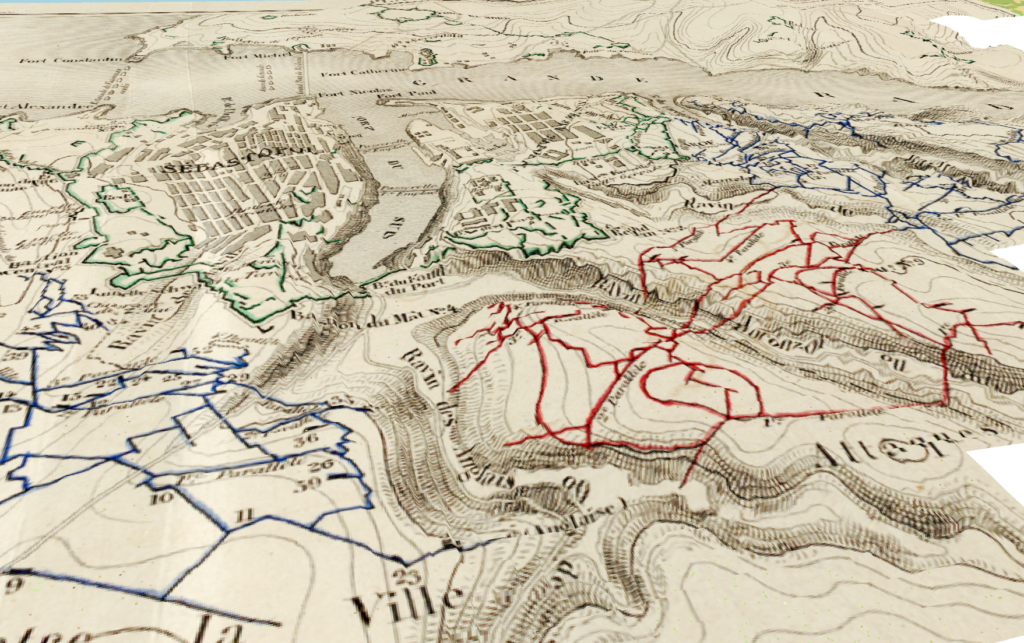
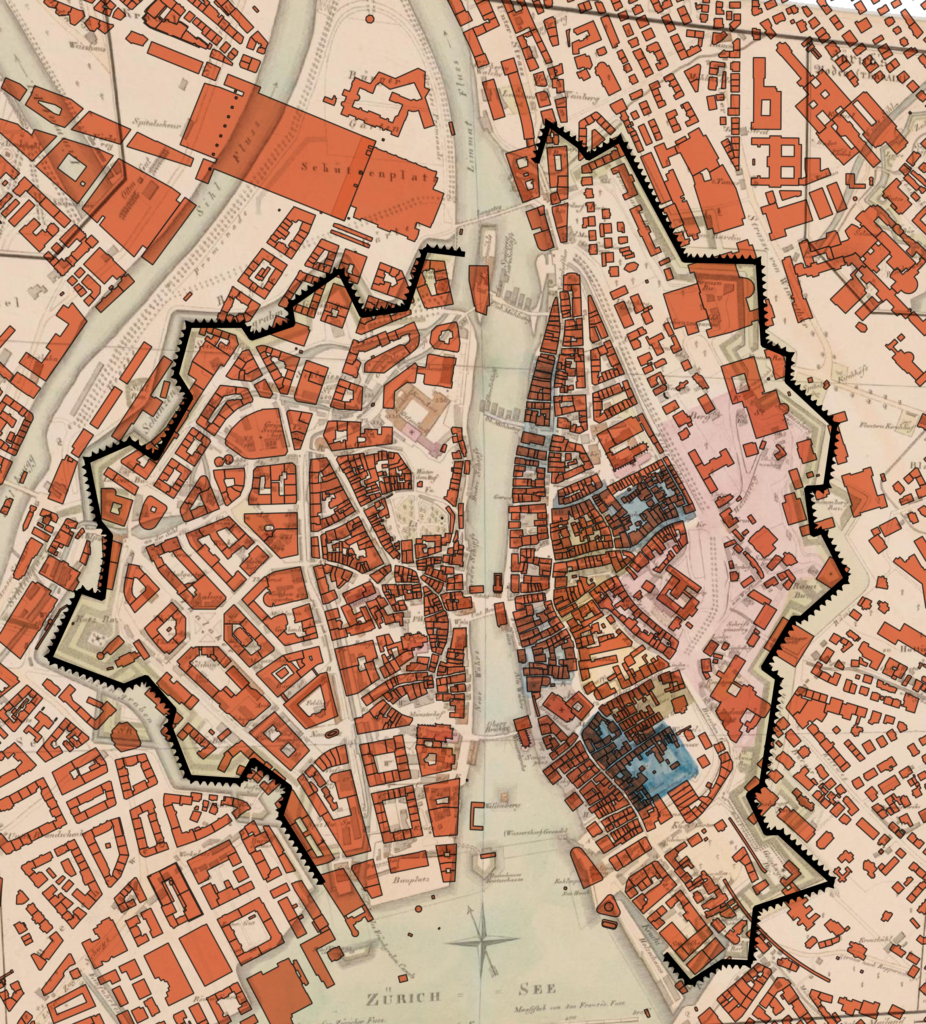
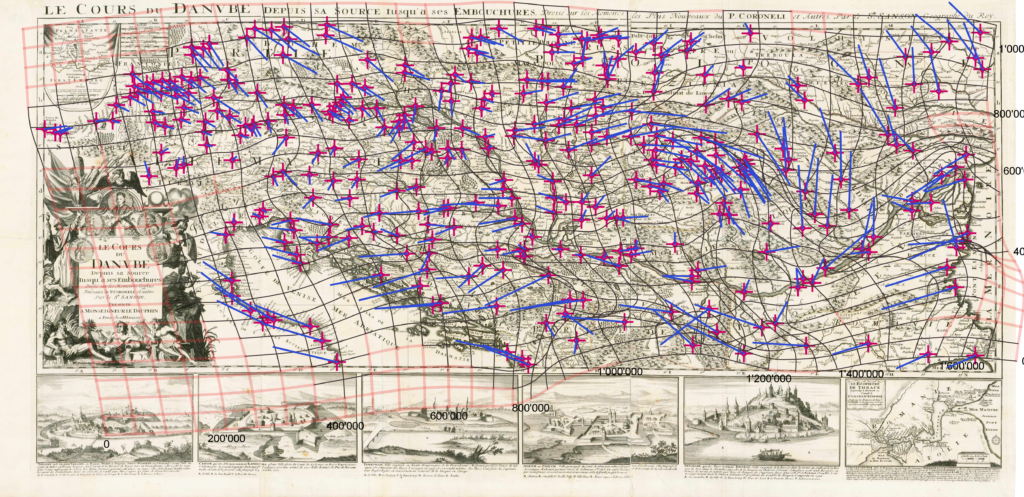
Ein Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät». In einem schriftlichen Interview mit Barbara Flückiger hören wir von den Möglichkeiten von Deep Learning in der Filmanalyse – und noch vieles mehr. In der Reihe geben Lehrende und Forschende der PhF einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen.
Frau Flückiger, bitte stellen Sie sich vor!
Mein Name ist Barbara Flückiger und ich bin Professorin für Filmwissenschaft. Vor meiner akademischen Karriere war ich international in der Filmproduktion tätig. Diesen beruflichen Hintergrund in Engineering und in der Filmpraxis bringe ich nun konsequent in meine filmwissenschaftliche Forschung und Lehre ein, in der ich mich schwerpunktmässig mit technologischer Innovation und ihren Konsequenzen für die Filmästhetik auseinandersetze. 2015 habe ich mit einem interdisziplinären Projekt einen Advanced Grant des European Research Council zur Untersuchung von historischen Filmfarben eingeworben. Ein komplementäres SNF-Projekt setzt sich mit kulturellen Faktoren der Technikgeschichte auseinander. Ausserdem nehmen wir physikalische und chemische Untersuchungen von Filmmaterialien vor.

Obwohl meine Forschung grundlegende Fragen behandelt, sind die Ergebnisse auch für die Anwendung relevant. So entwickle ich mit meinem interdisziplinären Team wissenschaftlich fundierte Methoden für die Digitalisierung des Filmerbes, die sich in technisch avancierten Workflows umsetzen lassen. 2018 habe ich dafür einen Proof-of-Concept des European Research Council erhalten, um die wissenschaftlichen Erkenntnisse auf ihre praktische Umsetzung hin zu untersuchen. Und schliesslich präsentierten wir unsere Forschung mit einer Förderung durch SNF-Agora im letzten Herbst in einer Ausstellung im Fotomuseum Winterthur sowie mit verschiedenen Filmprogrammen einer breiteren Öffentlichkeit.

Was verstehen Sie unter «Digital Humanities»?
Ganz allgemein sind Digital Humanities Verfahren und Werkzeuge, die sich digitaler Methoden zur Bearbeitung geisteswissenschaftlicher Fragestellungen bedienen. Sie haben ihre Grundlagen in computergestützten Analysen, die zunächst in den Sprachwissenschaften für Korpusanalysen Verwendung fanden. Heute sind die Sprachwissenschaften nach wie vor sehr dominant. Ein weiteres relativ gut etabliertes Feld sind digitale Methoden in der Bildwissenschaft. Hingegen ist die Analyse von audio-visuellen Bewegtbildern – also Film und Video – noch wenig verbreitet, obwohl es seit rund 20 Jahren immer wieder Ansätze in diesem Bereich gegeben hat. Wegen des hohen Datenumfangs und des komplexen Zusammenspiels von Bild, Bewegung und Ton sind die Anforderungen in diesem Bereich sehr viel höher, sowohl was die Datenverarbeitung betrifft als auch hinsichtlich der Analyse-Instrumente. In den Digital Humanities kommen sowohl qualitative als auch quantitative Methoden zum Einsatz. Zunehmend basieren diese Werkzeuge auf Deep Learning mit neuronalen Netzen.

Könnten Sie uns eines Ihrer Forschungsprojekte im Bereich Digital Humanities vorstellen?
Derzeit untersuchen wir die Technologie und Ästhetik von historischen Filmfarben sowie die kulturelle Kontextualisierung dieser Entwicklungen mit einem interdisziplinären Ansatz. Im ERC Advanced Grant FilmColors haben wir ein Korpus von mehr als 400 Filmen von 1895 bis rund 1995 mit Ansätzen der Digital Humanities untersucht. In einem weiteren SNF-Projekt kommen nun Animationsfilme und neuere digitale Produktionen dazu, für die wir diese Methoden weiterentwickeln.

Was sind die spezifischen Methoden «der Digital Humanities», die Sie in diesem Projekt anwenden?
Das Fundament für die derzeitigen Projekte legte die Online-Plattform Timeline of Historical Film Colors zu historischen Farbfilmprozessen. Ab 2012 habe ich sie als umfassende interaktive Ressource für alle Aspekte der technischen Grundlagen, ästhetischen Erscheinungsbilder, Identifikation, Vermessung, Restaurierung und ästhetische Analyse aufgebaut, zunächst mit einer Crowd-Funding-Kampagne und eigenen finanziellen Mitteln. Sie umfasst heute mehrere Hundert Einzeleinträge zu den mannigfaltigen Farbfilmverfahren. Inzwischen haben mein Team und ich mit einem eigens dafür entwickelten Kamera-Set-up mehr als 20’000 Fotos von historischen Farbfilmen in Filmarchiven in Europa, den USA und Japan aufgenommen, die wir online in Galerien präsentieren. Diese Plattform ist Teil eines sich weiter ausdehnenden digitalen Ökosystems.
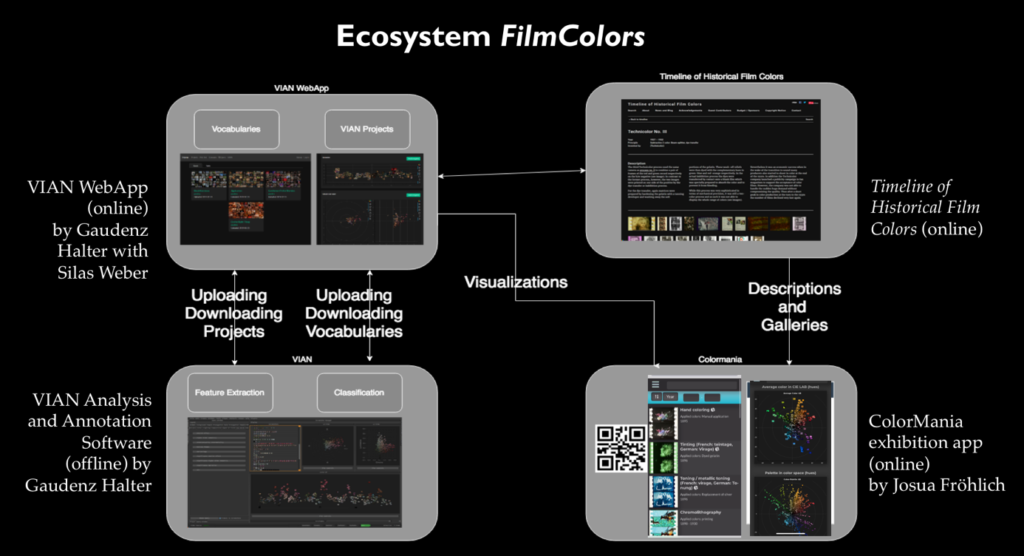
Im ERC Advanced Grant FilmColors entwickeln wir seit 2017 in Zusammenarbeit mit dem Visualization and MultiMedia Lab von Renato Pajarola (IFI UZH) nun das Digital-Humanities-Tool VIAN für die Film-Annotation und -Analyse auch mit Unterstützung durch Digitale Lehre und Forschung, der Digital Society Initiative und Citizen Science. Entwickler ist Gaudenz Halter, der ein fantastisches Werkzeug mit vielen auf die Bedürfnisse der filmästhetischen Forschung zugeschnittenen Features geschaffen hat.
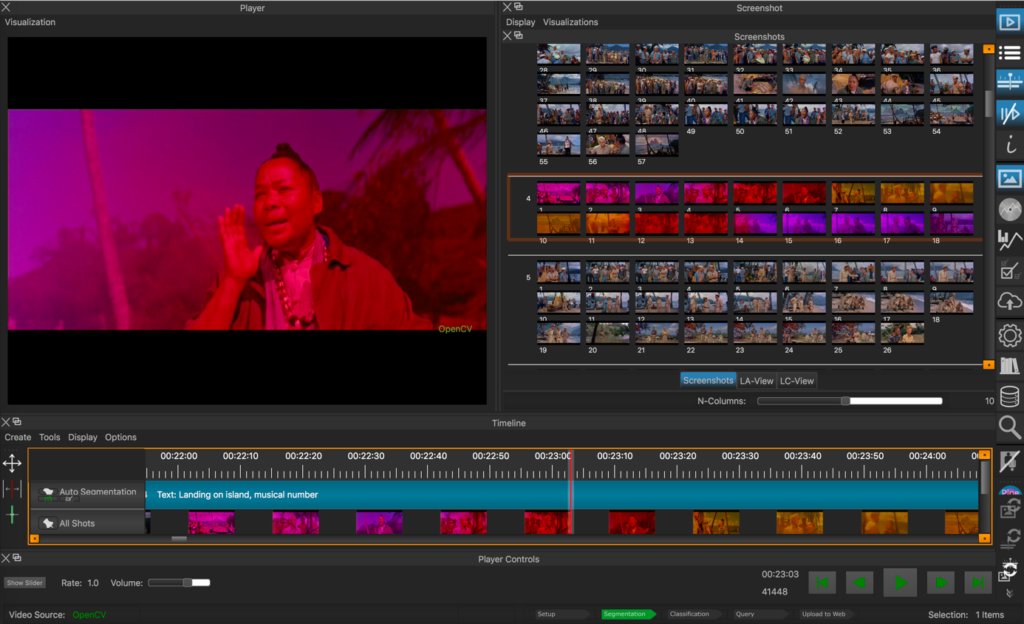
Dieses in Python programmierte Offline-Tool ist mit der Crowdsourcing-Plattform VIAN WebApp verknüpft, die ebenfalls hauptsächlich Gaudenz Halter entwickelt. Dort sind alle Filmanalysen des Korpus für die Auswertung und Visualisierung der Ergebnisse online verfügbar.

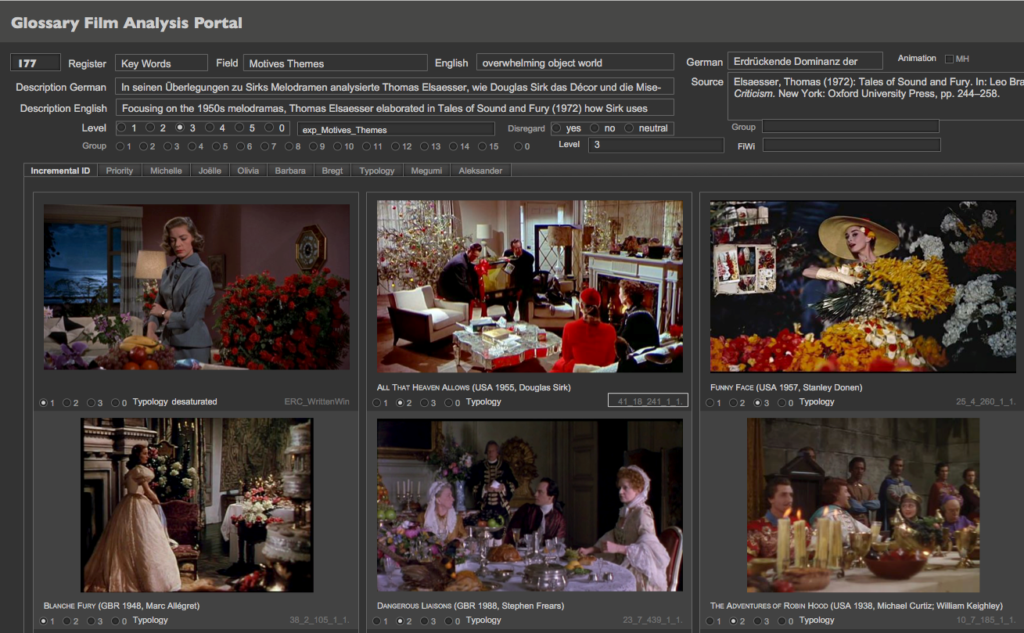
Für die manuelle Annotation haben wir zunächst ein Netzwerk von relationalen Datenbanken in FileMaker erstellt, das ich weitgehend selbst programmierte. So konnte ich sehr flexibel auf Desiderate aus dem Team reagieren. Aus diesen Analysen sind mehr als 170’000 Screenshots und mehr als eine halbe Million Aufsummierungen von Resultaten entstanden. Anschliessend hat Gaudenz Halter alle Resultate in die VIAN WebApp integriert; sowohl als von Menschen lesbare JSON-Dateien wie auch als numerische Werte in HDF5-Daten-Containern.
Welchen Mehrwert bringen Ihnen diese Methoden in diesen Projekten, verglichen mit «analogen» Ansätzen?
Der Mehrwert ist enorm. Ohne solche Ansätze wäre die kollaborative Arbeit an so grossen Korpora gar nicht möglich. Um solche Tools zu entwickeln, ist jedoch eine vertiefte interdisziplinäre Zusammenarbeit zwischen den Geisteswissenschaften und der Informatik notwendig, denn alle Konzepte, alle Auswertungs- und Analysemethoden, alle Ansätze zur Visualisierung der Analysen müssen aus beiden Disziplinen theoretisiert und reflektiert werden.
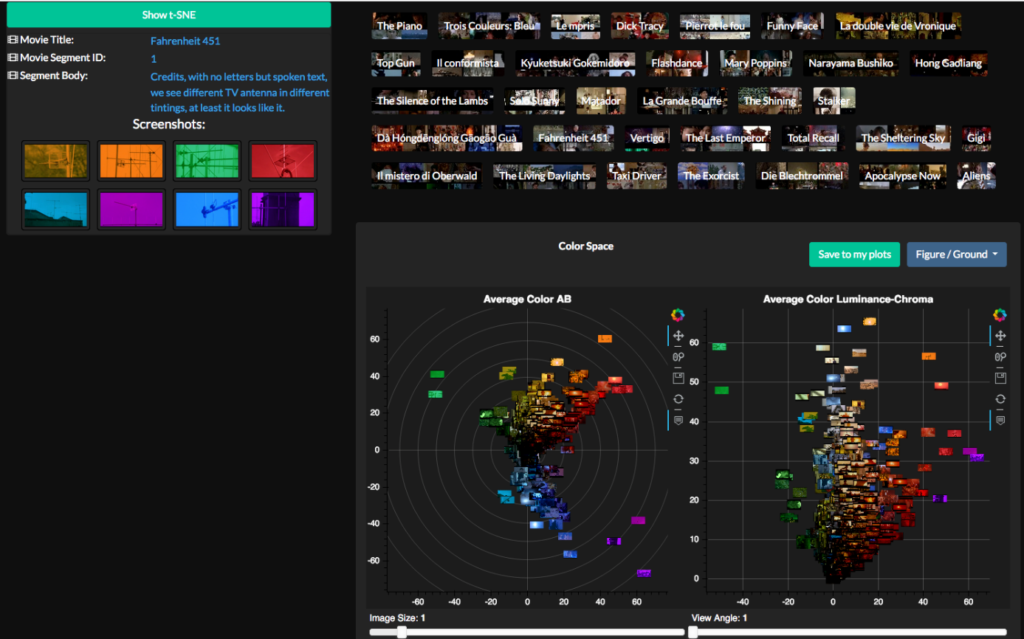
Wenn diese Voraussetzungen gegeben sind, lassen sich über Visualisierungen als diagrammatische Methoden neue Einsichten gewinnen, die den sprachlichen Horizont überschreiten und unmittelbar der Anschauung zugänglich sind. Dies ist für das audio-visuelle Medium Film, aber auch für andere visuelle Gegenstandsbereiche von unschätzbarem Wert; ohne solche Methoden der systematischen Untersuchung bleiben Ergebnisse anekdotisch und abstrakt zugleich. Visualisierungen schaffen also neue Formen von Evidenz.
Allerdings fallen einem die Ergebnisse auch mit solchen hochausdifferenzierten Werkzeugen nicht in den Schoss. Sie bedürfen immer der Reflexion, der Kontextualisierung und der Interpretation. Oftmals sind die Ergebnisse weit weniger eindeutig, als man das gerne hätte, und weder eine reine Auswertung noch eine Visualisierung ist bereits ein Ergebnis, sondern die Resultate bedürfen immer der Interpretation. Als Forschende müssen wir daher Hypothesen bilden und mit neuen Abfragen oder Visualisierungen differenziertere Resultate erzeugen.
Deshalb ist es von entscheidendem Wert, dass wir mit VIAN Ergebnisse und Abfragen interaktiv, basierend auf dem individuellen Forschungsinteresse anpassen können. So erhalten wir nicht nur Übersichtsvisualisierungen, sondern wir können von der Korpusebene in die einzelnen Szenen und Bilder hineinzoomen und sie uns anzeigen lassen, um detailliertere Informationen zu bekommen.
Wären diese Ansätze auch für andere Disziplinen anwendbar?
Ja, wir arbeiten nun mit anderen Fachbereichen aus den Geisteswissenschaften zusammen, unter anderem mit der Kunstgeschichte SARI / Digital Visual Studies von Prof. Dr. Tristan Weddigen und mit der Sprachwissenschaft in LiRI von Prof. Dr. Elisabeth Stark. Diese Tools lassen sich grundsätzlich in allen Disziplinen anwenden, die mit Videos oder grossen Bildersammlungen / Visualisierungen arbeiten, so in der Psychologie / Verhaltensforschung, Ethnologie, Soziologie, Politologie, aber auch in naturwissenschaftlichen Fächern wie der Medizin und den Life Sciences, zum Beispiel der Neurowissenschaft. Es sind derzeit sehr viele solche Kooperationsprojekte national und international in der Pipeline. Da habe ich dieses Jahr eine Menge Arbeit vor mir.
Wie und wo bringen Sie diese Methoden in der Lehre ein?
Wir haben seit letztem Jahr zunehmend externe Nutzer als Betatester integriert. Dies sind Doktorand*innen, PostDocs, aber auch Professor*innen der UZH und ausländischer Universitäten. Die Herausforderung besteht im Support, denn wir müssen einerseits die Usability mit den Betatestern überprüfen, andererseits die Software fortlaufend anpassen. Dafür hat uns DLF eine 20%-Stelle finanziert. Es gibt eine umfassende Dokumentation und wir erstellen Video-Tutorials für die Einführung.
Ich habe soeben einen kompetitiven Lehrkredit beantragt, damit wir VIAN im kommenden Jahr auf Bachelor- und Masterstufe in der Lehre einsetzen können. Denn auch die Dozierenden müssen geschult werden und brauchen Unterstützung. Es ist ein Irrglaube, eine solch differenzierte Software sei selbsterklärend. Obwohl VIAN sehr flexibel und intuitiv ist, muss man den Umgang damit doch lernen, und es braucht etwas Übung, bis man effizient damit arbeiten kann.
Die Studierenden erhalten so Gelegenheit, sich mit digitalen Werkzeugen und Methoden auseinanderzusetzen, neue Kompetenzen in der Anwendung zu erwerben und gleichzeitig aktiv an der Weiterentwicklung mitzuarbeiten, indem sie Feedback geben und ihre Bedürfnisse artikulieren.
Welche technischen Kenntnisse sollten Studierende mitbringen?
Das Interface von VIAN verlangt keine besonderen technischen Kenntnisse, denn es ist spezifisch auf den Einsatz durch Geisteswissenschaftler und für die ästhetische bzw. narratologische Analyse entwickelt worden. Allerdings ist es von Vorteil, wenn man technikaffin ist und gerne am Computer arbeitet. Auch eine Vorstellung von Auswertungen und der Arbeit mit Datenbanken ist von Vorteil, lässt sich aber ohne spezifische Grundkenntnisse im Lauf der Anwendung erwerben.
An der Timeline of Historical Film Colors arbeiten Studierende im Datenmanagement mit und kodieren die Quellen in HTML, die sie danach in das Backend der Plattform einpflegen und mit einem Thesaurus annotieren.
Wo sehen Sie Bedarf an Infrastruktur, Informatik-Grundausbildung oder anderem an der Philosophischen Fakultät, um «Digital Humanities» in Ihrem Fachgebiet betreiben und in der Lehre einbringen zu können?
Die Philosophische Fakultät braucht dringend eine Digital-Humanities-Strategie, sie muss verstehen, dass sie es sich nicht leisten kann, auf diese digitalen Ansätze und Methoden in den Geisteswissenschaften zu verzichten. Diese Strategie muss von der Unileitung gestützt und eingefordert werden, denn die Universität Zürich muss sich im internationalen Feld positionieren. International findet zunehmend ein Wettbewerb um die besten Talente statt; die besten Universitäten der Welt bemühen sich sowohl um die begabtesten Studierenden als auch um herausragende Forschende. Mit der Digital Society Initiative haben wir bereits einen Verbund von exzellenten Professor*innen auf Universitätsebene, in dem ich seit der Gründung dabei bin.
Mit meinem Projekt, SARI / Digital Visual Studies sowie LiRI sind wir in einer guten Ausgangsposition, aber diese Einzelinitiativen müssen in einen übergeordneten institutionellen Rahmen eingebettet werden und vor allem müssen für diese Integration finanzielle Mittel gesprochen werden. Digitale Ansätze sind nicht selbsterhaltend, sie sind einem steten Wandel unterworfen und entwickeln sich dynamisch im Verbund mit Hardware und Trends in anderen Anwendungsbereichen. Um den Erhalt zu garantieren, brauchen wir spezialisierte technische Infrastruktur, wir brauchen Entwickler, die unsere Methoden und Werkzeuge verstehen und umsetzen, wir brauchen interdisziplinär denkende Doktorand*innen und PostDocs, wir brauchen Techniker*innen, die sich mit den Anforderungen der Forschung beschäftigen. Anders als in den Naturwissenschaften, in denen es selbstverständlich ist, dass ein Labor Mittel hat, um die technische Infrastruktur à jour zu halten, sind diese Anforderungen in den Geisteswissenschaften noch wenig präsent. Bei uns ist die Förderung in der Regel projektbasiert. In meinem Fall sind die Mittel aus dem ERC Advanced Grant mittlerweile erschöpft; das bedeutet, dass die Weiterentwicklung des gesamten Ökoystems, das wir um VIAN herum aufgebaut haben, akut gefährdet ist. Dies, obwohl das Interesse an den Werkzeugen – sowohl uniintern als auch international, fachbezogen und fachübergreifend – sehr gross ist. Der Ball liegt nun bei der Universität, die Grundsicherung und langfristige Perspektive für solche Methoden und Tools sicherzustellen. Dafür ist eine strukturierte Kommunikation aller Stufen und Einheiten der Universität notwendig sowie auch die Kommunikation nach aussen, denn dieses Feld ist sehr attraktiv.
Dank meiner Vorarbeiten kommen viele potenzielle nationale und internationale Partner aktiv auf mich zu. Sie wollen sich vernetzen und von den Entwicklungen profitieren. Das begrüsse ich sehr und pflege einen kooperativen und offenen Austausch. Mit dem Joint Digital Humanities Fund haben wir bereits eine etablierte Kooperation mit der FU Berlin sowie neu der Hebrew University in Jerusalem. Wir arbeiten mit einem internationalen Konsortium an Standardisierungen, welche die Interoperabilität der Ansätze und Tools sicherstellen soll und planen ein übergeordnetes Ökosystem, in das diese Werkzeuge integriert werden können.
Das vergangene Semester hat gezeigt, dass die digitale Lehre und Forschung ein unverzichtbarer Baustein für die Weiterentwicklung der Universitäten sind. Die UZH darf den Anschluss nicht verpassen.
Gibt es Fragen, die ich nicht gestellt habe, die für die Diskussion aber wichtig sind?
Ja, meine persönlichen Ressourcen. Ich habe eine Professur ad personam, ohne Stellen. Meine Arbeitsbelastung in den vergangenen Jahren war gigantisch, und es sieht nicht nach Besserung aus. Auch wenn ich über sehr viel Energie verfüge und überraschend zäh bin, muss ich zu viel leisten. Auf Dauer ist das nicht machbar.
Aber ich bin auch eine ziemlich unerschütterliche Optimistin und nehme an, dass sich die Dinge am Ende schon zum Positiven entfalten.
Blog-Post zu VIAN mit weiterführenden Links: https://blog.filmcolors.org/2018/03/08/vian/
VIAN Dokumentation: https://www.vian.app/static/manual/index.html
VIAN Tutorials: https://vimeo.com/user/70756694/folder/1220854
Screenvideos VIAN WebApp:
https://vimeo.com/396548709
https://vimeo.com/402360042
https://vimeo.com/404388151

 Mein Name ist Daniel Ursprung, ich bin wissenschaftlicher Mitarbeiter an der Abteilung für Osteuropäische Geschichte am Historischen Seminar. Dort bin ich in der Forschung und Lehre aktiv – in der letzten Zeit habe ich mich, v.a. im Bereich der Lehre, mit digitalen Technologien und deren Möglichkeiten auseinandergesetzt. Ich möchte den Studierenden einen niederschwelligen Einstieg in diese Technologien ermöglichen.
Mein Name ist Daniel Ursprung, ich bin wissenschaftlicher Mitarbeiter an der Abteilung für Osteuropäische Geschichte am Historischen Seminar. Dort bin ich in der Forschung und Lehre aktiv – in der letzten Zeit habe ich mich, v.a. im Bereich der Lehre, mit digitalen Technologien und deren Möglichkeiten auseinandergesetzt. Ich möchte den Studierenden einen niederschwelligen Einstieg in diese Technologien ermöglichen.