The preceding chapters of this book have hopefully given an applicable introduction to different statistical methods. In this chapter, we address what we have neglected so far, which is how to phrase search queries that give access to the relevant linguistic data. To this end, we introduce regular expressions and discuss how to get from phrasing queries in a new tool, AntConc, to performing significance tests on linguistic data from the ICE Ireland corpus.
This chapter is based on Gerold Schneider’s 2013 paper “Describing Irish English with the ICE Ireland Corpus”.
Preliminaries
Wherever possible, we have made the data we work with accessible, which often involved a certain amount of preprocessing. In most situations, however, you will be required to draw together your own data from a corpus or several corpora. When examining single features like words, this is usually rather straightforward, but as soon as you are interested in more complex phenomena like grammatical structures or n-grams things become more challenging. In the following discussion, we use the example of Irish English since it enables us to begin with simple features and, building on those, progress to more complex search queries using regular expressions.
Unfortunately, we are unable to make the corpus that we use here available. However, we assume that there is a high likelihood that you are studying linguistics if you are reading this, and that your university gives you access to some corpora. In the worst case, you will have access to corpora containing varieties of English which are not Irish English. This is still quite acceptable as far as worst case scenarios go, since it means that you run the same queries as we do on a different variety of English to see whether some of the features we discuss as Irish crop up in other contexts. Ideally, however, you will have access to a corpus containing Irish English, in which case you can follow the discussion here and see whether your corpus of Irish English yields similar results to the ICE Irish. Regardless the situation you are in, the principles of querying that we discuss here hold.
AntConc
Most corpus interfaces allow you to use regular expression queries, but some of them do not. Laurence Anthony developed a simple but powerful concordance tool called AntConc which allows regular expression queries for any text file. The following discussion is based on research conducted using AntConc and the screenshots capture what it is like to use AntConc as a corpus interface. Before you proceed, we recommend downloading AntConc from the official site: https://www.laurenceanthony.net/software/antconc/
On Windows, the AntConc comes as an executable program (.exe). Unlike with most other executable files, there is no need to install anything. It suffices to put the file in a place where you can easily find it, and then run it. Similarly, you should be able to run the program on Mac directly from the download. However, it may be that a security warning pops up since AntConc is not produced by an identified developer. In that case, adjust the security settings to allow your Mac to run AntConc.
Once AntConc is running, you can load in the text file containing your corpus by clicking on ‘File’ and then selecting ‘Open File(s)’.
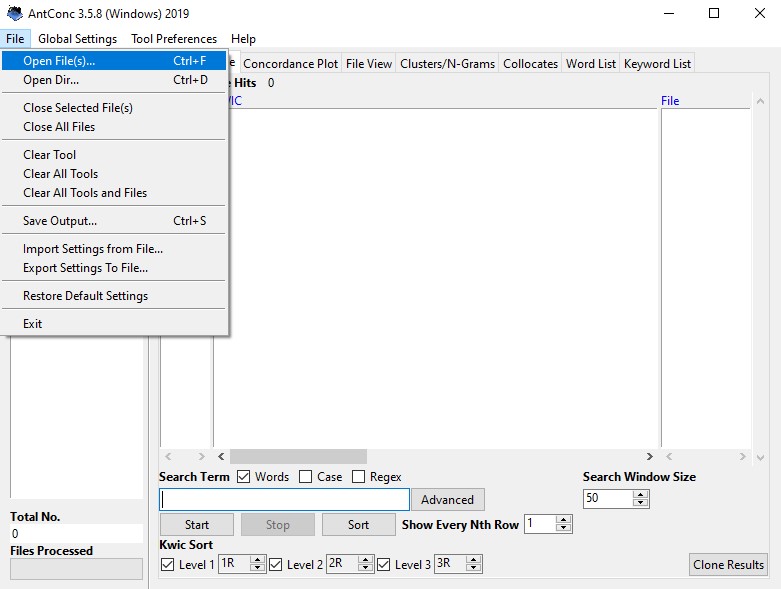
It is possible to import (and then query) multiple files simultaneously, which makes it very easy to compare different corpora. In our case, we load the ICE Ireland North, containing Northern Irish English, and the ICE Ireland South, containing Irish English from the Republic of Ireland.
Corpus queries for Irish English
Many features have been claimed or described for Irish English. The list of phenomena we investigate here using the ICE Ireland corpus is by no means comprehensive and necessarily sketchy. As a starting point for Irish English features we use Trudgill and Hannah (2002), Hickey (2007) and Filppula (1999). In the following, we discuss how to phrase queries to retrieve the features these authors identify as typical of Irish English. We discuss simple word-based queries, slightly more tricky regular expressions and powerful syntactic queries. Except in syntactic queries, the aim is typically to achieve an operationalization which is often a crude approximation.
Typically, the queries retrieve many hits (the instances that are found and displayed to the user), but often the majority of them do not contain the feature under investigation, and we need to filter the results, separating the wheat (true positives) from the chaff (false positives, also referred to as garbage). Generally, this is a two-step procedure:
- We formulate a permissive corpus search query, which should contain most of the instances of the phenomenon under investigation. In other words, it should have high recall, but it may have low precision.
- We do a manual filtering and inspection to select those matches which really are instances. This step repairs the low precision from step 1.
The two evaluation measures precision and recall are defined as follows. Precision expresses how many of the returned matches are positive samples. Recall expresses how many of all the positive samples in the corpus are returned by the retrieval query. While we can easily increase precision by manual filtering of the hits, we can never be sure that our query has maximally high recall. Often, one is even ready to use queries which explicitly only find a subset of the instances of the phenomenon. We then need to make the assumption that the subset is representative of the complete set.
Not every measurable difference between occurrence groups (for example Irish English versus British English or written versus spoken) is meaningful if counts are small, therefore we need to do significance tests to separate random fluctuation from significant differences.
A ‘wee’ feature
There are many lexical items which we could investigate, but since word searches are very straightforward, we only discuss one example: the word ‘wee’, meaning small. All we need to do to find lexical items in corpora is enter the word in the search field and hit enter. Retrieving all instances is trivial. Still, a simple lexical search is a good opportunity to become familiar with AntConc.
By default, AntConc opens on the “Concordance” tab. If you enter the search term, in this case ‘wee’, and start a search, the “Concordance” tab will show you all hits in the “keywords in context” (KWIC) view. Here you can scroll through the hits and read whether these hits are the results you want, whether they are true positives.
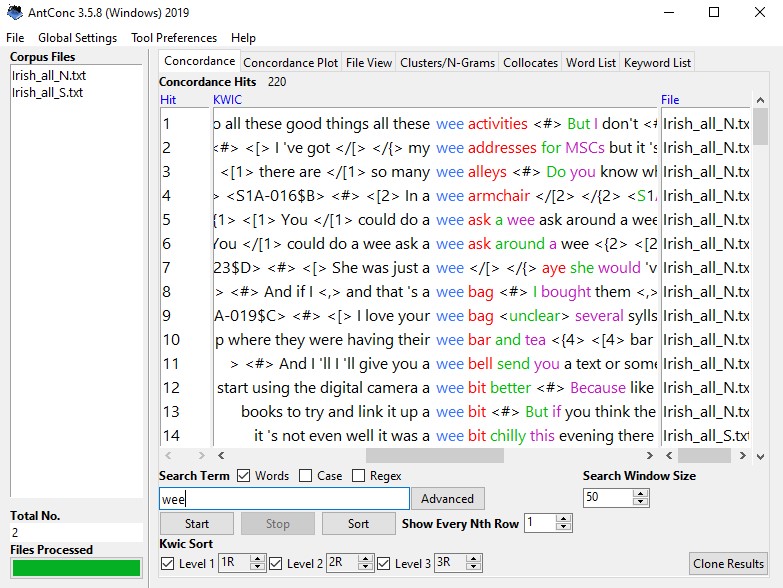
Under the “Concordance” tab, you see that we get 220 hits for ‘wee’. Now, if we open the “Concordance Plot” tab instead, AntConc tells us how these 220 hits are distributed between the Northern and Southern parts of the corpus.
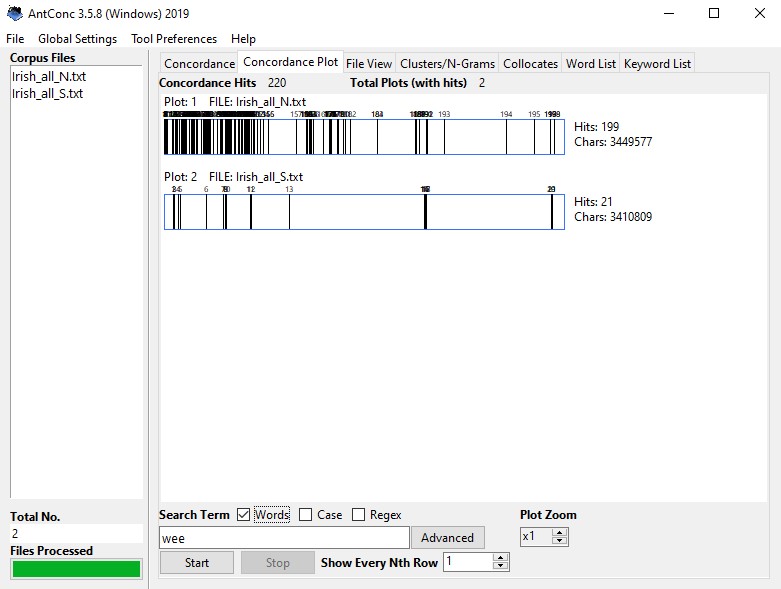
We see here a stark distribution of ‘wee’, with 199 occurrences in Northern Irish English of the corpus, and only 21 occurrences in Southern Irish English. This is not very surprising since ‘wee’ is considered to be a Scottish dialect word and Northern Irish English is known to have been strongly influenced by Scottish immigrants. The concordance plot also shows that the word is more frequent in the beginning of the corpora, which is due to the fact that the first 3/5ths of the corpora are spoken language. This simple query for a wee lexical item thus makes us aware that there can be stark differences between Northern and Southern Irish English and that the use of Irish English features may differ between spoken and written language.
‘For to’ infinitive
Let us now turn to a morphosyntactic feature which is described as being frequent in Irish English, the ‘for to’ infinitive (Filppula 1999: 185). This often, but not necessarily, expresses a purpose infinitive. Since it involves the two-word complementizer ‘for to’, surface word form searches will probably still find most occurrences. If we search the Irish ICE for “for to” in AntConc, we get four hits.
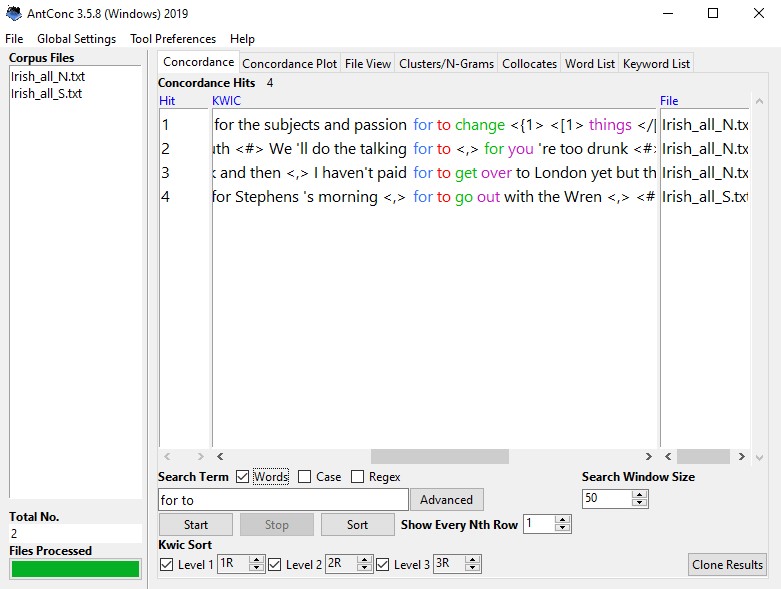
Of these four hits, one is a false positive arising from a false start or correction in spoken data:
- S1A-043:1:33:A We’ll do the talking for to for you re too drunk
The other three occurrences are true positives, for example:
- S1A-014:152:B_ No it’s no it was two hundred no it’s two hundred and twenty from Gatwick and then I haven’t paid for to get over to London yet but then the rest of it was all insurance
There are really too few instances of the ‘for to’ infinitive to conclude anything other than that it occurs in Irish English and that it generally rare but permissible.[1]
This example shows that it is essential to inspect the hits. If there are few, like here, the only responsible thing is to read through all of them and classify them as true or false positives. If you receive more hits than you can inspect manually, draw a random subset from your results to determine the percentage of true positives. We discuss a quick and dirty method for doing this below.
Querying for complex phenomena: ‘It’ clefting with the copula
Things become more complicated when we look at more complex features of Irish English like, for instance, ‘it’ clefting with a copula (Filppula, 1999: 243 ff.). The placing of the preposition towards the end of the sentence is quite popular in sentences with ‘it’ clefting in Irish English. As a result, a sentence like “It’s Glasgow he’s going to tomorrow” is more likely to occur than “It’s to Glasgow he’s going tomorrow”. You can see that in the version preferred in Irish English, there can be quite a long distance between the copula and the preposition. How can we operationalize, formulate a search query that is, for a feature like this?
One approach would be to run a case sensitive search for ‘It is’, ‘It was’, ‘’Tis’ or ‘’Twas’ to identify the sentences in the corpus that begin with ‘It’.
When we run this case-sensitive search, we either get more hits than can realistically be classified manually (409 and 531 for ‘It is’ and ‘It was’ respectively) or we get very few hits which are all false positives (14 and 5 for ‘’Tis’ or ‘’Twas’ respectively). There are several possibilities for dealing with situations like these, where are swamped with more hits than we can manually classify as true or false positives.
Random sampling
The first of these is a generally applicable recipe which can be used whenever a search output is beyond manual classification: randomization. The idea is to take a random subset of the retrieved instances, classify them as true or false positives and calculate the percentage of true positives. We can extrapolate from the rate of true positives in our sample to the number of true positives among all retrieved hits.
Let’s take a look at how to do this in practice when working with AntConc.[2] Our search above yielded most hits for ‘It was’, so we’ll demonstrate the principle using this example. AntConc allows you to save the output of your searches. To do this, enter your query and wait for AntConc to showthe results. Then, click on ‘File’ and select ‘Save Output’. Save the output as a text file, for instance as antconc_results_was.txt.
In a next step, open the text file in Excel or a comparable program. To do so, right click on the file, choose ‘Open With’ and select Excel. You will see that Excel automatically recognizes the text file as a table and loads the AntConc output into four columns. The first contains an ID number for each hit, the second contains some words preceding the search term, the third contains the search term and what follows, and the fourth tells us which corpus the hit is from. In the empty fifth column, we can generate a random number between 0 and 1 by entering “=RAND”. If we place the cursor on the bottom right corner of the cell, it turns into a little black cross. Make a left click when you see the black cross and don’t release it. Now we can drag the cursor down along the table, until each row containing data also contains a random number between 0 and 1.
Now, we can sort the output according to this new column of random numbers. To do this, we can go to the ‘Data’ tab in Excel and select ‘Sort’. A window opens where we can choose along which column we want to have our data sorted. In our case, we choose column E which is the one containing the random numbers. Clearly, it does not matter whether we sort from smallest to largest or vice versa. When we hit ‘OK’, the rows are rearranged. Now we can read through the hits, identifying them as true or false positives. There is no hard rule as to how many observations are required for a sample to be large enough, but as a rule of thumb 50 observations are the bare minimum for a sample to be adequately large, but 100 are recommended.
A simple way of automating the counting process is to start a new column in which we enter a 1 for the true positives and a 0 for the false positives. Once we finish evaluating our sample, we can simply sum the values in this new column by selecting an empty cell and entering “=SUM(F1:F100)” (or something equivalent, depending on what your specific document looks like). The sum we just calculated tells us the percentage of true positives in our sample. In our example with the ‘It was’ search the random sample with size n = 100 yielded a single true positive, which obviously means that 1% of our sample are/is true positive. We can extrapolate from the sample to the “population” (meaning all results) by calculating the number of hits by the true positive rate:  . Accordingly, we can expect to find five cases of ‘It’ clefting with ‘was’ in this corpus. We also see that our search query is far from perfect to investigate the phenomenon we are interested here. Sometimes sampling is the only way of dealing with the wealth of results and in those cases we can only recommend doing it. In other cases, such as the current one, it is possible to phrase better search queries which retrieve less but more precise hits.
. Accordingly, we can expect to find five cases of ‘It’ clefting with ‘was’ in this corpus. We also see that our search query is far from perfect to investigate the phenomenon we are interested here. Sometimes sampling is the only way of dealing with the wealth of results and in those cases we can only recommend doing it. In other cases, such as the current one, it is possible to phrase better search queries which retrieve less but more precise hits.
Phrasing better search queries with regular expressions
One possible means to formulate a better search query would be to use AntConc’s search patterns for the prototypical “It’s Glasgow he is going…”. The idea here is to substitute parts of the sentence with the wildcard symbol, #. We can try several queries like this, but all of them are limited in the scope of results:
Despite the range of queries we run here, the ‘it’ cleft proves elusive.
Fortunately, there is a query language that is much more powerful, which can be used in AntConc and many other corpus interfaces. The query language we are referring to is known as regular expressions, or regex.
Regular expressions can be used to phrase queries for language patterns. All of the queries we made so far were queries for individual words or word pairs. With the ‘It’ clefting, we are confronted with a pattern which requires a more elaborate query. Take a look at the most important regular expressions below, to get a first impression of the things regex allows us to specify.
| a? | optinal a |
| a* | 0 to infinte a‘s |
| a+ | at least one a |
| (aa|bb) | aa or bb |
| [abc] | a or b or c, e.g. s[iauo]ng |
| \b | word boundary |
| \n | newline |
| \t | tab |
| \s | whitespace = [ \t\n\r\f] |
| [^a] | anything but a, e.g.[^_]+_N |
| a{1,5} | between 1 and 5 times a |
There are many resources online which list all regular expressions or offer interactive tutorials for regex. If you think that regex might be useful for you, we can only recommend spending some time on online tutorials like https://regexone.com/. For a more comprehensive overview of commands than the one above, take a look at Robert Heckendorn’s regular expression primer at http://marvin.cs.uidaho.edu/~heckendo/Handouts/regex.html.
Using the powerful regular expressions in AntConc, we can formulate a query for ‘It’ clefting, namely:
It 's (\w+ ){1,5}\w+ingLet’s untangle this query to better understand what we are doing here. The first two elements – ‘It’ and ‘’s’, are straightforward searches for these two strings. The ‘(\w+ ){1,5}’ allows for anything between 1 and 5 words followed by a whitespace. Finally, the ‘\w+ing’ searches for any word ending on ‘ing’. Put together into a single query, the line is a search for “It ‘s” and an “…ing” verb separated by 1, 2, 3, 4 or 5 words. With possibilities like this, regular expressions allow us to query for syntactic long-distance dependencies.
If we run our query – It 's (\w+ ){1,5}\w+ing – in AntConc, we get 112 hits to go through:
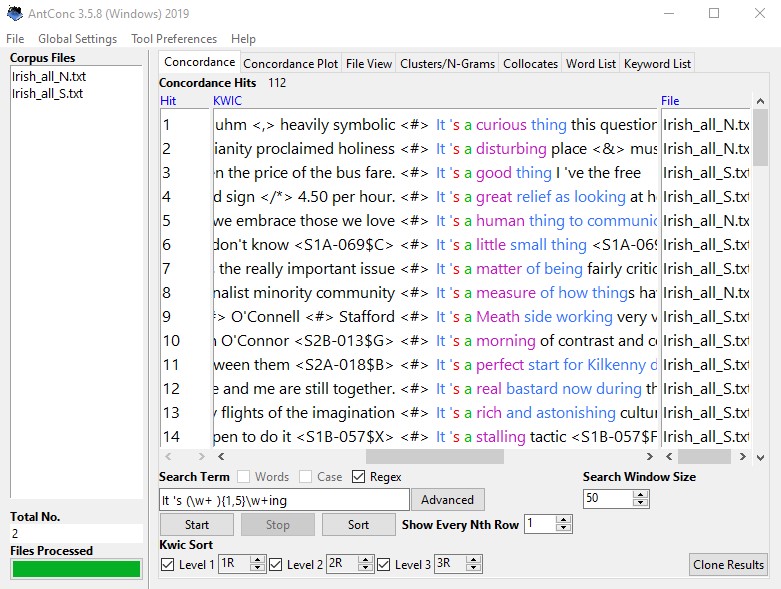
Now we receive much better results, such as:
- S1A-003:82:C_ It’s not the actual driving that’s hard it’s starting
Of course, we can run through many variations of this. In the following, we show several different regex queries that come in handy here and present some example output.
For a typical noun phrase beginning, we can search for:
It 's a (\w+ ){1,5}\w+ingWe get 14 results, including sentences like:
- S2A-011:6:B_ It’s a Meath side working very very hard for all their scores this afternoon
To get more noun phrases, we can substitute the indefinite article by the definite one:
It 's the (\w+ ){1,5}\w+ingHere we get 3 results
- S1B-037:64:E_ It’s the view of the Irish people expressing democratically in the Oireachtas and by the government
We could also open this up by leaving out the search for the ‘ing’ form:
It 's the (\w+ )This also results in some typical NP beginnings, such as:
- S1A-058:38:D_ It’s the smaller places like Mayo and that that I can’t quite locate laughter
- W2F-001:160:p_A It’s the Protestant side’s bigoted
Alternatively, we can try to capture proper names by searching for uppercase letters:
it 's [A-Z](\w+ ){1,5}\w+ingThis results in output like:
- S2A-004:11:B_ it’s uh it’s Mat Sexton going forward not Kempson”
A further approach would be to opt for a longer window:
It 's (\w+ ){1,8}\w+ingThereby, we get 131 hits which might include some true positives which our earlier search with a smaller window did not manage to retrieve.
We discuss further examples of regular expressions with regard to several more features, but the queries we phrased for retrieving cases of ‘It’ clefting should have given you some impression of the power of regex as a query language.
As with R, and every other programming language for that matter, a word of caution is due. Since because it allows for such precise querying, regex is extremely susceptible to small mistakes and coding differences. For instance, if we replace the ‘ – which we required it in the search for ‘Tis – with an ‘, AntConc will retrieve zero hits because the character we searched for is not in the corpus. Regex is as nitpicky as any other programming language.
Another thing to be aware of is that differences between corpora can to throw a spanner in the works. For example, all of our queries above included a whitespace between ‘It’ and ‘’s’. If you wanted to compare the ICE Ireland with the ICE GB, our search queries would give you zero hits from the ICE GB. Why, you ask? It is not because British English never uses contractions but because the ICE GB does not include a whitespace between ‘It’ and ‘’s’. To get results from ICE GB, we would have to search for:
It's the (\w+ )This would retrieve some of the desired hits, such as:
- s2a-021:51_1:A_1 It’s It’s It’s the Davy Crocketts of this world who are needed to parade about on the battlements
Although the ICE corpora are intended for comparison and share standardizing guidelines, when it comes to the nitty-gritty details, standardization is often insufficient, and care needs to be exerted constantly. You will run into issues like these frequently, so we advise you to be aware and not to despair.
The ‘after’ perfect
The possibly best investigated feature of Irish English is the after perfect (e.g. Filppula, 1999: 99 ff.), which is considered to have developed due to contact with Irish Gaelic. Surface search string operationalizations to find this feature in corpora fortunately are simple:
after \w+ingWhile there are 71 hits which include some true positives, the precision of this query is very low. Many of our hits are false positives, such as:
- W2A-011 However, after adopting the approach for one year, I decided to supplement the methodology
But we also get some true positives:
- S1A-046:100:A_ And he’s after coming back from England you know
In order to tauten our search, we can also formulate a more precise query which finds frequent forms of the auxiliary ‘be’ followed by ‘after’ and an ‘-ing’ form.
(m|be|was|is|'s) after \w+ingThis returns eight results, of which six are true positives.
Although we so far looked for after perfect constructions by using key words like “after + ing”, the after perfect can also occur in noun phrases, such as “We’re just after our dinner” or “The baby is just after her sleep”. To search for these, we can use a query like:
after (\w+){1,5} (dinner|breakfast|tea|lunch|sleep|nap|beer|walk)Which gives us a single hit:
- S1A-008:112:A_ I’m not not that long after my dinner
If you are working with tagged data, you do not have to write a sequence of alternatives the way we do here. Instead, you could simply search for ‘after’ followed by an NP tag with several words in between.
And, of course, if you are working with untagged data, you can use a tagger to process your corpus. We do not discuss part-of-speech tagging in detail in this book, but we want to point out that there are tools which allow you to tag your corpora, such as the TreeTagger (https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/).
Singular existential with plural NP
The singular existential (see Hickey, 2005: 121 and Walshe, 2009) is another well-known Irish feature. A simple surface operationalization can be made by the following query:
there 's \w+sThis retrieves 81 hits, of which about two thirds are false positives. True positives including sentences like:
- S1A-027:177:C_ I’m sure there’s loads of cafes saying that they’re the they’re the
- S1A-028:52:C_ But there’s lots of uhm like I mean say if you were going to analyse a a rock face I mean there’s probably only one way you can actually analyse it
The true positives are dominated by sentences containing ‘loads’ and ‘lots’, which can be seen as lexicalized predeterminers, but also abstract nouns and even some animate nouns, as in the last example, can be found.
If we substitute the contraction in our query by ‘is’, we get another 40 hits of, which 4 are true positives, including:
- S1A-038:B_ But there is gates and I would assume
Again, this gives us a sense for how nitpicky regex is, but also demonstrates its usefulness.
[Potentially an exercise re:British and Irish singular existentials]
Outlook/Afterword
…
References:
Anthony, Laurence. 2019. AntConc (Version 3.5.8) [Computer Software]. Tokyo, Japan: Waseda University. Available from https://www.laurenceanthony.net/software
Filppula, Markku. 1999. The grammar of Irish English. Language in Hibernian style. London, Routledge.
Heckendorn, Robert. Regular expression primer.
Hickey, Raymond. 2005. Dublin English: Evolution and Change. Varieties of English around the world. Amsterdam/Philadelphia: Benjamins.
Greenbaum, Sidney. (ed.) 1996. Comparing English Worldwide: The International Corpus of English. Oxford: Oxford University Press.
Schneider, Gerold. 2013. Describing Irish English with the ICE Ireland Corpus. University of Lausanne. Institut de Linguistique et des Sciences du Langage. Cahiers, 38: 137–162.
TreeTagger.
Trudgill, Peter and Jean Hannah. 2002. International English: A Guide to the Varieties of Standard English (4th ed). London, Arnold.
Walshe, Shane. (2009). Irish English as Represented in Film. Frankfurt, Peter Lang.
- Gerold Schneider (2013) compares the ICE Ireland with eight other varieties. Finding three instances of the ‘for to’ infinitive in British English, he argues that the claim that it is an Irish feature merits reassessment. Depending on the results you get with your corpora, this might provide an interesting avenue of research. ↵
- Depending on the corpus interface you are using, it is possible that you have the option of randomizing the results which allows you to simply work with, for example, the first hundred of these randomized hits. ↵
