In this chapter, we discuss topic modelling, a useful method to analyze large quantities of text, and present an example using Mallet.
Introduction
https://uzh.mediaspace.cast.switch.ch/media/0_ca286wtg
Our discussion of document classification in the last chapter provided new possibilities of analyzing large quantities of data, but also raised an important issue: LightSide makes use of thousands of features, which makes it impossible to interpret these features individually. One way of dealing with the abundance of features is to abstract away from the features towards larger concepts, specifically to topics. This is precisely what topic modelling allows us to do.
In topic modelling, we generate models which try to learn from the context of words. It is based on what is known as the Firthian hypothesis, which states that “you shall know a word by the company it keeps” (Firth 1957: 11). If we have really large amounts of text, then the words that appear together frequently in similar contexts are likely to contribute to the same topic.
Think about lactose, for instance. Lactose is not a very common word. But if we have a corpus of academic papers on nutrition, there is a good chance that some of these papers contain many occurrences of lactose. And if some of those articles focus on lactose intolerance, there is a fair chance that the word lactase will occur frequently two. At the same time, lactase might be even rarer in the rest of the corpus than lactose. So, since these two words – lactose and lactase – cooccur frequently, our topic model will recognize them as elements belonging to the same topic.
In terms of Bayesian statistics, topic modelling optimizes the probability of a topic given the document times the probability of the word inside this topic. Expressed mathematically, topic modelling optimizes  , or the probability of finding a topic given the document multiplied by the probability of finding a word given the topic. As such, it is a mixture of document classification and keyword generation. The first part of the term,
, or the probability of finding a topic given the document multiplied by the probability of finding a word given the topic. As such, it is a mixture of document classification and keyword generation. The first part of the term,  , corresponds exactly to what happens in document classification. The second part of the term,
, corresponds exactly to what happens in document classification. The second part of the term,  , is more about word-generation for a given topic or class. It determines which words are likely to be generated in a given topic, and these probabilities vary strongly with different topics.
, is more about word-generation for a given topic or class. It determines which words are likely to be generated in a given topic, and these probabilities vary strongly with different topics.
Unlike with the document classification example we discussed in the last chapter, where we defined the two classes into which the documents were grouped, in topic modelling the topics aren’t predefined. Instead, they are discovered by the algorithm. So, the documents and the words within them are given by the corpus, and the topics are generated to fit the data.[1] You can think about this in terms of the model fit which we have seen it in the chapters on regression analysis.
Fitting the topic model to the textual input is an iterative process. At the beginning of this process is a random seed, which means that we never get exactly the same results when generating multiple topic models for the same corpus, even when we set identical parameters for the different models.
Although it would be possible to generate topic models in R, we choose to demonstrate topic modelling with Mallet, which is the fantastic if somewhat contrived abbreviation of “MAchine Learning for LanguagE Toolkit”. Mallet is very popular in the digital humanities, since it does not require a lot of programming to deliver good results. Perhaps topic modelling reminded you of Wmatrix (Rayson 2008). The difference is that where Wmatrix has fixed sets of words which point to certain topics, Mallet is completely data driven, which means that our topic models adapt better when we work with historical data or open genres.
Topic modelling with Mallet
https://uzh.mediaspace.cast.switch.ch/media/0_y6dm1vra
Before we begin, download Mallet from the official webpage: http://mallet.cs.umass.edu/download.php. Installing Mallet is somewhat involved and the instructions on the Mallet website are rather sparse. If you need more guidance than Mallet provides, we can recommend Graham et al.’s detailed, user-friendly installation instructions for Mallet which are available at https://programminghistorian.org/en/lessons/topic-modeling-and-mallet#installing-mallet.
Once you have installed Mallet, we can take a look at what topic modelling actually does. For this example, we downloaded several novels by Charles Dickens, A Christmas Carol, David Copperfield, Great Expectations, Hard Times, Nicholas Nickleby, Oliver Twist, The Pickwick Papers and Tale of Two Cities, to be precise. Together, our corpus contains roughly 1.6 million words. All of these novels are part of the public domain and can be found on Project Gutenberg. You can download them yourself, or you can download the .mallet file containing all books in pre-processed form here:
[Dickens file for Mallet]
We recommend saving the file to new folder in the Mallet directory which we called ‘Dickens’. You are, of course, free to save it wherever you want, just be aware that you will need to adjust the file paths in the commands accordingly.
There are some small but important differences between running Mallet on Windows and running it on Mac, specifically as regards the back- and forwardslashes. On Windows, we use backslashes, while on Mac we use backslashes. As a consequence, what on Windows is the command bin\mallet is translated into bin/mallet on Mac.
Once we get Mallet loaded on both operating systems, we only describe the Windows version, but you should be able to translate our code for Mac. Additionally, regardless of the operating system, it is very possible that you will need to adjust some commands to be consistent with how you named your directories. As per usual when writing code, everything is extremely finicky and needs to be done precisely.
Since Mallet does not come with a graphic user interface, we need to open it via the shell or the terminal. On Windows and on Mac, the terminal can be opened by searching for ‘terminal’. To go to the Mallet directory on Windows, we need to change the directory, the command for which is cd. Accordingly, we enter the following command after the prompt:
> cd C:\malletThis command depends on the precise name you gave to the Mallet directory on your C: drive.
If you installed Mallet on your Mac following Graham et al., you can access Mallet by opening the terminal in the Finder and changing to the Mallet directory. To do this, enter:
> cd mallet-2.0.8To check whether Mallet runs the way it should, enter:
> bin\malletOr the equivalent on Mac:
> ./bin/malletWhen Mallet runs correctly, you will see a list of commands after entering bin\mallet:
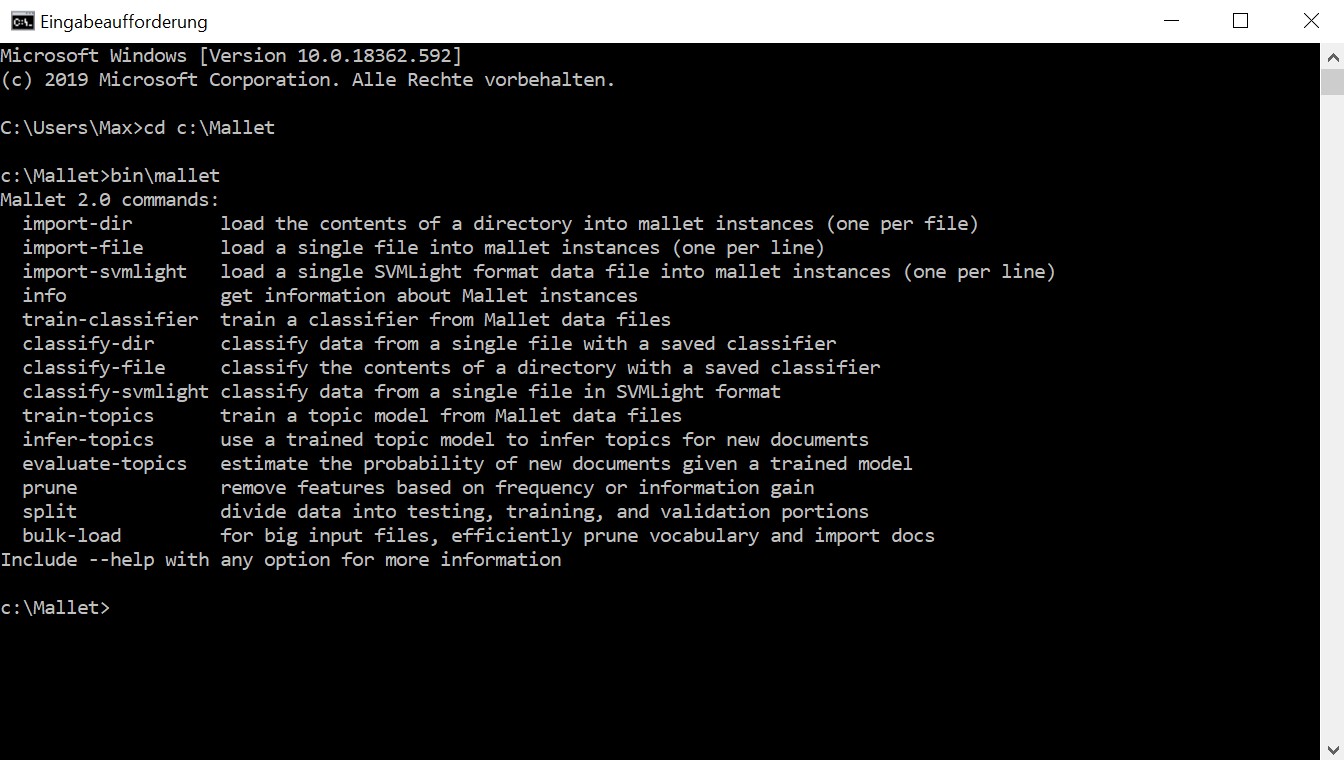
In a next step, we can take a look at the data. Remember that we saved it in a ‘Dickens’ folder in the Mallet directory. Accordingly, we have to navigate to this folder to see ‘more’ of our corpus:
> more Dickens\Dickens8Novels_noNP.formalletWe see that A Christmas Carol is the first of the novels. You can see that, initially, only a small piece of text is displayed. This is because we divided the novels into smaller subsections. This step is needed in order create reasonably good topic models with Mallet. If you think about how the document impacts the generation of the model, this makes a lot of sense. A single, long document prevents the calculation of the topic probability. Or rather, since there is only one long document, all of the topics have an equal probability of occurring in that one document. This makes it impossible to generate topics on the basis of word cooccurrences in multiple documents. Of course, the eight novels are a handful of different documents, but there is some evidence to suggest that working with more smaller documents yields better results.[2] Whether to divide the corpus along to chapters, or simply creating segments of 1,000 words as we did here is up to the discretion of the research, which is to say you.
The second step of the pre-processing involved removing names from the texts in order to prevent Mallet from generating topics based primarily on names. Again, if you think about how words are distributed across novels, this should make sense. Those words which are least likely to occur both in novel A and novel B are names. Every other class of words can potentially be, and is plausibly, used in multiple novels in our corpus. This means that those words which have the strongest cooccurrence measures are the names. However, since names do not actually reveal a lot about the topics of a novel, we automatically replaced all named entities with a ‘NP’. For this, we used a part-of-speech tagger, with which we tagged the whole corpus. Then we replaced all of the named entities with their tag, ‘NP’. The result of this process is that the string ‘NP’ occurs as frequently as the word ‘the’, wherefore they are no longer a salient feature and do not show up in the topic model.
The next step is to import the corpus file into Mallet. To do this, we follow the instructions given on the Mallet website. Of course, the commands we use diverge somewhat from the generalized version in the official instructions, but you should recognize all of the important parts in our command and be able to adapt it according to your directory names and operating system:
> bin\mallet import-file --input Dickens\Dickens8Novels_noNP.formallet --output Dickens\Dickens8Novels_noNP.mallet --keep-sequence --remove-stopwordsEssentially, we need to tell the Mallet tool that we want to import a document, we need to specify where the document is, and we need to specify which Mallet representation is going to be created. We want to keep information about the sequence of words in the documents, and we want to remove the function and auxiliary words, which are also known as stopwords. We can remove the stopwords in good conscience since they do not contribute to the semantic content which is currently of interest to us.
The next step is training the topics. As we mentioned above, this begins at a random seed and then trains itself over several iterations. This usually takes a fair amount of time. The only important parameter that we need to set for this step is the number of topics. For our example, we use twenty topics. This is the step which models the topics that are prototypical of Dickens’ writings. To start the training step, we use the following command:
> bin\mallet train-topics --input Dickens\Dickens8Novels_noNP.mallet --num-topics 20 --optimize-interval 10 --output-state Dickens\Dickens8Novels_noNP.topic_state.gz --output-topic-keys Dickens\Dickens8Novels_noNP_keys.txt --output-doc-topics Dickens\Dickens8Novel_noNP_composition.txtHere, we are making Mallet train twenty topics from out input. The optimization interval allows Mallet to fit the model better. The output state is a list of all words in the corpus and their allocated topics. The output-doc-topic command gives us the composition of each document, i.e. what percentage each topic contributes. But by far the most interesting element at this stage of the analysis are the topic keys, since they tell us which twenty keywords are most representative of each topic. After you train the model, we’ll want to discuss the topic keys. However, this can take a while. As the model trains, you can follow how the topics improve with each iteration.
Interpreting the results
https://uzh.mediaspace.cast.switch.ch/media/0_cd5rajjs
Once the model is trained, we can take a first look at the results. To do so, we have to go to the Dickens folder in the Mallet directory, which is where we saved the output of topic modelling process. The most valuable information for evaluating the topic model is in the keywords for our twenty topics which we saved as “Dickens8Novels_noNP_keys.txt”. The keywords of our model look as follows:

On account of the random seed, which is at the start of the modelling process, your results will most likely be different from ours, especially in terms of the order of topics. Additionally, we have annotated our keywords slightly, coloring the readily interpretable topics blue and some striking words red. It is typical of topic modelling that some topics are more easily interpretable than others and in our discussion here we only focus on the most interpretable ones.
One of the things which becomes apparent when reading through this list of keywords is that several topics, such as topics 9 and 14, contain many words which contribute to the ambiance. For instance, in topic 9 we see light, night, dark, wind, air and sun, all of which very much contribute to the atmosphere of a setting. In topic 14 we see a lot of words revolving around time, with night, day, morning, evening, hour and days. Together, these topics manage to not only display Dickens’ penchant for atmospheric descriptions but also for the way in which he makes you feel the passage of time.[3]
Dickens is noted for his descriptive style and careful observations, and our topic model manages to reflect that to some degree. Topic 6, for example, contains many different body parts: face, eyes, hand, head, back, side, arm and voice. People are not just formless blobs moving through these novels, but rather they are physical bodies with idiosyncratic characteristics. Similarly, we can see in topic 16 that spaces are specific, with doors opening to rooms or shutting them off, how candles and fires lighten them up without dispelling the dark completely.
Of course, it would be rather challenging to interpret these topics without having read some of these novels, but this gives us the opportunity to raise an important point: while topic modelling allows you get a handle on a substantial corpus of text, it can lead to misleading or outrightly wrong conclusions if it is not complemented with a careful qualitative analysis. If we look at topic 3, for example, is about directors of companies, with keywords such as managers, gentlemen, company, public, men and honorable. Without reading some text segments to which topic 3 contributes a lot, we have no way of knowing whether there is an ironic undertone to the cooccurrence of the words ‘manager’ and ‘honorable’.
Finally, we want to draw your attention to topic 10, which at first glance looks like the result of a processing error. An error this is not, however. Instead, topic 10 contains words written with non-standard spelling. Reflective either of strong dialects or sociolects, topic 10 shows that Dickens frequently used non-standard spellings as a means of characterization.
Despite our pre-processing, there are still some proper names in the corpus, and so we see old Scrooge from A Christmas Carol (in topic 1) and Madame Defarge who supports the French Revolution in A Tale of Two Cities (in topic 18). While this is not ideal, it is a manageable issue. For substantial further research, one might want to add these names to the list of stopwords or process the corpus differently. Similarly, one would want to remove the copyright information from the corpus, since they occupy most of topic 4. As it stands, it is not clear whether contracts and legal issues would be such a salient aspect of Dickens’ work since we did not filter out the digital copyright information from Gutenberg.
That said, the topics we modelled here are probably of above average quality since the corpus is composed of decently curated and edited text. Depending on the source you work with, you can expect to see a few garbage topics containing words with spelling mistakes or character recognition errors. When it comes to vague or general topics, our model is fairly representative. While it is often possible to give most topics a title, it is typical that some topics, like the ones we discuss above, are more salient than others, such as topic 0 or 15 which are hard to interpret without looking at some text passages.
Exercise: Visualizing topic distributions
So far, we have only looked at the keywords of our topics, but they are only one half to the meaningfully interpretable output of a topic model. The other half is the in the file we called “Dickens8Novel_noNP_composition.txt”. This text file is actually a table, where the rows are the documents in our corpus and the columns are the twenty topics we modelled. Each cell tells us how many percent of the words in a given document are associated with a given topic. This information allows us to visualize how a topic develops over time.
For once, let us start with a literary hunch. Say you’ve been reading a lot of Dickens and you think that his use of non-standard dialects changes over the years. You download some of the books you read on Gutenberg, pre-process them like we did above, and feed them into Mallet. In keeping with your great expectations, one of the twenty topics, topic 10, contains a lot of words with non-standard spellings. You open the composition file – use either the one you generated above, in which case you may want to focus on a different topic number, or download ours here – and then it strikes you. You forgot to order your corpus chronologically. And why exactly did you have to segment it again? That makes it so much harder to track the change between novels. Well, there’s no way around this. If you want to investigate how the use of non-standard spelling changes over Dickens’ career, you need to bring the composition data into a useable form. Try doing it now!
In case you need help, follow the step-by-step guide in the slides below:
[insert h5p slides alternating between described instructions and screenshots]
Outlook and possibilities
Of course, what we discuss here only scratches the surface of what topic modelling has to offer. Depending on the quality of your corpus you can glean insight into the semantic content of a genre or, as we saw above, an author’s oeuvre. If you have data available that encompasses a longer time span, it is possible to trace the development of different topics over time and use topic modelling to trace the history of an idea, as Schneider and Taavitsainen (2019) do in their analysis of “Scholastic argumentation in Early English medical writing”.
One of the great qualities of topic modelling is that it allows you to familiarize yourself with large quantities of text without having to spend hours programming. Once you know how to use Mallet, the programming is a matter of minutes. With topic modelling, you will more likely find yourself spending a lot of time on gathering data and interpreting the keywords. For the latter, it is particularly useful to look at the topic compositions and read some of the documents to which the topic of your interest contributes a lot. The ease with which Mallet allows for large-scale semantic analyses can sometimes lead to sloppy interpretations. So, in order to produce the most insightful results, we recommend using topic modelling in combination with a careful qualitative analysis of the texts you are working with.
References:
Blei, David. 2012. Probabilistic Topic Models. Communications of the ACM, 55.4, 77–84.
Dickens, Charles. 1837. The Pickwick Papers. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/ebooks/580.
—. 1839a. Oliver Twist. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/files/730/730-h/730-h.htm.
—. 1839b. The Life and Adventures of Nicholas Nickleby. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/files/967/967-h/967-h.htm.
—. 1843. A Christmas Carol: A Ghost Story for Christmas. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/files/46/46-h/46-h.htm.
—. 1850. David Copperfield. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/files/766/766-h/766-h.htm.
—. 1854. Hard Times. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/ebooks/786.
—. 1859. A Tale of Two Cities: A Story of the French Revolution. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/files/98/98-h/98-h.htm.
—. 1861. Great Expectations. Urbana, Illinois: Project Gutenberg. Online: https://www.gutenberg.org/files/1400/1400-h/1400-h.htm.
Firth, John Rupert. 1957. A Synopsis of Linguistic Theory 1930–1955. Studies in Linguistic Analysis, ed. by John Rupert Firth. 1–32. Oxford: Blackwell.
Graham, Shawn, Scott Weingart, and Ian Milligan. 2012. Getting Started with Topic Modeling and MALLET. The Programming Historian. Online: https://programminghistorian.org/en/lessons/topic-modeling-and-mallet.
Jockers, Matthew Lee. 2013. Macroanalysis: Digital Methods and Literary History. Topics in the Digital Humanities. Urbana, Chicago and Springfield: University of Illinois Press.
McCallum, Andrew Kachites. 2002. MALLET: A Machine Learning for Language Toolkit. Online: http://mallet.cs.umass.edu.
Rayson, Paul. 2008. From key words to key semantic domains. International Journal of Corpus Linguistics, 13.4, 519–549.
Taavitsainen, Irma and Gerold Schneider. 2019. Scholastic argumentation in Early English medical writing and its afterlife: new corpus evidence. From data to evidence in English language research, ed. by Carla Suhr, Terttu Nevalianen and Irma Taavitsainen, 191-221 Leiden: Brill.
- As you may have expected, we are not going to discuss how this works in detail. There is a lot of material available on topic modelling, but we would recommend reading Blei 2012 for a good introduction to the mathematical aspects of topic modelling. ↵
- See Jockers 133. ↵
- One may think here, for instance, of the opening pages of Great Expectations which are suffused with atmosphere and reflect on the passage of time both at a macro level in their discussion of Pip’s ancestry and on the micro level in the events that unfurl over the course of the evening. ↵
