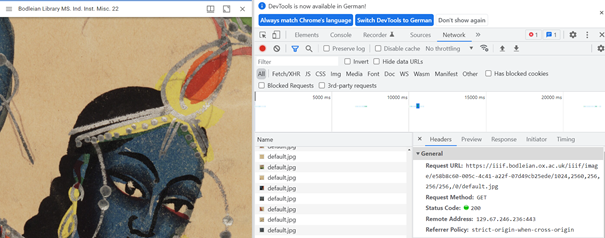
Das besondere dieser Bildserver ist, dass nicht mehr – wie sonst üblich – das ganze Bild auf einmal heruntergeladen wird, sondern immer nur der Ausschnitt, den die User sich gerade ansehen. Bei jeder Aktivität der User wird ein Teil des Bildes aufgerufen und mit der URL wird gleich der Ort des Ausschnitts, die Rotation und die Qualität des Bildausschnitts mitgegeben:
Figure 1: Verschiedene Bildausschnitte und dazugehörige Parameter in der URL. Quelle: https://iiif.io/api/image/3.0/
Figure 2: In der Request URL sieht man die Quelle und alle oben erwähnten Parameter – ich habe lediglich im Mirador Viewer in das Bild hineingezoomt.
DLF bietet in AdFontes sogar einen eigenen IIIF Viewer als Baustein an, um Digitalisate in die eigenen Kurse einbinden zu können – dies allerdings in der API Version 2.
Figure 3: Ausschnitt aus einem Baustein in AdFontes, https://www.adfontes.uzh.ch/382110/training/old-maps/map-pictures
Voyant Tools ist eine browserbasierte open-source Umgebung für die Textanalyse und -visualisierung. Es wurde hauptsächlich konzipiert, um „leichtgewichtige“ Textanalysen schnell und unkompliziert anzubieten, v.a. Worthäufigkeiten, Beziehungen uvm.
Ein hochgeladener Text kann mit unzähligen Methoden des Natural Language Processings (NLP) ausgewertet und visualisiert werden, z.B. mit
Wortwolken oder Worttrauben
Begriffhäufigkeiten
Beziehungsgraphen
Korrelationen
Kontexten
Trends
Bubblelines
uvm.
Fünf Blöcke können auf der Seite frei konfiguriert werden. Dabei wird für jeden Block gewählt, welche Methode bzw. welche Visualisierung dargestellt werden soll. So kann man sich schnell und unkompliziert eine Auswahl zusammenstellen.
Die Visualisierungen werden anschliessend einfach exportiert – als Bild oder HTML snippet, um sie in bestehende Webseiten einbetten zu können
Systemvoraussetzungen: Keine, da browserbasiert. Funktioniert auf jedem Browser.
Vorausgesetzte Kenntnisse: Keine. Die Oberfläche ist intuitiv und auch für Einsteiger geeignet. Will man genauer wissen, wie die Visualisierungen entstehen, sollte man sich ein wenig in NLP auskennen.
Wussten Sie schon, dass DLF eine eigene Pressbooks/Openbooks-Plattform hostet? Seit diesem Jahr gibt es auch ein für die UZH gestaltetes Template, das «UZH Book Theme», das die UZH-eigenen Farben aufgreift.
Pressbooks ist eine Plattform aus der Open-Education-Bewegung und bietet seit 2011 eine Plattform für die Publikation von E-Books an.
Über eine WordPress-ähnliche Plattform können E-Books ganz einfach generiert und mit verschiedenen Themes gestaltet und publiziert werden.
Wenn Sie daran interessiert sind, eine E-Publikation für sich oder auch für die Leistungsnachweise Ihrer Studierenden zu verwenden, lesen Sie unsere Anleitung dazu – erstellt in einem eigenen Pressbook: Erste Schritte in Openbooks.
Wie könnte ich ein Serious Game ohne Programmierkenntnisse umsetzen? Mit Actionbound lassen sich ganz einfach digitale Schnitzeljagden umsetzen. Diese eignen sich ganz besonders, um Inhalte als Serious Games zu vermitteln.
Was ist eine digitale Schnitzeljagd?
Wer möchte auf den Spuren von Robert Walser Zürich entdecken und Neues lernen? Oder historische Bauten finden und mehr dazu erfahren?
Auf einer Schnitzeljagd folgt man im «echten» Gelände Hinweisen, löst Rätsel, liest Informationen, beantwortet Quizzes, und vieles mehr. So bewegt man sich durch eine Stadt, eine Landschaft und lernt Neues zu einem Thema, ohne es wirklich zu merken.
Am Kindergeburtstag vor vielen Jahrzehnten legte man noch mühsam Fährten und zeichnete Karten oder Skizzen zur Vorbereitung – heute ist dies mit PC oder mobilen Apps anders geworden: Einfach, unglaublich schnell und für viel mehr Leute verfügbar: Die Schnitzeljagd wird am Computer konzipiert, dann mit einer App, plattformunabhängig, gespielt.
Braucht es dafür Programmierkenntnisse? Nein.
Nein – Actionbound bietet die Möglichkeit, digitale Schnitzeljagden ohne Programmierkenntnisse aufzubereiten. Die Firma, die Actionbound seit 2012 immer weiter entwickelt, hat für ihre App und die dazugehörige Webseite schon einige Preise abgeholt: eLearning Award, Pädagogischer Medienpreis, ….
Mit einer kostenlosen Privat-Lizenz, lassen sich Schnitzeljagden, sogenannte «Bounds», erstellen und veröffentlichen. Will man mehr Funktionen nutzen, z.B. Accounts verwalten, Medien herunterladen etc., muss man auf eine kostenpflichtige Edu- oder Pro-Lizenz umsteigen.
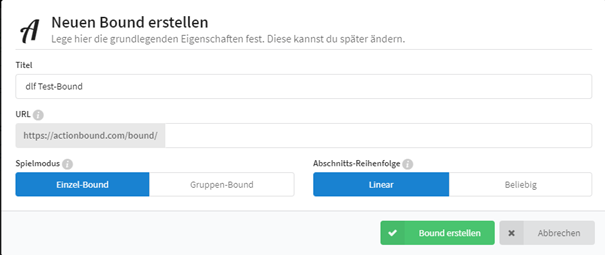
Auf der Webseite muss nur ein Account erstellt werden, dann kann man im «Bound-Creator», der Webseite, eine neue Schnitzeljagd anlegen.
Auf Knopfdruck wird eine neue Schnitzeljagd angelegt.
Man wählt einen Titel, eine URL und den Spielmodus sowie eine Abschnittsreihenfolge.
Welche Optionen hat Actionbound?
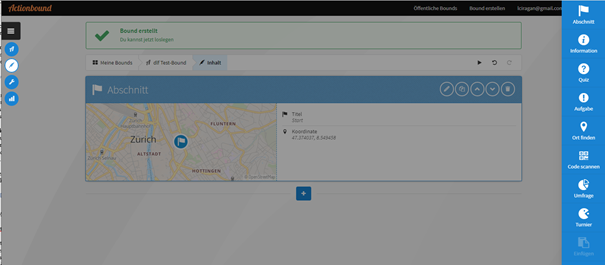
Ist der Bound angelegt, kann man über eine grafische Ansicht einfach Abschnitte hinzufügen oder bestimmte Tasks, wie:
Informationen
Quizzes
Aufgaben
Orte finden
Einen Code scannen
Umfrage erstellen
Turnier durchführen
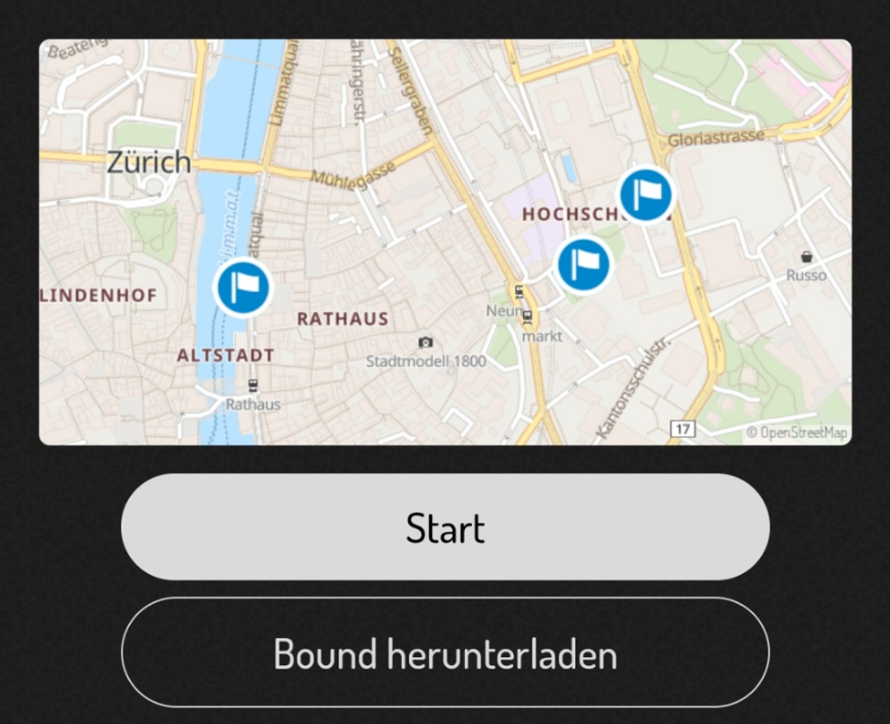
Hier wurde ein Start-Abschnitt hinzugefügt und auf einer Karte der Standort von DLF ausgewählt.
So wird eine digitale Schnitzeljagd nach Belieben zusammengestellt, je nachdem, welchen Inhalt man vermitteln will:
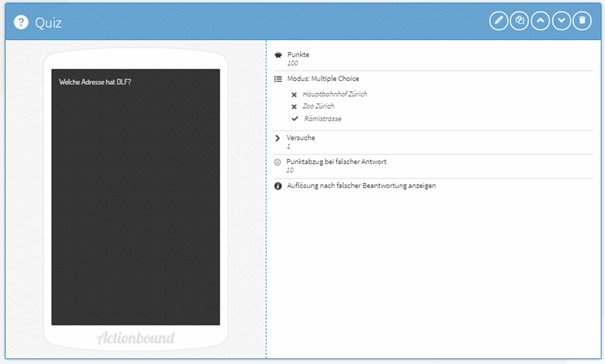
Als Beispiel nach dem Start-Abschnitt habe ich eine einfache Multiple Choice Frage aus der Option „Quiz“ gewählt.
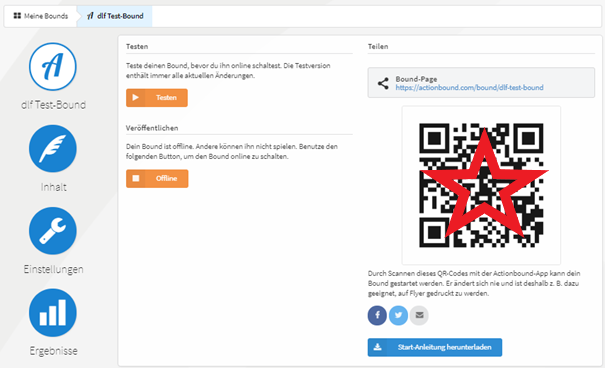
Zum Schluss sollte der Bound ausführlich getestet werden. Dazu wird der QR Code mit der Actionbound-App gescannt (Achtung: Der Test-Code ändert sich noch!), und schon sieht man seinen Bound und kann ihn starten.
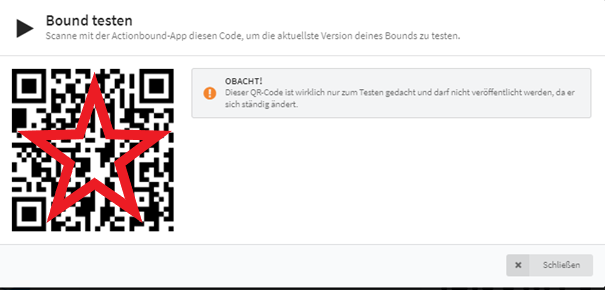
Um zum Test-Modus zu gelangen, wählt man in der linken Navigation das Icon mit A und klickt auf „Testen“.
Im folgenden Fenster erscheint ein QR Code, den man mit der App scannt. Achtung: Dieser Code ändert sich noch und sollte nicht publiziert werden.
In der App öffnet sich mit dem Scannen der Start-Bildschirm des Test-Bounds.
Mit der Veröffentlichung des Bounds per Knopfdruck wird ein QR Code generiert, der sich nicht mehr ändert und damit auch publizierbar ist (z.B. auf einem Flyer, Webseiten etc.). So kann man sein Spiel ganz einfach teilen.
Digitale Schnitzeljagd als alternativer Leistungsnachweis
Vielleicht haben Sie schon den Beitrag zur Serious Games Entwicklung mit Triadic Game Design gelesen? Zusammen mit der konkreten Umsetzung als digitale Schnitzeljagd ergäbe dies einen lohnenswerten alternativen Leistungsnachweis.
«Wo ging Robert Walser spazieren und in welchen Texten werden diese Orte erwähnt?» Dies ist nur eine der unendlich vielen möglichen Fragen, die in der Schnitzeljagd beantwortet werden könnten. Bleibt auch hier nur noch, viel Spass zu wünschen!
„Gamification“, „Game Design“ – was ist der Unterschied? Und wie kann ich vorgehen, wenn ich ein Serious Game entwickeln will? Dieser Beitrag erklärt die aktuellen Begriffe und zeigt an der Methode des Triadic Game Design, wie leicht und schnell sich auch in der Lehre ein Serious Game entwickeln lässt. Es muss ja nicht gleich programmiert werden – Papier und Bleistift tun es auch.
Gamification
Gamification wurde längere Zeit gleichbedeutend neben Game Design verwendet, bedeutet aber eigentlich lediglich, dass „spieltypische Elemente“ in andere Kontexte, z.B. in das Lernen von Fachinhalten übertragen werden. Häufig geht es dabei darum, verschiedene kompetitive Elemente einzuführen – Leaderbords, Minigames, etc.
Gerade der kompetitive Aspekt funktioniert jedoch nicht für alle Leute gleichermassen. Sollen Spiele uns beim Lernen helfen, müssen sie uns engagieren – etwas dadurch, dass sie unsere Neugier oder bestimmte Emotionen wecken.
(Serious) Game Design
Wie kann man nun die Neugier oder eine positive Emotion im Bereich Serious Game wecken? Lernen ruft nicht für alle Personen die Assoziation von „Spass“, „Fun“ hervor. Hier kommt nun das „Game Design“ als Begriff ins Spiel. Game Design heisst dann, dass wir von Grund auf konstruieren, welche Inhalte in welcher Form vermittelt werden können.
Statt also dem klassischen Lerninhalt einige wenige spielerische Elemente aufzubürden, sollte er also ganz neu konzipiert werden, um als Game funktionieren zu können. Mit dem richtigen Storytelling wird es möglich, die Spielenden mit dem Inhalt emotional zu verbinden – erst jetzt bekommt das Hirn auch eine Chance, das Gelernte im Langzeitgedächtnis zu behalten (Krickel 2021).
Erinnert ein wenig an neuere Erkenntnisse aus dem Blended Learning und der Hochschuldidaktik, nicht?
Triadic Game Design
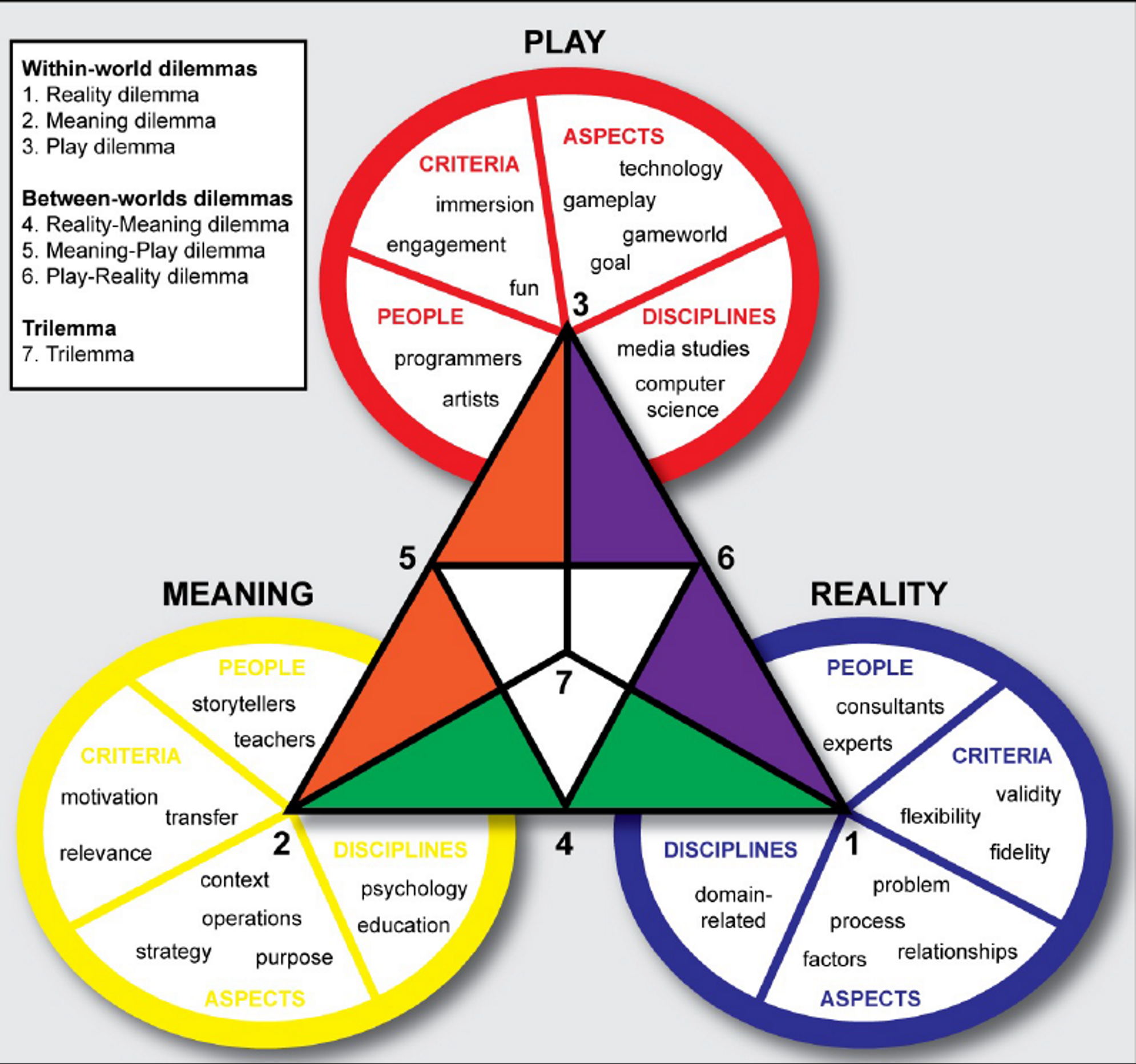
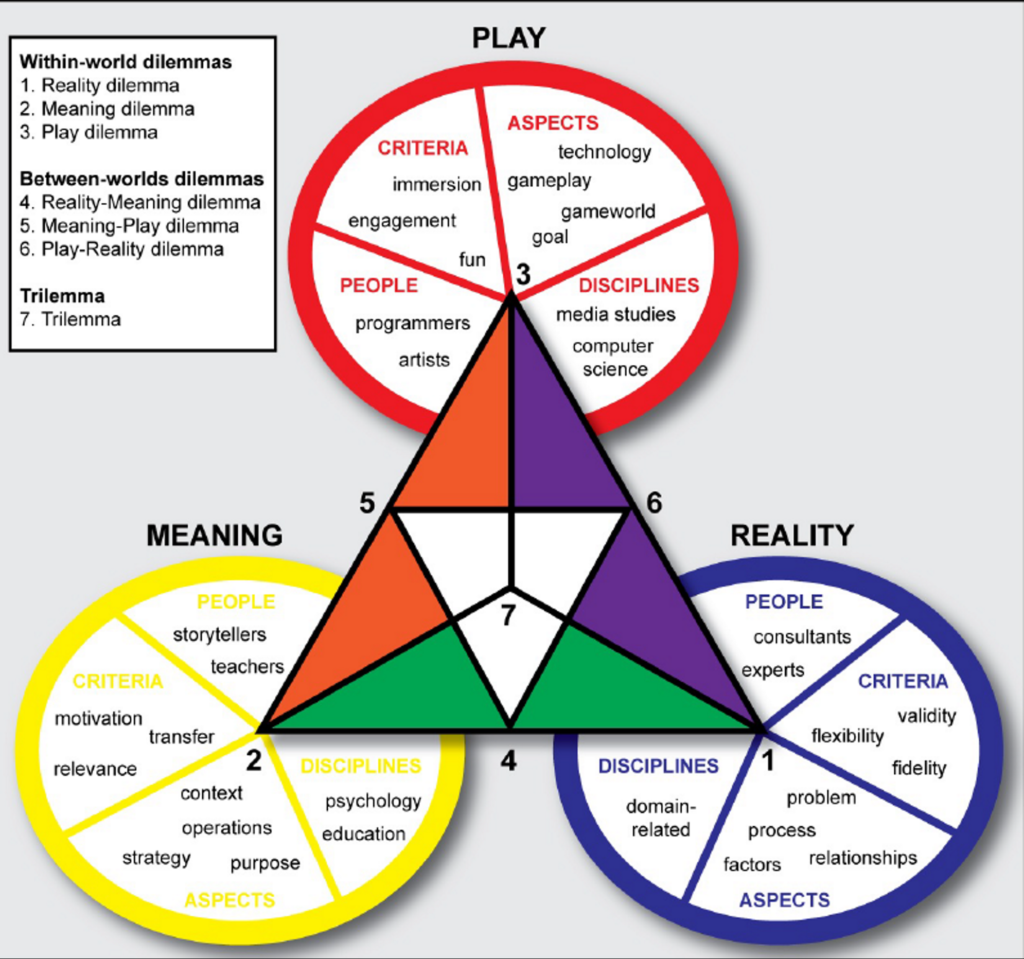
Eine aktuelle Methodik, wie sich leicht, verständlich und auch sehr schnell Prototypen für Serious Games entwickeln lassen, ist das Triadic Game Design, entwickelt von Casper Harteveld (Harteveld 2011).
Der Autor stellt Arbeitsblätter für einen halbtägigen Workshop zur Verfügung, mit denen man sich verschiedenen Leitfragen in den drei Bereichen Reality, Meaning und Play entlang hangelt. Daraus entsteht zum Schluss ein erster Prototyp für ein Spiel – das kann ganz Old School auf Papier sein, oder gebastelt mit allem, was gerade herumliegt. Eine spätere Programmierung des Prototyps ist in keiner Weise ausgeschlossen – das schnelle Prototyping (fast prototyping) hilft jedoch, sehr früh Mängel und Logikfehler zu entdecken und auszubessern.
Abbildung 1: Design Space des Triadic Game Design (Hartefeld 2011).
World of Reality
In der Welt der Realität wird der Frage nachgegangen, welches konkrete Problem aus der realen Welt im Game behandelt werden soll. Eine Situation ist in einem konkreten Zustand und soll von diesem in einen anderen Zustand übergehen – es könnte z.B. sein: „Werther ist unglücklich verliebt, was soll er tun?“.
Das Problem soll möglichst präzise formuliert und eingegrenzt werden. Ebenso sollte man sich überlegen, zu welcher „Domain“ das Problem gehört – geht es in der obigen Frage darum, etwas über Literatur zu lernen oder ist es ein Problem der Gesundheitsvorsorge? Daraus ergeben sich gänzlich unterschiedliche Möglichkeiten.
Ist das Problem genauer umrissen, listet man alle Faktoren auf, die dabei eine Rolle spielen: Wer oder was ist involviert, was sind kritische Faktoren, was eher „Beigemüse“? Die Faktoren haben schliesslich auch Beziehungen zueinander – es lohnt sich, eine Mind Map oder einen Graphen zu zeichnen, um zu sehen, wer oder was wen oder was beeinflusst. Zuletzt muss sich eine Game Entwicklerin überlegen, wie und aus welchen Gründen von einem Zustand in einen anderen gewechselt wird – ein Modell ist nie nur statisch, sondern veränderlich. Ziel jedes Spiels ist es ja, von Zug zu Zug in andere Zustände zu gelangen. Deshalb muss man sich hier die Prozesse überlegen: Wie verändern sich die Faktoren über die Zeit hinweg und was passiert überhaupt wann?
Die Welt der Bedeutung behandelt nun den Zweck des Games (liebe Semiotiker:innen: ich weiss…): Worum geht es überhaupt im Game? Soll man ein Thema explorieren, wird Kenntnis überprüft, sollen die Spieler:innen ihre Haltung verändern oder werden Daten gesammelt? All diese verschiedenen Zwecke führen in der Welt des Spiels dann zu anderen Spielentscheidungen. Hier wird definiert, welche Strategie verfolgt werden muss, um das Ziel zu erreichen und welche konkreten Handlungen vorgenommen werden müssen.
Erst in diesem dritten und letzten Schritt wird entschieden, was die eigentlichen Ziele im Spiel sind. D.h. geht es darum, Werther zu retten oder geht es darum, das Buch kennenzulernen? Wie wissen die Spieler:innen, dass das Ziel erreicht ist und das Spiel beendet ist? Nun wird auch ein Genre gewählt, die Spielregeln entwickelt. Ein Core Game Loop zeigt auf, wie ein Zug initiiert wird und wann er beendet ist: z.B. würfeln, Figur ziehen, Aufgabe lösen, Punkte eintragen – > neuer Zug. Welche Challenges sollen Spieler:innen überhaupt überwinden. Wie soll das Spiel aussehen, was ist die Story.
In diesem Schritt kommen alle Element aus den vergangenen beiden Welten zusammen, das konkrete Spiel wird entwickelt.
Einen prähistorischen Verhüttungsofen 3D drucken, Gelände abtasten und rekonstruieren – die prähistorische Archäologie arbeitet mit einer Vielzahl an digitalen Methoden. Philippe Della Casa – Professor an der Philosophischen Fakultät gibt uns einen Einblick.
Ich freue mich, dass wir heute über ein ganz spezielles Fachgebiet an der Philosophischen Fakultät sprechen können – Herr Della Casa, bitte stellen Sie sich kurz vor!
Mein Name ist Philippe Della Casa, ich bin Professor für Prähistorische Archäologie an der Philosophischen Fakultät der UZH – ehemals wurde das Fach Ur- und Frühgeschichte genannt. Meine Interessensgebiete liegen in erster Linie in der Vorgeschichte Europas, aber auch im interkontinentalen komparativen Bereich, wenn es z.B. um den Vergleich prähistorischer Gesellschaften geht, die in ähnlichen Rahmenbedingen in unterschiedlichen Gebieten lebten. Speziell interessieren mich hier als Schwerpunkt Berggesellschaften – in Englisch Mountain Archeology -; bei uns sind das spezifisch die Berggesellschaften in den Alpen. Wir haben aber auch Kooperationen und Projekte in anderen Bergregionen, z.B. in Bhutan, im Himalaya, auch viele Kontakte in die Pyrenäen, Karpaten oder in die Rocky Mountains und nach Feuerland.
Daneben definiere ich mich in erster Linie als Wirtschafts- und Gesellschaftsarchäologe, dabei liegt mein Schwerpunkt in der Siedlungs- und Landschaftsforschung und in der Art, wie Menschen mit ihrer Umwelt interagieren, welche gesellschaftliche Konstrukte vorhanden sind.
Könnten Sie für uns Laien kurz den Zeithorizont umreissen, in dem sich diese Forschung bewegt?
Meine Schwerpunktgebiete in Europa sind die sogenannten Metallzeiten, das ist ungefähr das 4. bis 1. Jahrtausend vor Christus – man könnte es auch so sagen: «Ötzi»-Zeit bis zum Ende der Eisenzeit, der keltischen Periode, d.h. bis zur Eroberung Galliens durch die Julius Caesar ca. 50 v.Chr.
Was für Berggesellschaften hat es in dieser Zeit in den Alpen? Ich kann mir gar nicht vorstellen, dass man da überleben konnte…
Das sind frühe alpine Bevölkerungen, die sich speziell auf die alpinen Rahmenbedingungen «eingelassen» haben und in diesem Umfeld auch wirtschaftlich interagierten. Diese Rahmenbedingungen sind z.B. die Steilheit des Geländes, eine starke Höhengliederung, klimatische Exposition, beschränkte Ressourcen, insgesamt Unsicherheiten und lange dauernde Winter.
Rahmenbedingungen wie für die heutigen Bergbauern…
Genau, in jener Zeit fing es etwa an, dass es erste dauerhafte Siedlungen in den Berggebieten gab. In den «Alpenfeldzügen» wurden dann die letzten aufmüpfigen Bergvölker durch Augustus besiegt und ins römische Reich integriert.
Welche digitale Methoden setzen Sie in der Prähistorischen Archäologie ein?
Es gibt ganz viele Anwendungsgebiete – ich werde heute drei Gebiete vorstellen:
Ein klassisches Anwendungsgebiet mit digitalen Methoden sind die «nicht-invasiven Prospektionen». Das können geophysikalische Prospektionen sein, die auf der Bodenoberfläche stattfinden. Dabei werden mit speziellen Geräten Widerstände gemessen, die ein Abbild unter dem Boden ergeben. Es können Strukturen erkannt, Dichteunterschiede gemessen werden uvm.
Es gibt aber auch luftbild- oder sogar satellitengestützte Prospektionen – hier ist man dann im Bereich des «Remote Sensing». Das bedeutet konkret, aus der Entfernung Oberflächen abzutasten: Das Erdinnere wird dabei nicht untersucht. Über die Oberflächenzeichnung kann man z.B. Grabhügel oder alte Wallanlagen entdecken. Häufig manifestieren sich über die Oberflächen jedoch auch Strukturen darunter. Ein gutes Beispiel sind Luftbilder von Kornfeldern: Hier kann man Strukturen erkennen, wie z.B. eine Mauer unter dem Boden, die bedingen, dass das Korn unterschiedlich wächst. Bildgebende Verfahren können diese Strukturen dann darstellen.
Digitales Geländemodell von Ramosch-Motta GR nach Drohnenflug (T. Sonnemann, U-Bamberg).
Was für Daten bekommt man aus diesen Methoden zurück, Zahlen, oder andere Formate?
Ganz unterschiedlich natürlich, je nach Methoden. In unserem zweiten grossen Anwendungsgebiet, GIS (Geographic Information System), arbeiten wir mit herkömmlichen Datenformaten für Geodaten, die wir dann in ein GIS importieren können. So können wir die erhaltenen Daten als zusätzliche Layers auf Karten darstellen und analysieren.
Wir verwenden hier am Institut eine kostenpflichtige Software eines bekannten Herstellers, vermehrt und insbesondere die Studierenden aber auch Open Source Software – GRASS GIS und QGIS.
Teilweise importieren wir die eigenen Daten in das GIS und erstellen neue Karten, manchmal haben wir auch nur eine «physische» Karte und georeferenzieren diese dann im GIS manuell.
In der Disziplin gab es einen fliessenden Übergang, was den Einsatz digitaler Methoden angeht – in meinen ersten landschaftsarchäologischen Arbeiten habe ich Fundpunkte noch von Hand in physische Karten eingetragen, mittlerweile macht man das automatisiert vor Ort. Man sieht hier schön den Übergang von analogen zu digitalen Humanities.
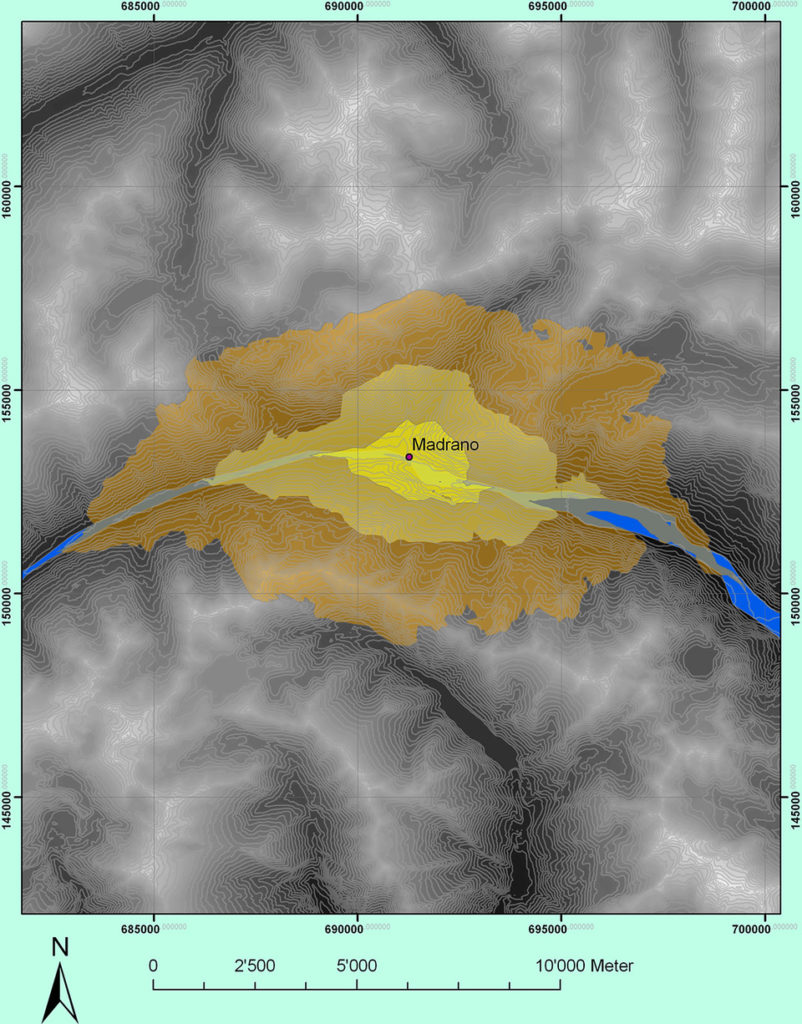
Umlandmodellierung in GIS mit 15-/60-/180-Minuten-Gehdistanz um Airolo-Madrano TI (M. Sauerbier ETHZ, Ph. Della Casa UZH).
Für QGIS gibt es auch eine mobile App, mit der man Standorte georeferenzieren kann – wird diese auch eingesetzt?
Genau, das hat in den letzten Jahren angefangen und wird die Zukunft sein: Im Feld wird nicht mehr mit Papierdokumentation gearbeitet, sondern direkt mit dem Tablet. Die erfassten Daten können sofort im GIS integriert werden. Dies ist vielleicht nicht wahnsinnig spektakulär, erspart aber sehr viele Zwischenschritte.
Was ist das dritte Anwendungsgebiet?
Ein drittes grosses Anwendungsgebiet sind 3D-Graphikrekonstruktionen: Modellierungen im 3D-Raum. Wir arbeiten z.B. mit Structure from Motion (SfM), einer photogrammetrischen Dokumentationstechnik. Man macht viele Fotografien einer archäologischen Fundstelle. Die Fotografien enthalten referenzierte Punkte, was erlaubt, mit einer speziellen Software ein 3D-Modell zu erstellen. Dieses Modell kann man entweder auf dem Bildschirm darstellen und manipulieren (drehen, zoomen, etc.), oder man kann es sogar mit dem 3D Drucker ausdrucken.
Für die Scientifica 2017 haben wir beispielsweise ein 3D Modell eines prähistorischen Ofens aus Daten eines Fundortes erstellt. Es handelte sich um einen Kupferverhüttungsofen aus dem 1. Jahrtausend im Bündner Alpenraum. Diesen haben wir ausgegraben, dokumentiert und mit SfM photogrammetrisch modelliert. Aus dem photogrammetrischen Modell konnten wir anschliessend mit dem 3D Drucker einen Miniatur-Verhüttungsofen drucken, mit dem man den Besuchern der Scientifica die Verwendung demonstrieren konnte.
DfM-Modell eines Verhüttungsofens aus dem 3D-Drucker (Ph. Della Casa UZH).
Wie steigt man als Anfänger*in in diese Methoden ein – gerade bei der Bildverarbeitung passiert mathematisch ja einiges…
Die Archäologie ist ein gutes Beispiel für diese Problematik. Wir sind traditionell ein geisteswissenschaftliches Fach und bringen wenig mathematische Kenntnisse mit. Wir zeigen in einführenden Modulen Beispiele dieser Methoden, Anwendungen, gehen aber noch nicht auf den mathematischen Hintergrund ein. Dann bieten wir ganz vereinzelt Module wie «Computer Applications in Archeology» an, in dem dann tatsächlich die Aufgabenstellung und die instrumentellen Methoden angeschaut werden, bis zu einem gewissen Punkt auch die Algorithmen.
Aber: Die wenigsten schaffen dann den Schritt dazu, Algorithmen selber zu entwerfen, sondern bleiben Anwender z.B. der SfM-Software. Wir brauchen dann Partner an anderen Instituten, z.B. beim Institut für Geodäsie und Photogrammetrie an der ETH, die uns im konkreten Fall mit der Mathematik helfen können.
Selbst wenn wir digitale Grundlagen im Fach unterrichten wollten, könnten wir gar nicht, weil die Ressourcen für das Lehrpersonal nicht da sind. Wir ziehen manchmal ExpertInnen im Bereich «Digital Archeology» bei, doch das ist ja nur ein Beispiel von sehr vielen interdisziplinären Methoden. Gerade für aDNA- und Isotopenanalyse, Materialanalytik und sehr vielen weiteren Methoden, die in den letzten 20 Jahren entstanden sind, müssten wir SpezialistInnen haben. Die Methoden finden allenfalls Eingang in die disziplinären Projekte – bei der Lehre stehen wir vor der grossen Herausforderung, was davon aufgenommen werden soll und kann.
Beim Thema GIS wären Spezialistinnen und GIS-Module am Geographischen Institut vorhanden – doch diese sind oft komplett (aus)gebucht, so dass unsere Studierenden dort nicht andocken können. Dazu kommt, dass sie in der Anwendung in eine andere Richtung gehen, als wir in unserem geisteswissenschaftlichen Fach benötigen.
Wie haben Sie sich die digitalen Methoden erarbeitet, wie sind Sie dazu gekommen?
Ganz klar aus meinem Interesse auch für die Naturwissenschaften, der Science Archeology und natürlich durch die Entwicklung der letzten Jahre. Es ergeben sich Möglichkeiten, die man vorher mit den analogen Methoden nicht hatte.
In den Bereich Prospektion sind wir notgedrungen geraten: Grabungen auf dem Feld sind sehr aufwendig und ressourcenintensiv. Man produziert sehr viel Material, das gelagert, dokumentiert und konserviert werden muss, es ist auch administrativ sehr aufwendig, wenn es z.B. um Bewilligungen geht. Die Prospektion dagegen liefert sehr viele Resultate, ist aber viel weniger ressourcenintensiv. Man erhält zwar auch viele Daten, kontrolliert vor Ort aber nur noch fallweise, nicht mehr auf grösseren Flächen.
Mit dem Kanton Graubünden haben wir eine sehr gute Kooperation – doch dort können wir z.Z. keine Siedlungsgrabungen, d.h. Forschungsgrabungen in Siedlungen machen. Aufgrund der Bauaktivitäten gibt es bereits sehr viele Notgrabungen, ausserdem noch sehr viel unbearbeitetes Altmaterial. Prospektionen dagegen dürfen wir machen, die Funddaten liefern wir in die Fundstellendatenbanken des Kantons. Dies ist gut für den Kanton, weil sie dann wiederum ihre archäologischen Zonenkarten präzisieren können, um Verdachtsflächen zu ermitteln. Dadurch ist der Kanton im Idealfall bereits gut vorbereitet, wenn Bauprojekte beantragt werden. Von Gesetzes wegen müssen sie zwar dann Notgrabungen durchführen, doch es beschränkt sich auf die Verdachtsflächen und ist dadurch fokussierter und zielgerichteter.
Sie hatten einmal erwähnt, dass Sie auch predictive modeling machen – wie funktioniert das genau?
Das ist eine typische GIS Anwendung – wir kartieren und analysieren bekannte Fundstellen vor einem geoinformatischen Hintergrund: Das sind verschiedene Kartenlayer, z.B. Nähe zu Wasser, Bodenqualität, Hangneigung. Aus dieser Analyse leiten wir Principal Components, d.h. Hauptkomponenten von Siedlungssituationen ab (Principal Component Analysis). Wir finden dann vielleicht für typische bronzezeitliche Siedlungen heraus, dass diese auf Hügelkuppen, am Talrand, innerhalb dieser oder jener Vegetationsstufe etc. liegen. Mit einem Vergleich von ähnlichen Merkmalgruppen wird es nun möglich, mögliche Fundstellen vorherzusagen.
Dies ist eigentlich eine spannende Sache – ein grosser Nachteil ist aber, dass man immer nur erfasst, was man bereits kennt. Dagegen kann man aus ergebnisoffenen Prospektionen Fundstellenkategorien erfassen, die man vorher noch nicht kannte. Man muss also die Methoden gut kombinieren. Auch diese offenen Verfahren brauchen aber immer eine Überprüfung vor Ort, man nennt das «ground truthing».
Was müsste es bei uns an der UZH noch geben, damit die Archäologie all diese Methoden in die Lehre oder auch Forschung bringen könnte?
Es fängt bei einfachen Sachen an: Für einen geplanten GIS-Kurs suchten wir vor einigen Jahren einen entsprechend ausgerüsteten Schulungsraum, d.h. Computer mit installierter GIS Software. Die vorhandenen Räume an der MNF waren durchgehend ausgebucht…
Weiter fehlt eine geisteswissenschaftliche Grundausbildung für GIS. Die vorhandenen Module, abgesehen davon, dass sie überbucht sind, gehen immer in andere fachwissenschaftliche Richtungen. Um das zu erreichen, müssten sich an der Philosophischen Fakultät vielleicht verschiedene Institutionen zusammenschliessen – Historiker*innen, Archäolog*innen, Linguist*innen usw.
Ein anderes Thema, das eine grosse Rolle spielt, sind natürlich die Ressourcen: Die Archäologien sind sowieso schon recht teuer. Wir haben teure Feldmodule, wir haben teure Apparaturen, usw. Je mehr Spezialisierungen wir anbieten möchten, desto teuer werden unsere Module im Vergleich zu anderen Modulen der Fakultät.
Doch unser Problem ist, dass wir auf Feldforschung, Geräte oder Software einfach nicht verzichten können, wenn wir bei den «Digital Archaeologies» mithalten können wollen. Ein Beispiel: Für einen Arbeitsablauf in der Digital Archeology benötigt man vielleicht zehn Komponenten, Geräte oder Software, die im Zusammenspiel einen Workflow ergeben: Aufnahme im Feld mit Drohnen o.ä., Datenverarbeitung, Visualisierung etc. Gerade für solche scheinbar unzusammenhängenden Komponenten ist es schwierig, an Finanzierungen zu kommen, weil das Verständnis für die spezifischen Prozesse manchmal nicht da ist.
Ohne die Komponenten ist aber ein Einstieg in die digitalen Methoden gar nicht möglich – so wird man technisch abgehängt, nicht?
Gerade wenn man Digital Humanities fördern möchte, brauchen sie einen Stellenwert im Studienprogramm, etwa indem fachübergreifenden Strukturen geschaffen werden oder in der Fakultät Cluster gebildet und mit Ressourcen ausstattet werden. Ich denke da auch an Lehrpersonal – ich würde natürlich morgen eine Dozent*in mit Spezialgebiet «Digital Archeology» anstellen, wenn ich könnte.
Man darf nicht vergessen, dass die Archäologie ein konkretes Anwendungsfeld hat. Wir bedienen Kantonsarchäologien, die einen Öffentlichkeitsauftrag haben, mit fachwissenschaftlichem Nachwuchs. Es ist nicht nur eine geisteswissenschaftliche Disziplin, sondern gewissermassen auch eine Berufs(aus)bildung. Deshalb müssen wir sicherstellen, dass wir methodisch und technisch nicht hinterherhinken. Auch wenn wir nur 24 Kantone und sogar etwas weniger Kantonsarchäologien haben, und wir nicht hunderte von Studierenden für diesen Markt ausbilden können, benötigen wir dennoch Ressourcen, um eine angemessene Ausbildung bieten zu können.
Wir haben eine Verpflichtung gegenüber dem kulturellen Erbe der Schweiz, wenn nicht gegenüber der Menschheit, dass wir Leute ausbilden, die in der Lage sind, das Management dieses kulturellen Erbes auf allen Stufen wahrzunehmen, vom Boden bis zur Rekonstruktion.
Das neue Text Crunching Center (TCC) hilft bei Textanalysen und bei Fragen wie: Wie komme ich zu meinen Daten? Wie muss ich sie für meine Forschungsfrage aufbereiten, oder – welche Fragen kann ich an meine Daten stellen? Angesiedelt am Institut für Computerlinguistik und konzipiert als Dienstleistungszentrum – wir hören in diesem Beitrag, für wen das TCC gedacht ist und welche Dienstleistungen angeboten werden.
Bitte stellen Sie sich vor!
[Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert.
[Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.
Vielen Dank für die Vorstellung – wie ist denn nun das Text Crunching Center entstanden?
[GS] Entstanden ist das Text Crunching Center dadurch, dass das Institut für Computerlinguistik bzw. Martin Volk inzwischen so viele Anfragen im Gebiet Text Mining und Textanalyse erhält, dass es nicht mehr länger möglich ist, diese alle selbst zu bearbeiten.
Das Text Crunching Center bietet in diesem Gebiet Dienstleistungen an: Bei allem, was mit Text Mining, Sentimentanalyse, Textanalyse im Allgemeinen – generell mit Methoden der Digital Humanities oder Machine Translation – zu tun hat, können wir Projekte unterstützen. Auch allgemeine Unterstützung für Digitalisierungsprozesse oder Textverarbeitung wie OCR, aber auch Beratung zu Tools, Software oder Best Practices bieten wir an. Wir helfen ebenfalls gerne beim Schreiben von Projektanträgen, geben Coaching und Unterricht in der Textanalyse, oder können fertige (Software-)Lösungen anbieten.
[TE] Wir sind die Ansprechpartner für alle, die in ihren Projekten mit viel Text umgehen müssen, das technische Knowhow aber nicht haben und nicht genau wissen, wo sie anfangen sollen. Man kann z.B. zu uns kommen, wenn man einfach Text vor sich hat und eine Idee braucht, was man damit mit der Maschine alles anfangen könnte.
Könnten Sie mir ein konkretes Beispiel einer Anfrage geben – wie muss man sich den Ablauf vorstellen, wenn man auf Sie zukommt?
[TE] Wenn z.B. jemand aus einem bestimmten Forschungsgebiet untersuchen möchte, was der öffentliche Diskurs zu einem Thema ist – nehmen wir mal das Thema «Ernährung». Dazu möchten sie dann gerne Social Media Daten auswerten, die technische Umsetzung ist gehört aber nicht zu ihrem Fachgebiet. In dem Fall kann man zu uns gelangen und wir beraten in einem ersten Schritt: Wir klären die Fragen, wie man überhaupt an Daten gelangen kann, was man mit den Daten machen könnte. Es kann so weit gehen, dass wir einen Prototypen erstellen, mit dem sie dann direkt ihre Daten auswerten und Forschungsergebnisse erhalten können.
Welche konkreten Möglichkeiten würden Sie in den Personen in diesem Beispiel vorschlagen und wie würden sie es umsetzen?
[GS] In diesem konkreten Beispiel haben wir Twitter-Daten mit Hilfe von Text Mining gesammelt und ein Coaching angeboten. Die R Skripts haben wir ebenfalls geschrieben, die Personen aber zusätzlich so weit gecoacht, dass sie diese schliesslich selbst anwenden konnten. Die über das Text Mining erhaltenen Daten werden mit den Skripts exploriert und verschiedene Outputs generiert. Dabei haben wir «klassische» Digital Humanities Methoden angewendet wie z.B. Distributionelle Semantik, Topic Modeling, oder auch analysiert, wie in den Tweets bestimmte linguistische Merkmale gebraucht werden.
[TE] Es kommt immer auf die Kunden darauf an: In diesem Beispiel wollten die Kunden die Anwendung gerne selber lernen. Wenn sie dafür aber keine Zeit oder kein Interesse daran gehabt hätten, hätten wir auch alles selbst implementieren können: Also das fertige System oder die aufbereiteten Daten.
[GS] Ein Produkt, das dabei entstanden ist, ist eine «konzeptuelle Karte» von Bier, Cidre und Wein. Es ist eine semantische Karte, in der ähnliche Konzepte näher beieinander liegen als Konzepte, die inhaltlich weiter voneinander entfernt sind. Rund um den Cidre liegen beispielsweise die Begriffe «Äpfel», «Jahreszeit», «Wärme» usw. Man sieht auch, dass die Essenskultur mit «dinner», «cooking», etc. viel näher am Konzept «Wein» liegt als bei «Bier» oder «Cidre». Solche automatisch erstellten Karten vereinfachen stark, sind aber anschaulich und gut interpretierbar, deshalb zeigen wir sie als ein Beispiel unter vielen.
Eine ähnliche Karte etwa entstand in einem anderen Projekt aufgrund von Daten ausgewählter Reden von Barack Obama und Donald Trump. Barack Obama spricht etwa mehr von «opportunity» oder «education», während Donald Trump davon eher weiter weg ist und eher über China und Deals spricht, und wer ihm alle angerufen haben. «Peace and Prosperity» als Vision versprechen natürlich beide.
Nun rein technisch gefragt – wie entsteht so eine konzeptuelle Karte? Die Verbindungen stellen die Distanzen zwischen den Konzepten dar, nehme ich an – mit welcher Methode bestimmen Sie denn die Ähnlichkeiten?
[GS] Es handelt sich um eine Methode der distributionellen Semantik: Man lernt aus dem Kontext. D.h. dass Wörter, die einen ähnlichen Kontext haben, auch semantisch ähnlich sind. Gerade bei grossen Textmengen führt so ein Ansatz zu guten Ergebnissen. Es gibt da verschiedene Methoden, um dies zu bestimmen – gemeinsam ist ihnen jedoch der kontextuelle Ansatz.
In diesem konkreten Beispiel wurde mit Kernel Density Estimation gearbeitet. Man zerlegt dafür den Korpus zunächst in kleine Teile – hier waren es etwas 2000. Für jedes Wort prüft man dann, wie das gemeinsame Auftreten in den 2000 «Teilen» ist. Wörter, die sehr häufig miteinander auftreten, kommen dann das Modell. Dabei werden nicht die absoluten Zahlen verwendet, sondern Kernel-Funktionen gleichen die Zahlen etwas aus. Daraus kann schliesslich die Distanz zwischen den einzelnen Konzepten berechnet werden. In diesem Prozess entsteht ein sehr hochdimensionales Gebäude, das für die Visualisierung auf 2D reduziert werden muss, um es plotten zu können. Da dies immer eine Vereinfachung und Approximierung ist, braucht es immer die Interpretation.
Wie wichtig ist es für Ihre Aufgabe, dass Sie einen breiten disziplinären Hintergrund haben?
[TE] Man darf nicht denken, dass die Texttechnologie das «Wunderheilmittel» für alle Probleme ist. In einer Beratung geben wir immer eine realistische Einschätzung darüber ab, was möglich ist und was nicht.
Daher ist die Frage sehr relevant. Man muss einen gemeinsamen Weg zwischen der computerlinguistischen und der inhaltlichen Seite finden. Es ist wichtig, dass wir beide durch unseren Werdegang viele Disziplinen abdecken und schon in vielen verschiedenen Bereichen mitgearbeitet haben.
Gerade in einem Projekt aus der Biomedizin, in dem es darum ging, welche Auswirkungen bestimmte Chemikalien auf gewisse Proteine haben, hat mein biologisches Wissen aus dem Biologie-Leistungskurs und einem Semester Studium sehr geholfen. Als Laie würde man diese Texte überhaupt nicht verstehen, deshalb könnte man auch keine geeignete Analyse entwerfen. Insbesondere auch auf der Ebene der Fehleranalyse ist das Disziplinen-Wissen wichtig: Möchte man herausfinden, warum das entwickelte System in manchen Fällen nicht funktioniert hat, hat man ohne disziplinäres Wissen wenig Chancen.
Deshalb ist es wichtig, dass wir realistische Einschätzungen darüber abgeben können, was umsetzbar ist – manche Fragen sind aus computerlinguistischer Sicht schlicht nicht auf die Schnelle implementierbar.
[GS] Dennoch können oft neue Einsichten generiert werden, oder auch nur die Bestätigung der eigenen Hypothesen aus einer neuen Perspektive… Die datengetriebenen Ansätze ermöglichen auch eine neue Art der Exploration: Man überprüft nicht nur eine gegebene Hypothese, sondern kann aus der Datenanalyse neue Hypothesen generieren, indem man Strukturen und Muster in den Daten erkennt.
Hier hat sich bei mir ein Kreis geschlossen: Aus der Literaturwissenschaft kenne ich das explorative Vorgehen sehr gut. Dagegen ist ein rein computerlinguistisches Vorgehen schon sehr anders. Mit Ansätzen der Digital Humanities kommt nun wieder etwas Spielerisches in die Technologie zurück. Die Verbindung von beidem erlaubt einen holistischeren Blick auf die Daten.
Wie würden Sie denn Digital Humanities beschreiben?
[GS] Es ist wirklich die Kombination der beiden Ansätze: «Humanities» kann man durchaus wortwörtlich nehmen. Gerade in der Linguistik ist damit auch ein Traum wahr geworden, wenn man an Ferdinand de Saussures Definition von Bedeutung denkt. «La différence», die Bedeutung, ergibt sich nicht daraus, was etwas «ist», sondern was es im Zusammenhang, im Ähnlich-Sein, im «Nicht-genau-gleich-sein» mit anderen Dingen ist. In der Literaturwissenschaft wird dieser Umstand in der Dekonstruktion mit der «différance» von Jacques Derrida wieder aufgenommen. Die distributionale Semantik hat genau das berechenbar gemacht. Es ist zwar einerseits sehr mathematisch, andererseits ist für mich dieser spielerische Zugang sehr wichtig.
Die genaue philosophische Definition von Digital Humanities ist für mich dagegen nicht so wichtig: Doch die Möglichkeiten, die sich mit den digitalen Methoden ergeben – die sind toll und so viel besser geworden.
[TE] Die Humanities, die bisher vielleicht noch nicht so digital unterwegs waren, geraten momentan auch etwas unter Druck, etwas Digitales zu benutzen…
Mein Eindruck war bisher nicht nur der eines «Müssens», sondern auch eines «Wollens» – doch der Einstieg in die Methodik ist einfach sehr schwierig, die Schwelle sehr hoch.
[TE] … und gerade hier können wir einen sehr sanften Einstieg mit unseren Beratungen bieten: Wenn jemand noch gar keine Erfahrung hat, aber ein gewisses Interesse vorhanden ist. So muss niemand Angst vor der Technologie haben – wir begleiten das Projekt und machen es für die Kunden verständlich.
[GS] Aber auch Kunden, die schon ein Vorwissen haben und bereits etwas programmieren können, können wir immer weiterhelfen…
Gilt Ihr Angebot nur für Lehrende und Forschende oder auch für Studierende?
[TE] Das Angebot gilt für alle, auch für externe Firmen. Für wissenschaftliche Projekte haben wir aber natürlich andere, günstigere Tarife.
[GS] Die Services werden zum Selbstkostenpreis angeboten. Ein Brainstorming, d.h. ein Einstiegsgespräch können wir sogar kostenlos anbieten. Auch für die anschliessende Beratungs- oder Entwicklungsarbeit verlangen wir keine überteuerten Preise. Für unser Weiterbestehen müssen wir allerdings eine gewisse Eigenfinanzierung erreichen.
Wo soll das Text Crunching Center in einigen Jahren stehen?
[TE] Natürlich möchten wir personell noch wachsen können… Wir bilden uns dauernd weiter, um state-of-the-art-Technologien anbieten zu können. Die Qualität der Beratung soll sehr hoch sein – das wünschen wir uns.
[GS] … und wir wollen die digitale Revolution unterstützen, Workshops anbieten, das Zusammenarbeiten mit dem LiRI oder mit Einzeldisziplinen verstärken. Letztlich können alle von der Zusammenarbeit profitieren, indem man voneinander lernt und Best Practices und Standardabläufe für gewisse Fragestellungen entwickelt. Auch die Vernetzung ist ein wichtiger Aspekt – wir können helfen, für ein bestimmtes Thema die richtigen Experten hier an der UZH zu finden.
Ich drücke Ihnen die Daumen! Vielen Dank für Ihr Gespräch!

















 [Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert.
[Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert. [Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.
[Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.