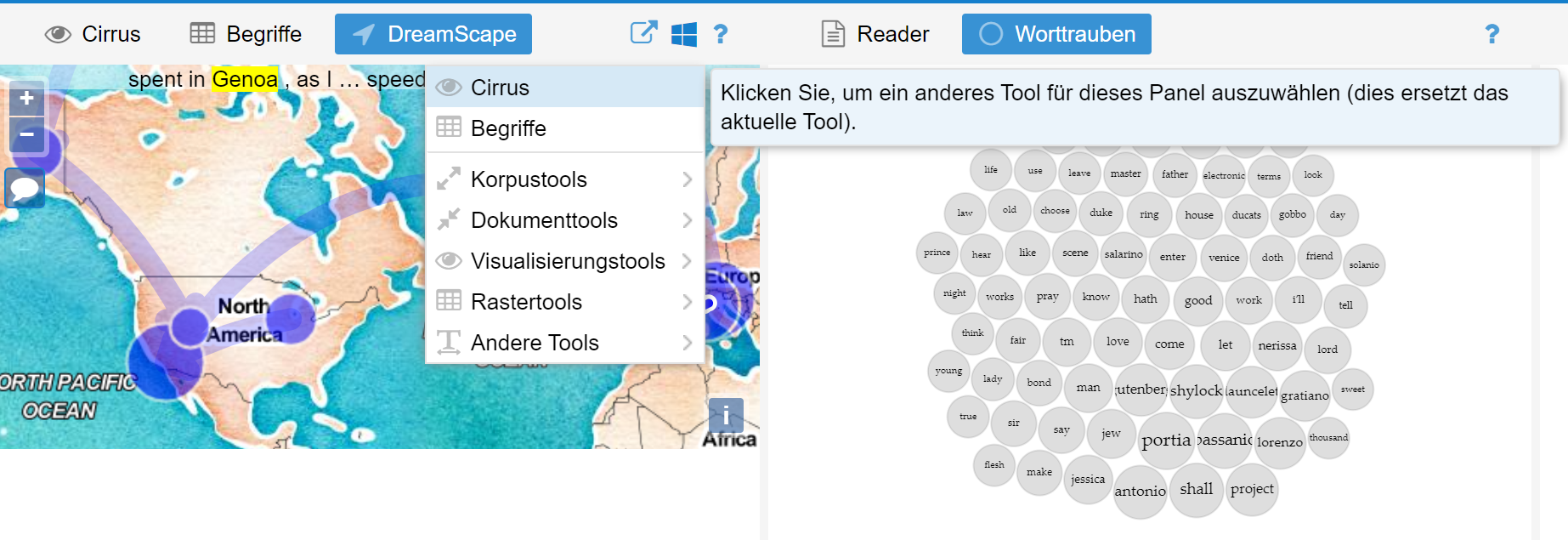
Voyant Tools ist eine browserbasierte open-source Umgebung für die Textanalyse und -visualisierung. Es wurde hauptsächlich konzipiert, um „leichtgewichtige“ Textanalysen schnell und unkompliziert anzubieten, v.a. Worthäufigkeiten, Beziehungen uvm.
Ein hochgeladener Text kann mit unzähligen Methoden des Natural Language Processings (NLP) ausgewertet und visualisiert werden, z.B. mit
Wortwolken oder Worttrauben
Begriffhäufigkeiten
Beziehungsgraphen
Korrelationen
Kontexten
Trends
Bubblelines
uvm.
Fünf Blöcke können auf der Seite frei konfiguriert werden. Dabei wird für jeden Block gewählt, welche Methode bzw. welche Visualisierung dargestellt werden soll. So kann man sich schnell und unkompliziert eine Auswahl zusammenstellen.
Die Visualisierungen werden anschliessend einfach exportiert – als Bild oder HTML snippet, um sie in bestehende Webseiten einbetten zu können
Systemvoraussetzungen: Keine, da browserbasiert. Funktioniert auf jedem Browser.
Vorausgesetzte Kenntnisse: Keine. Die Oberfläche ist intuitiv und auch für Einsteiger geeignet. Will man genauer wissen, wie die Visualisierungen entstehen, sollte man sich ein wenig in NLP auskennen.
Was haben Vektoren mit Sprache zu tun? Martin Volk, Rico Sennrich und Simon Clematide sprechen mit mir über Methoden der Computerlinguistik. In dieser Reihe geben Lehrende und Forschende der PhF uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen. Wir diskutieren den Begriff «Digital Humanities» von ganz verschiedenen Perspektiven aus.
Wir sprechen heute zu viert über Computerlinguistik und Digital Humanities – können Sie sich alle kurz vorstellen?
[Martin Volk, MV]: Starten wir in alphabetischer Reihenfolge…
[Simon Clematide, SC]: Ich bin wissenschaftlicher Mitarbeiter am Institut für Computerlinguistik, ursprünglich studierte ich Germanistik, Informatik und Philosophie. Ich habe also humanistisch angefangen und wurde immer technischer – mein Doktorat machte ich dann in der Computerlinguistik. Ich habe den Wandel der Computerlinguistik mitgemacht von eher wissensbasierten Systemen, in denen man linguistische Kenntnisse brauchte, zu eher statistischen und maschinellen Lernverfahren. Ich sehe mich als Brückenbauer zwischen den geisteswissenschaftlichen und den eher technischen Ansätzen.
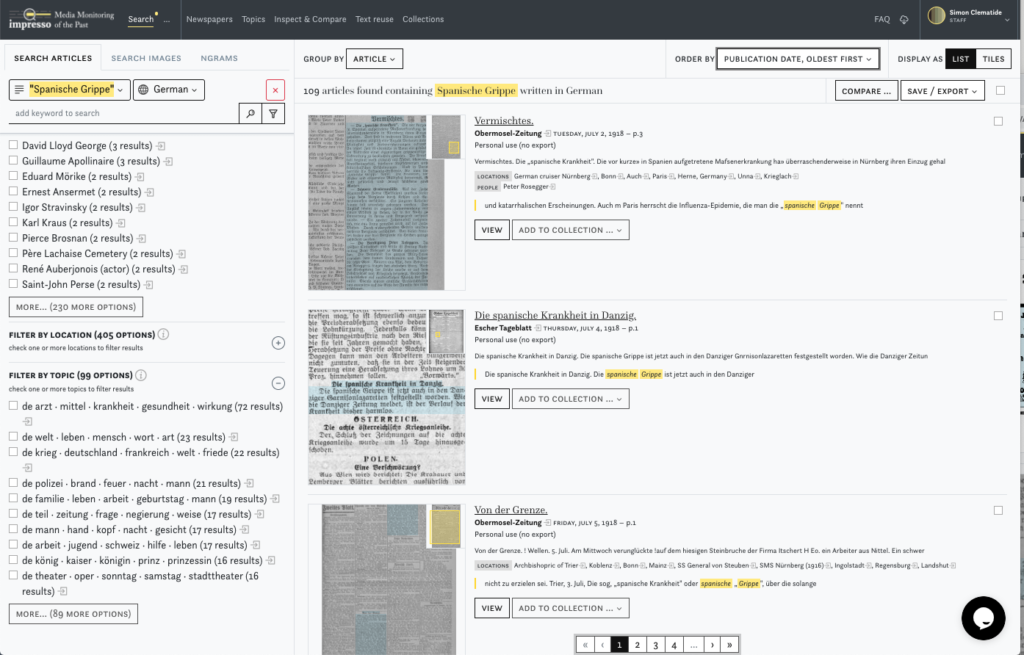
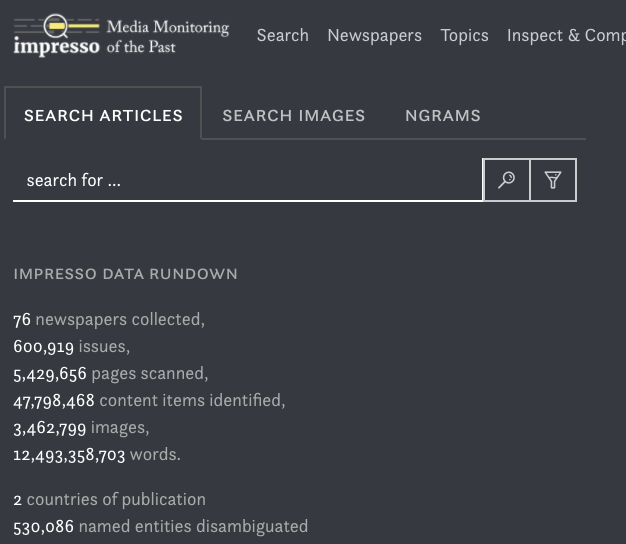
Aktuell arbeiten Martin Volk und ich zusammen mit Forschenden aus den digitalen Geschichtswissenschaften am Projekt Impresso, einem vom SNF unterstütztes Sinergia Projekt, in dem Techniken der Textanalyse, die v.a. für zeitgenössische Dokumente entwickelt wurden, in grossem Stil auf schweizerische und luxemburgische Zeitungen aus den letzten 250 Jahren angewendet werden. Dabei werden die mehrsprachigen Inhalte der Zeitungen möglichst gut indiziert, damit interessierte Personen diese effizient durchsuchen können.
Media Monitoring of the Past: Ausschnitt aus dem Impresso-Projekt
Media Monitoring of the Past: Über 5 Mio. Seiten wurden gescannt, fast 50 Mio. Items identifiziert.
Ein weiteres laufendes Projekt ist der Stellenmarkt-Monitor Schweiz zusammen mit Prof. Marlis Buchmann vom Soziologischen Institut im Rahmen des (Nationalen Forschungsprogramms 77 „Digitale Transformation“): Hier analysieren wir Stellenanzeigen inhaltlich – welche Fähigkeiten werden verlangt, welche Aufgaben werden beschrieben, wie widerspiegelt sich die Technologieentwicklung der letzten Jahre, wie haben sich die Berufe verändert?
Beiden Projekten ist gemeinsam, dass sie eine Textanalyse brauchen und der Text für die Maschine lesbar und interpretierbar gemacht werden muss: Dieses Fachwissen bringen wir mit.
Rico Sennrich
[Rico Sennrich, RS]: Ich bin SNF-Förderprofessor am Institut für Computerlinguistik – meine Forschungsinteressen sind die Anwendung und Entwicklung maschineller Lernverfahren für die Sprachverarbeitung, insbesondere im Bereich Multilingualität. Einerseits geht es hier um die maschinelle Übersetzung, andererseits aber darum, Modelle zu entwickeln, die multilingual funktionieren: Konkret wird ein Modell auf mehreren Sprachen trainiert, so dass es schliesslich besser funktioniert, als wenn man separate Modelle für jede Sprachen trainieren würde. Sogar der Transfer zu Sprachen, für die keine oder nur wenige Texte für eine Anwendung vorhanden sind, ist möglich.
Ich bearbeite nicht direkt geisteswissenschaftliche Fragestellungen, aber die Methoden, an denen ich arbeite, können durchaus auch in den Geisteswissenschaften Anwendung finden. Im Projekt x-stance mit dem Doktoranden Jannis Vamvas ging es dieses Jahr z.B. darum, zunächst Datensätze zu generieren und Modelle zu entwickeln, die multilingual sind. Die Datensätze bestanden aus Kommentaren von Politiker/-innen, die mit Annotationen «positiv/negativ» in Bezug auf bestimmte Fragestellungen versehen wurden. Wir konnten dann zeigen, dass das Modell auf verschiedene Fragestellungen und verschiedene Sprachen trainiert werden kann: D.h. wurde es auf deutsche und französische Kommentare trainiert, hat die Analyse danach auch für die italienischen gut funktioniert.
Gerade solche Methoden können z.B. auch für die Politikwissenschaften interessant sein: Mit wenig Annotationsaufwand können dann Analysen über mehrere Sprachen hinweg betrieben werden.
Martin Volk
[Martin Volk, MV]: Ich studierte in den 80er Jahren Informatik und Computerlinguistik, war in den 90er Jahren Postdoc an der UZH und konnte in dieser Zeit schon mit Simon Clematide zusammenarbeiten. Später war ich einige Jahre als Professor in Stockholm, seit 2008 bin ich als Professor und Institutsleiter am Institut für Computerlinguistik wieder an der UZH. Rico Sennrich war bei uns am Institut Doktorand – wir drei kennen uns also schon einige Jahre.
Meine Forschungsschwerpunkte haben sich über die Jahre etwas verschoben. In den 90er Jahren hatten wir wissens- und regelbasierte Systeme und versuchten, Grammatiken zu schreiben, um die grammatische Struktur von Sätzen z.B. automatisch zu bestimmen: Wo ist ein Prädikat, wo ist ein Subjekt, ein Objekt? Als später die statistischen Verfahren kamen, merkten wir, dass es mit diesen Verfahren viel besser funktioniert.
Eine der Ideen, mit denen ich 2008 aus Schweden zurückgekommen bin, war, die Arbeit an der maschinellen Übersetzung zu intensivieren. Früher war der Aufwand dafür schlicht zu gross: Man musste zehntausende von Wörtern in ein Lexikon eintragen, um Sätze analysieren zu können. Nun können wir Systeme für die Analyse selbst bauen.
Ob dies zum Bereich der Digital Humanities gehört, ist die Frage. Und wenn es schon um Definitionen geht – in Diskussionen über Digital Humanities habe ich einmal gesagt, es sei «doing new things with old texts». Eine Person meldete sich und fragte, was denn mit neuen Texten sei? Meine Antwort war: «Doing new things with new texts» – das ist Computerlinguistik! Das ist aber natürlich meine ganz eigene Sicht auf die Welt…
Ein konkretes Projekt im Bereich Digital Humanities, an dem ich gerade arbeite, ist die Digitalisierung des Bullinger-Briefwechsels: Von Heinrich Bullinger sind ca. 12’000 Briefe erhalten, von denen einige Tausend von der Theologischen Fakultät bereits ediert worden sind – wir versuchen nun, den Rest auch noch zu digitalisieren. Dies geschieht mit automatischer Handschriftenerkennung und maschineller Übersetzung der frühneuhochdeutschen und lateinischen Texte in modernes Deutsch.
Der Übergang von wissensbasierten Systemen zu statistischen – ist dies genau der Wandel von den Lexika mit zehntausenden Einträgen zu maschinellen Methoden, auch Machine Learning Methoden?
[MV]: Genau, und dies kann man gerade am Beispiel der maschinellen Übersetzung gut sehen. In den wissensbasierten, d.h. regelbasierten Systemen musste man diese grossen Lexika, Wörterbücher haben, um überhaupt analysieren zu können, wie ein Eingabesatz aufgebaut ist. Im nächsten Schritt wurde er dann erst in die Zielsprache transferiert, um dann schliesslich einen «gültigen» Satz daraus zu generieren. Da war unglaublich viel Handarbeit involviert, um die Wörterbücher und die Entsprechungsregeln zu erstellen.
Heute braucht man dagegen eigentlich «nur» grosse Mengen an bereits erfolgten Übersetzungen, z.B. zehn Millionen Sätze, die in einer hohen Qualität bereits übersetzt wurden. Daraus kann der Computer dann lernen, wie Übersetzungen zu machen sind.
Entwickeln Sie in der Computerlinguistik diese Modelle für das Maschinelle Lernen selbst?
[RS]: Das ist eine Gemeinschaftsarbeit der Community, und es freut mich sehr, wie offen das Wissen geteilt wird. Es werden stetig kleine Verbesserungen am Werkzeugkasten des Maschinellen Lernens vorgenommen – auch das Institut für Computerlinguistik hat schon Teile dazu beigetragen, die nun auch von anderen Gruppen verwendet werden. Umgekehrt verwenden wir Sachen, die andere beigetragen haben.
Welches «Werkzeug» haben Sie da konkret entwickelt?
[RS]: Bei unserem Beitrag ging es darum, wie Texte für die maschinellen Lernverfahren repräsentiert werden. Intern werden die Texte als Vektoren, also als Zahlen repräsentiert. Aus technischen Gründen muss man dann mit relativ kleinen Vokabularen, d.h. ca. 10’000 Wörtern arbeiten – für die Sprachverarbeitung reicht das nirgends hin, weil wir bei Sprachen mit hunderttausenden oder gar Millionen unterschiedlichen Wörtern arbeiten möchten. Wir haben dann einen Algorithmus entwickelt, um Wörter in kleinere Stücke aufzuteilen, sogenannte «Subworteinheiten», mit denen man später alle Wörter im Vokabular repräsentieren kann. Dieses Tool wird nun fast überall in der Community eingesetzt, wenn es um die Verarbeitung von Sprachen in neuronalen Netzen geht.
[MV]: Dieses Verfahren des «Byte Pair Encoding» wurde am Institut für Computerlinguistik und der Universität in Edinburgh entwickelt – das Paper von Rico Sennrich ist derzeit übrigens eines der meistzitierten Papers in der Computerlinguistik.
[RS]: Das Paper heisst Neural Machine Translation of Rare Words with Subword Units, das tönt vielleicht etwas spezifisch, doch das Verfahren wird auch ausserhalb der maschinellen Übersetzung verwendet, oder auch, wenn es nicht speziell um seltene Wörter geht. Es geht darum, ein offenes Vokabular haben zu können, d.h. alle Wörter repräsentieren zu können, und das mit einem beschränkten Vokabular von Symbolen.
Herr Clematide – verwenden Sie ähnliche Methoden in Ihren Projekten?
[SC]: Nicht konkret dieses Verfahren… Was uns aber verbindet, sind die Vektorrepräsentationen der Wörter, die es nicht einfach gibt, sondern aus grossen Textsammlungen «gelernt» werden müssen. Dies ist sicher die grosse Erfindung der Sprachtechnologie und war ein grosser Treiber des Fortschritts. Es ist ein grosser Bruch in der Art und Weise, wie wir mit Sprache umgehen – mathematische Modelle haben «Überhand» gewonnen.
[MV]: Dazu möchte ich ein Beispiel geben. Auch vor 20 Jahren wurde ein Wort numerisch im Computer repräsentiert. Nimmt man z.B. die Wörter «Haus» und «Gebäude», wurden diese mit einer Bytesequenz repräsentiert – heute haben wir aber eine numerische Repräsentation, mit der man automatisch berechnen kann, dass «Haus» und «Gebäude» bedeutungsmässig sehr eng beieinander liegen, während «Haus» und «Fussball» sehr viel weiter auseinander liegen. Das Neue ist also eine numerische Repräsentation, die die Bedeutungsähnlichkeit repräsentiert – und dies nicht manuell zu machen, sondern aus grossen Textmengen automatisch zu erschliessen.
Was ist eigentlich der Unterschied zwischen Supervised und Unsupervised Learning? Können Sie das für Laien erklären?
[RS]: Der Hauptunterschied ist der, ob man dem Modell schon vorgibt, was es zu suchen hat, oder ob das Modell dies selbst herausfindet. Konkret heisst das: Beim Supervised Learning gebe ich dem Modell ein Set von Annotationen – nur dieses Set kann es als Output produzieren. Beim Unsupervised Learning wird eine Datenmenge eingegeben, das Modell findet dann vorhandene Strukturen selbst, nimmt also ein Clustering ähnlicher Wörter vor.
[MV]: Wenn der Computer lernen soll, wo im Text ein Personenname steht, kann man entweder hingehen und in einigen Texten manuell sagen: Das ist ein Personenname, das ist einer, etc., markiert also um die 10’000 Personennamen. Dies ist dann ein supervisiertes Datenset. Der Computer kann daraus dann lernen, was Personennamen sind und in welchen Kontexten sie vorkommen. Dadurch kann er schliesslich Namen erkennen, die so noch nie vorgekommen sind – weil sie in ähnlichen Kontexten vorgekommen sind.
Was ist die spezielle Schwierigkeit bei einer multilingualen Analyse, oder besser gesagt: Was ist anders als bei einsprachigen Modellen?
[RS] Es geht um die Frage, wie man zu den Annotationen kommt. Wir haben gehört, dass hier oft die Arbeit von Menschen dahintersteckt, das macht es manchmal etwas unausgewogen: Bei gewissen Sprachen gibt es annotierte Daten für verschiedenste Fragestellungen, bei anderen wiederum fast gar nichts. Im Projekt x-stance, von dem wir bereits gehört haben, haben wir die Annotationen bestehender Datensätze extrahiert: In der smartvote-Plattform, von der die politischen Kommentare stammen, gibt es eine numerische Klasse für die Aussagen «Ja, ich stimme zu», «Nein, ich stimme nicht zu». Für Deutsch konnten wir 50’000 Kommentare extrahieren, für Französisch 15’000, bei Italienisch waren es dann nur noch 1000. Mengenmässig gibt es also einen grossen Unterschied. Maschinelle Lernverfahren sind recht datenhungrig – wenn wir uns nur auf Italienisch stützen würden, hätten wir Schwierigkeiten. Was Martin Volk mit «Haus» und «Gebäude» zuvor angesprochen hat, kann man auch mehrsprachig machen: So sind «Haus» und «casa» inhaltlich ebenfalls sehr nahe beieinander. Wenn man die Ähnlichkeiten einmal hat, kann man das Modell auf den deutschen und französischen Daten trainieren und bekommt recht gute Ergebnisse auch für die italienischen Datensätze. Im Moment sind die Ergebnisse für Italienisch 70% korrekt, das ist wahrscheinlich für Politikwissenschaftler/-innen noch nicht gut genug – aber wir machen Fortschritte.
Können diese Modelle für die geistes- oder sozialwissenschaftlichen Disziplinen ohne Anpassungen weiterverwendet werden oder muss da jede Disziplin ein spezifisches Modell entwickeln?
[SC] Die Geisteswissenschaften gehen häufig mit traditionellen intellektuellen Methoden an ein Thema heran, manchmal denken sie dann, man könne mit den Methoden der Sprachtechnologie «die mühsamen Arbeiten» effizienter erledigen. Wir wissen, dass die Methoden aber immer auch Fehler produzieren – die Sprache ist einfach zu kompliziert. Deshalb ist das Stichwort «Co-Design» in diesem Zusammenhang wichtig: Wir, die «Technologen», müssen die Methoden auf die echten Probleme und Fragestellungen der Geisteswissenschaftler/-innen hin anpassen. Sie müssen im Gegenzug sehen, dass man ihre Forschungstradition nicht immer «tel quel» automatisieren kann.
[MV] Wir können natürlich nicht über geisteswissenschaftliche Fragestellungen entscheiden, doch dazu einladen, die Chancen zu sehen, wenn wir ihnen helfen, z.B. nicht nur 100 Bullinger-Briefe zu analysieren, sondern 12’000.
Würden Sie denn auch sagen, dass der Mehrwert für die Geistes- und Sozialwissenschaften dann ist, dass man einerseits diese riesige Menge verarbeiten kann, aber auch ganz neue Cluster erkennt, die man mit einer kleinen Auswahl nicht erkannt hätte?
[MV] «Menge» klingt immer ein wenig nach quantitativ statt qualitativ… Ich würde eher argumentieren, dass die grosse Menge besser empirisch abgestützte Ergebnisse ermöglicht. Bei 100 Briefen kann man sicher eine sehr genaue Aussage über diese 100 Briefe machen, aber über die Gesamtheit der Briefe kann man gar keine Aussage machen, höchstens spekulieren. Durch die Verfahren, die wir einbringen, wird das Ergebnis fundierter, weil man die Hypothesen über die Gesamtheit prüfen kann.
Wie kommen die Kollaborationen mit den anderen Instituten überhaupt zustande – funktioniert das über einzelne Forschungsprojekte oder gibt es eine Plattform, wo man sich vernetzen kann?
[MV] Ich bekomme ungefähr jede zweite Woche eine Anfrage für Kollaborationen innerhalb und ausserhalb der UZH. Viele Anfragen müssen wir ablehnen – allein aus Ressourcengründen. Glücklicherweise hat uns die Universitätsleitung eine Förderung für eine Sprachtechnologie-Beratungsstelle zugestanden. Diese hat am 1. September ihre Arbeit aufgenommen, das Text Crunching Center unter der Leitung von Gerold Schneider. Diese Stelle ist dafür da, andere Institute und Seminare der UZH, aber auch Partner von ausserhalb zu unterstützen, Dienstleistungen anzubieten, Projekte aufzugleisen…
Sehr schön, darüber werden wir sicher in einem späteren Beitrag noch berichten! Wie sieht es denn mit der Infrastruktur aus, gibt es eine Zusammenarbeit mit S3IT, die an der UZH «Rechenpower» anbietet?
[MV] Ja, Rico Sennrich ist dort im Aufsichtsrat mit dabei… S3IT kann Hardware zur Verfügung stellen oder eine Software-Empfehlung geben, doch die Art von Knowhow, die wir in der Sprachtechnologie anbieten können, wird nicht von S3IT abgedeckt. Diese Lücke wollten wir mit dem Text Crunching Center füllen. Dabei soll erwähnt werden, dass auch LiRI, die Linguistic Research Infrastructure, ähnliche Dienstleistungen und Beratung anbietet.
In der Computerlinguistik werden Programmierkenntnisse schon auf Bachelorstufe unterrichtet – natürlich. Denken Sie, dass dies auch für andere Disziplinen wichtig wäre?
[MV] Wir beobachten hier schon einen Wandel an der UZH. Alle Studierenden, die den Monomaster Linguistik absolvieren – selbst, wenn sie sich z.B. eher für Historische Sprachwissenschaften interessieren – müssen jetzt neu Programmieren lernen. Auch in der Weiterbildung, z.B. im Studiengang Bibliotheks- und Informationswissenschaft, den die Zentralbibliothek Zürich durchführt, wird ab dem nächsten Durchgang Programmieren gelernt: Von der Einführung in Python bis hin zu Datenstrukturen, etc. Die Anzahl der Personen, die zumindest ein technisches Grundwissen haben werden, wird sich vergrössern.
Wie grenzen Sie sich von der Linguistik ab, wenn dort nun auch programmieren gelernt wird?
[MV] Unsere Fragestellungen sind sehr ingenieurwissenschaftlich ausgerichtet: Wie kann ich einen Algorithmus effizienter machen, wie kann ich eine Repräsentation mächtiger machen, etc.? Das interessiert die Linguisten nicht unbedingt, wenn die Fragestellung ist, ob Sprache X in Indonesien mit Sprache Y in Indien verwandt ist. Das heisst, dass die grundlegenden Fragestellungen andere sind. Uns geht es um die Werkzeugentwicklung und die Effizienz der Werkzeuge. In der Anwendung dieser Werkzeuge in den unterschiedlichen Szenarien, die wir eben vorgestellt haben, gibt es dann Bereiche, die sich überschneiden.
Wir haben zu Beginn schon eine Definition von Digital Humanities von Martin Volk gehört – wie sehen Sie das, Simon Clematide und Rico Sennrich? Was ist das für Sie und «machen» Sie überhaupt Digital Humanities?
[RS] Für mich sind Digital Humanities geisteswissenschaftliche Fragestellungen mit digitalen Methoden, vielleicht mit der Ausnahme der Linguistik. Wenn es linguistische Fragestellungen mit digitalen Methoden sind, passt das auch in die Computerlinguistik. Die Fragestellungen, mit denen ich mich beschäftige, gehören nicht direkt zu den Digital Humanities, da ich eher an den Werkzeugen arbeite.
[MV] Die Arbeiten zur maschinellen Übersetzung, die wir in den letzten 15 Jahren gemacht haben, kann man nicht zu den Digital Humanities im engeren Sinne rechnen, das sind z.T. sehr anwendungsbezogene Fragestellungen, teilweise haben wir auch Grundlagenforschung gemacht. Wird die maschinelle Übersetzung aber angewendet, um die Bullinger-Briefe zu übersetzen, würde ich sagen, dass dies eine Fragestellung der Digital Humanities ist. Für mich ist es immer am Nützlichsten, mir die historische Dimension vorzustellen: Dort sind wir im Bereich der DH, während wir eher im Bereich Computerlinguistik sind, wenn wir an kontemporären Materialien arbeiten. Doch ich weiss, dass viele gerne das Label «Digital Humanities» auch für aktuelle Fragestellungen bzw. Fragestellungen zu aktuellen Texten verwenden – da will ich mich nicht streiten.
Ich habe ursprünglich Germanistik, Neuere Literatur studiert. Gehören dann z.B. textanalytische Fragen im Bereich der Neueren Literatur für Sie auch nicht zu den Digital Humanities?
[MV] Die Arbeiten, die wir Computerlinguisten für die Fragestellung machen würden, sicher nicht, dies wäre eine sprachtechnologische Fragestellung. Was aber für Sie als Germanistin interessant ist, das kann dann durchaus Digital Humanities sein, weil das vielleicht ganz neue Zugänge in Ihrem Feld sind…
Herr Clematide, möchten Sie dazu auch etwas ergänzen?
[SC] Wenn wir Methodenentwicklung machen, ist das Interesse, welche konkrete Fragestellung damit gelöst wird, nicht ganz so wichtig für uns. Man zeigt mit einem Datenset, dass die Methode z.B. 2% besser funktioniert als die andere – das Forschungsinteresse ist ein anderes.
Zum Glück ist «Digital Humanities» ein Kaugummi-Begriff, es gibt eine Community, die sich an Digital Humanities Konferenzen trifft. Die Richtung wird eher sein – denke ich -, dass es in Richtung «Digital Scholarship» geht und jedes Fach ein digitales Toolset aufbauen und in ihre Grundlagenmethoden einbauen wird.
Auch wenn wir eher Methodenentwickler sind, sind wir doch transdisziplinär interessiert – unsere Forschung soll ja nicht für die Schublade sein, sondern auf die Bedürfnisse unseres Gegenübers angepasst werden. Was den Prozess des «Co-Designs» betrifft, sehen wir im Moment sicher eine Professionalisierung und Institutionalisierung an der UZH: Mit dem Institut für Computerlinguistik für die Methodenentwicklung, dem Text Crunching Center für Beratungen, S3IT für die Hardware – die ganze Landschaft hat sich wirklich professionalisiert, und es wird spannend sein zu sehen, wie das Früchte trägt.
Haben wir etwas noch nicht besprochen?
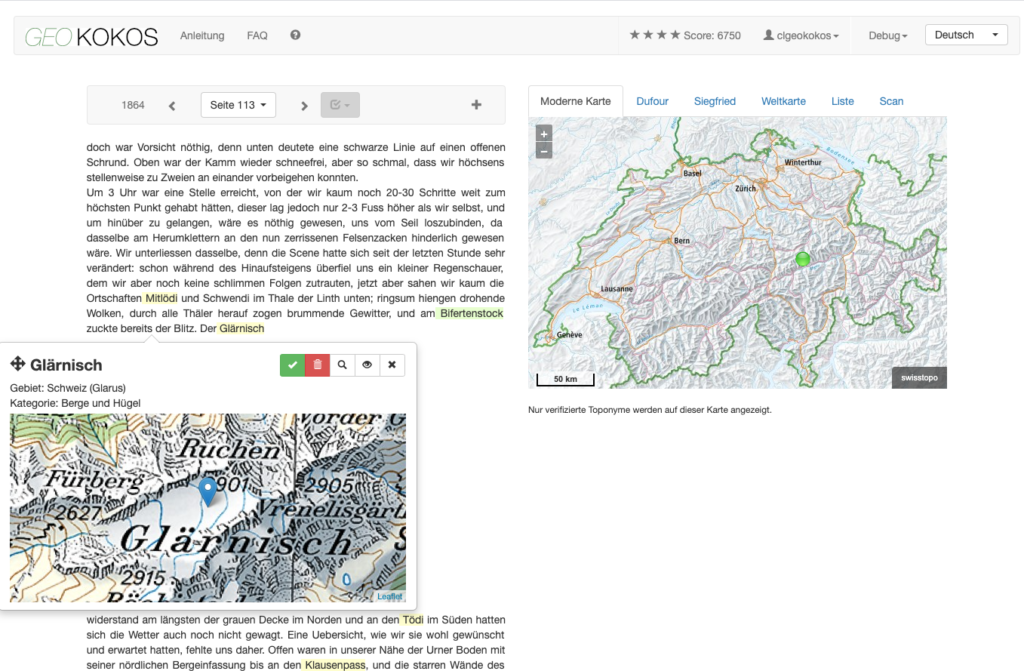
[MV] Ja, eine Sache möchte ich noch unterbringen. Es ist ein Projekt, das uns im Bereich Digital Humanities ein wenig bekannt gemacht hat: Text+Berg digital. Dabei handelt es sich um ein Digitalisierungsprojekt, das wir 2008 gestartet haben. Wir haben die Jahrbücher des Schweizer Alpen-Clubs SAC digitalisiert und aufbereitet. Es entstanden daraus schöne Kooperationen, einerseits mit dem SAC, aber auch mit dem Geographischen Institut, die vor allem an den geographischen Referenzen in den Texten interessiert waren: Gletschernamen, Bergnamen usw.
Aus dem Text+Berg-Projekt entstanden: Die Crowdsourcing-Applikation GeoKokos mit den Texten der Jahrbücher, in der Toponyme annotiert und mit geographischen Referenzen verknüpft werden können.
Patricia Scheurer hat dazu in der Germanistik eine schöne Dissertation verfasst, in der sie sich mit den Metaphern rund um den Begriff «Berg» beschäftigt hat. Ebenso gab es eine Reihe schöner Arbeiten in der Computerlinguistik selbst. Für mich ist es ein schönes Beispiel, wie die Ressourcenerstellung durch uns (die Aufbereitung der Texte) zu einer unglaublichen Menge von Kollaborationen in verschiedenen Disziplinen geführt hat.
Digitalisierte Karten mit Ad Fontes und Digital Mappa – Karten und Lernwege für die Lehre. In diesem Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät» stellen uns Judith Vitale, Privatdozentin am Historischen Seminar, und Nobutake Kamiya, wissenschaftlicher Bibliothekar am Asien-Orient-Institut, ihr Lehrprojekt mit Ad Fontes und Digital Mappa vor. In der Reihe geben Lehrende und Forschende der PhF uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen. Wir diskutieren den Begriff «Digital Humanities» von ganz verschiedenen Perspektiven aus.
Bitte stellt Euch vor, Judith Vitale und Nobutake Kamiya!
[Judith Vitale, im Folgenden JV] Ich bin Privatdozentin am Historischen Seminar und unterrichte Geschichte der Neuzeit. Da ich zu japanischer Geschichte forsche, habe ich Nobutake Kamiya von der Japanischen Bibliothek des Asien-Orient-Instituts kennen gelernt – er ist immer sehr hilfsbereit, wenn es um japanische Bücher geht. Aus dieser Bekanntschaft hat sich ein gemeinsames E-Learning Projekt entwickelt, das wir später noch vorstellen werden.
[Nobutake Kamiya, im Folgenden NK] Ich bin wissenschaftlicher Bibliothekar in der Bibliothek des Asien-Orient-Instituts und habe Judith – wie schon gesagt – durch ihr Forschungsgebiet kennengelernt. Ich interessiere mich sehr für Digitales – die Bibliothek bekommt auch zunehmend digitale Materialien.
Was für digitale Materialien habt Ihr in der Bibliothek?
[NK] Wir haben z.B. Karten aus der Edo- und Meiji-Zeit, Flyers aus dem 2. Weltkrieg und weitere alte Materialien, die wir in der Bibliothek lange behalten möchten. Ein Teil dieser Materialien, Karten und Flyer, sind zuerst zum Zweck der Langzeitarchivierung digitalisiert. Die digitalisierten Flyers sind über den Bibliothekskatalog zugänglich. Die digitalisierten Karten habe ich mit IIIF Standard online zur Verfügung gestellt. Wir haben aber nicht nur eigenen Bestand, sondern geben auch Zugriff auf Digitalisiertes im Internet, vieles stammt aus Japan. Einige Bibliotheken bieten digitalisierte Bilder oder Karten frei an – so werden diese Materialien ganz einfach zu benutzen.
Ein Digitalisat mit IIF Viewer der National Diet Library in Japan.
Was ist denn ein gemeinsames Projekt, wie seid Ihr auf die Idee gekommen, zusammen zu arbeiten?
[JV] Wie ich mich erinnere, erwähnte Nobutake, dass die Bibliothek alte japanische Karten besitze, die er in der Zentralbibliothek Zürich digitalisieren lassen hat. Dabei ging es darum, die Karten zu schützen und zu erhalten. Da der Bibliothekskatalog NEBIS aber nicht darauf ausgerichtet ist, Digitalisate im Internet zur Verfügung zu stellen, habe ich vorgeschlagen, diese Digitalisate in Ad Fontes als E-Learning Modul zu verwerten.
Ein Digitalisat, mit einem IIF Viewer publiziert von Nobutake Kamiya. Mit dem Viewer lässt sich weit in die Karte hineinzoomen.
Was ist Ad Fontes – kannst Du das den Leserinnen und Lesern vorstellen?
[JV] Ad Fontes wurde am Historischen Seminar entwickelt, mit Hilfe und Finanzierung von Digitale Lehre und Forschung (DLF). Man findet darauf Einführungen und Übungen zu europäischen Manuskripten, die als «Lernprogramm», Lernpfad durchgearbeitet werden können. Es geht darum, diese alten Urkunden oder Briefe lesen zu lernen, auch die Schriften.
Die digitalisierten Karten wollten wir nun auch auf Ad Fontes zur Verfügung stellen, so dass sie einerseits nicht nur Wissenschaftlerinnen und Wissenschaftlern zugänglich sind, sondern auch mehr Aufmerksamkeit erhalten. Wir haben die Karten in Leseübungen integriert, so dass auch Studierende damit in Berührung kommen können.
[NK] Andere Bibliotheken besitzen vielleicht die gleichen Drucke, diese sind aber noch nicht digitalisiert. In dem Sinne bieten wir hier eine seltene Dienstleistung, auch für die Öffentlichkeit, an. Es wäre schön gewesen, diese Digitalisate z.B. über e-rara, einer an der ETH Bibliothek angesiedelten Plattform, anzubieten, doch dazu wäre es nötig gewesen, dass die gesamte Institutsbibliothek des Asien-Orient-Instituts eine Mitgliedschaft beantragt, nicht nur eine einzelne Abteilung. Dies ist schliesslich, auch aus finanziellen Gründen, leider nicht zustande gekommen.
[JV] Ad Fontes ist nun ganz frei der Öffentlichkeit zugänglich, nicht an eine Immatrikulation an einer Universität gebunden. Man kann sich neben einem AAI Login auch als «einfache» Benutzerin registrieren und darauf zugreifen.
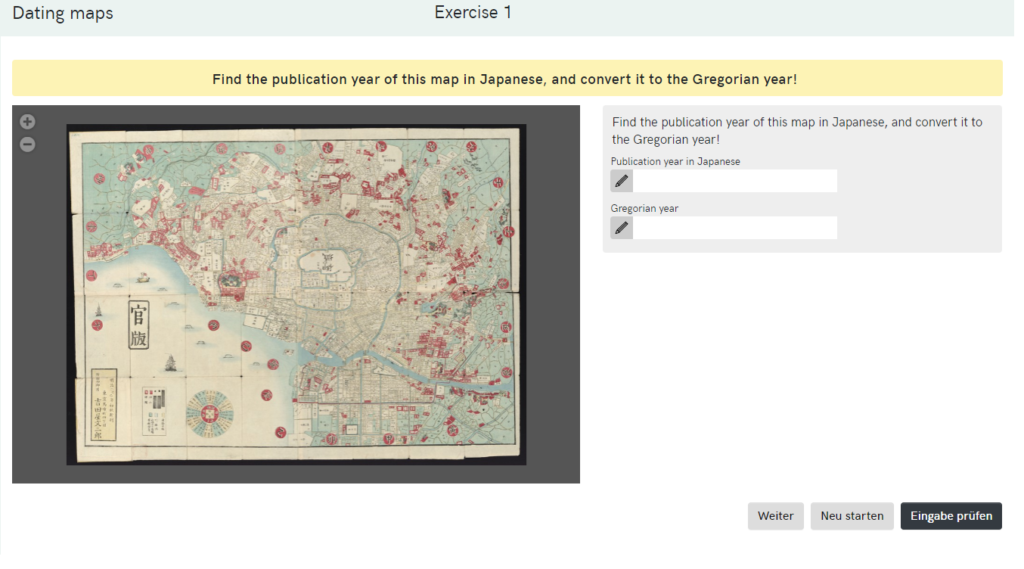
Eine Übung zur Datierung von Karten in Ad Fontes …
… mit der Lösung.
Ad Fontes wurde ja 2018 mit Hilfe von DLF Fördermitteln komplett neu programmiert und bietet erst seither die Möglichkeit, hochauflösendes Bildmaterial mit aufzunehmen. Ist auch die Integration des Kartenmaterials erst seither möglich?
[JV] Genau, wir haben gleich Ende 2018 auch bei Digitale Lehre und Forschung einen Förderantrag für die Umsetzung dieser Lerneinheit eingereicht und sie dann 2019 umgesetzt. Generell ist durch die Neuprogrammierung die Usability viel besser geworden, auch im Admin-Bereich, wo wir die Lerneinheiten zusammenstellen. Der zweite grosse Vorteil ist, dass man seither IIIF Bilder einbinden kann. [Anm. LC: IIIF Bilder sind Bilder, die nach Standards des International Image Interoperability Frameworks im Internet publiziert sind. Der IIIF Viewer macht es erst möglich, sehr hoch aufgelöste Bilder einzubinden und v.a. darzustellen. Mit diesem Viewer kann man sehr weit hinein zoomen und das Material in einem grossen Detaillierungsgrad betrachten.
Was machen die Studierenden nun konkret mit diesem Kartenmaterial, welche geisteswissenschaftlichen Methoden sollen sie anwenden?
[JV] Bei Ad Fontes geht es darum, eine Einführung in das Arbeiten mit historischen Quellen zu geben. Unsere Übung ist in gewisser Hinsicht einmalig, weil wir darauf aufmerksam machen, dass Quellen nicht nur in Archiven aufbewahrt werden, sondern häufig auch in Bibliotheken, häufig sogar als Leihmaterial. Natürlich geht es v.a. auch darum, den Umgang mit Karten als historischen Quellen zu lernen. Die Benutzer/-innen sollen lernen, diese zu betrachten, sie als Text-Bild-Symbol-Systeme zu erkennen: Einerseits kann man alte Schriftzeichen lesen lernen, andererseits auch eine kunsthistorische Perspektive kennenlernen. Welche Funktion haben ausserdem ornamentale Bilder in Karten? Auf der Ebene der Symbole soll man ein bisschen «historische/-r Geograph/-in» sein, indem man z.B. Schraffierungen oder Schifffahrtswege erkennen lernt.
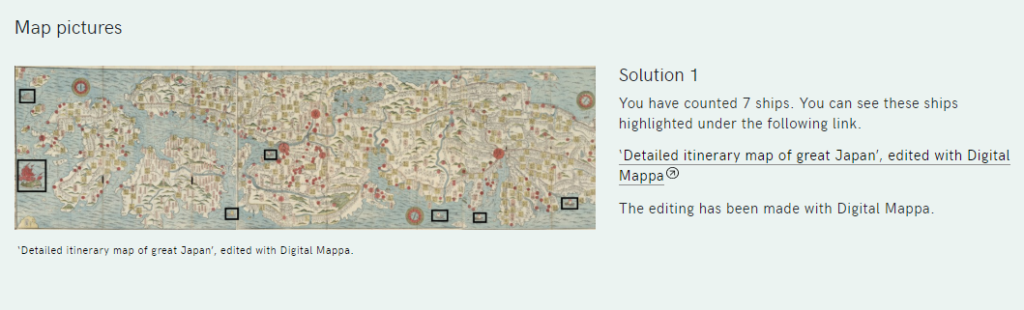
In dieser Übung müssen z.B. Schiffe erkannt und markiert werden.
Die eigenen Markierungen werden angezeigt – ermöglicht wird dies durch das Tool Digital Mappa, das hier in Ad Fontes integriert ist.
[NK] Heute kann man schon vieles Kartenmaterial digitalisiert im Internet finden, es ist aber sehr zerstreut. Deshalb finde ich es gut, dass wir in Ad Fontes eine Quellensammlung erstellen konnten. Natürlich bringt das ein Copyright-Problem mit sich: Ich finde es wichtig, dass man lernt, Quellen zu finden, aber auch mit der Wiederverwendung der digitalen Medien richtig umzugehen. Das wird sicher in Zukunft noch wichtiger, und deshalb zeigen wir das auch in unserem Modul.
Ein Beispiel eines Tutoriums, das in ein Thema einführt.
Brauchen die Studierenden für diese Lerneinheit andere als «nur analoge» Kenntnisse, um sie nutzen zu können?
[JV] Wir sind dem klassischen Aufbau von Ad Fontes gefolgt, dieser enthält verschiedene Einheiten: Tutorials, die in die Geschichte der Karten einführen, dann die Ressourcen, d.h. eine Zusammenstellung einer Bibliographie und wichtigen Datenbanken. Ausserdem einen Übungsteil, in dem Fragen zu den Karten gestellt werden. In diesen Teilen benötigen die Studierenden keine speziellen technischen Kenntnisse. Ein Alleinstellungsmerkmal ist aber, dass wir Digital Mappa integrieren möchten: Das ist ein Quelleneditionstool, entwickelt von der University of Wisconsin, mit dem man alte Karten oder Manuskripte edieren kann.
[LC] Genau, ein Prototyp wurde bereits durch Digitale Lehre und Forschung auf einem eigenen Webserver für Digital Humanities Tools in Betrieb genommen, eine definitive Inbetriebnahme ist per Herbst 2020 geplant. Ein grosser Vorteil dieses Tools ist auch, dass man die Quellen annotieren und auch kollaborativ in Teams arbeiten kann.
Wie würdet ihr denn den Mehrwert beschreiben, den ihr durch die Digitalisierung erhaltet?
[NK] Zunächst einmal ist es schlicht möglich, das Material auch anzusehen – ortsunabhängig. Ausserdem schützt die Digitalisierung das Material, das sonst durch die Verwendung abgenutzt würde. Wenn man in den vorhandenen Tools gewandt ist, kann man die Quellen viel besser präsentieren, annotieren usw., d.h. die eigenen Forschungsergebnisse sehr attraktiv darstellen. Das Wissen wird so kostenlos und frei ins Allgemeinwissen eingeschlossen. Das sind für mich die grossen positiven Punkte. Man weiss dann, dass das Internet zum gemeinsamen Wissen beiträgt.
Wenn man das Kartenmaterial darüber hinaus auch noch mit Geodaten versehen kann, kann man die historischen Quellen zusammen mit anderem Kartenmaterial verknüpfen und darstellen. So gibt es auch viele neue Erkenntnisse.
[JV] Ich schliesse mich Nobutake an – noch vor wenigen Jahren wurde ich eher zufällig von Kolleginnen oder Kollegen über Quellen informiert, die z.B. in der British Library oder der Waseda Bibliothek in Tokyo vorhanden waren. Alle diese Quellen sind mittlerweile digitalisiert online verfügbar. Das Modul in Ad Fontes hätten wir noch vor wenigen Jahren nie so schnell zusammenstellen können, weil man früher tagelang vor Ort in die Bibliotheken gehen musste. Gerade in Japan sind sie mit Digitalisaten schon sehr weit und sehr grosszügig – sie sind meist frei zugänglich. Für mich ist das einer der grossen Vorteile der Digital Humanities.
Wie würdet ihr denn diesen Begriff beschreiben – Digital Humanities?
[NK] Das ist ein sehr breiter Begriff, muss ich sagen… Was die digitalen Karten angeht – die digitalen Karten wegen einer historischen Forschung zu bearbeiten, ist für mich schon ein Teil der Digital Humanities, weil man Digitalisate im Rahmen der Geisteswissenschaften verarbeitet. Karteninformationen verarbeitet man aber auch in den Naturwissenschaften, z.B. der Biologie… [lacht] Die Be/Verarbeitung der digitalen Karten gehört also nicht nur zu Digital Humanities, sondern sie gilt einfach als eine von vielen digitalen Kompetenzen, die auch für Geisteswissenschaft eingesetzt werden können.
[JV] Humanities sind Geisteswissenschaften und Digital heisst digital – für mich ist es also die Entwicklung der Geisteswissenschaften unter der digitalen Wende. Darunter fällt natürlich auch die Aufbereitung von Materialien als Digitalisate, so, dass sie aufbewahrt und zugänglich gemacht werden können. Ich persönlich gehe auch nicht weiter.
Aktuell werden viele neue Professuren für Digital Humanities geschaffen, mit der Hoffnung, dass man über den Schritt der Aufbewahrung hinausgehen kann. Auch die Georeferenzierung, die Nobutake angesprochen hat, ist ja bereits eine Art Interpretation bzw. eine neue Art, Karten zu analysieren, die man früher nicht hätte anwenden können. Oder auch «Thick Mapping», also der Versuch, historische Daten auf Karten einzuzeichnen, ebenso wenn man Netzwerke geografisch referenziert und darstellt. Ein anderes Beispiel ist die virtuelle Rekonstruktion von alten Stätten.
Die Frage ist dann, ist das wirklich eine neue Methode, führt das zu neuen Perspektiven und Fragestellungen?
Nobutake Kamiya und ich haben zusammen mit Tobias Hodel, der an der Universität Bern eine Professur für Digital Humanities innehat, ein neues Projekt zu Schweizer Geschichte in der Antragsphase. Wir werden auch auf Ad Fontes ein Modul zu Schweizer Geschichte aufbereiten. Das Neuartige wird sein, dass es sich an Sekundarschülerinnen und -schüler richtet und sie die Möglichkeit haben werden, dort eigene Projekte zu erarbeiten. Es soll eine Art «Bürgerwissen», Citizen Science, sein – die Schülerinnen und Schüler sollen vor Ort gehen und z.B. historische Namen mit den aktuellen vergleichen und auf Karten darstellen. Die andersartige Darstellung als in der klassischen Buchform soll hier zu neuen Perspektiven führen.
Ich bin da manchmal etwas skeptisch – gerade z.B. Big Data mag in gewissen Bereichen wie in den Naturwissenschaften funktionieren. Aber die Geschichtswissenschaft ist kein quantitatives Fach; es ist auch kein Fach, das auf ein Buch verzichten kann, es bleibt bei der Narration.
Es muss auch kein Entweder-Oder sein – es ist doch immer die Frage, was Digital Humanities sein sollen? Das Fachwissenschaftliche entfällt doch eigentlich nie …
Möchtet Ihr noch etwas ergänzen?
[NK]: Durch die Digitalisierung der Gesellschaft erhält man sehr viele Information im Internet. Wenn die Geisteswissenschaft ihre Erkenntnisse für die Gesellschaft öffnet, leistet sie schon einen Beitrag für die Gesellschaft. Aber abgesehen von dieser Bereicherung des frei zugänglichen Wissens werden die geisteswissenschaftlichen Fähigkeiten, z.B. strenger und kritischer Umgang mit Quellenmaterial, als Teil des Informationskompetenz immer wichtiger, mit Hilfe dessen man mit der Informationsüberflut umgeht.
In diesem Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät» hören wir von Christine Grundig, wissenschaftlicher Mitarbeiterin am Kunsthistorischen Institut, über ihre Lehrerfahrungen beim Unterricht von digitalen Methoden. In der Reihe geben Lehrende und Forschende der PhF uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen.
Wer sind Sie – bitte stellen Sie sich vor!
Mein Name ist Christine Grundig, ich habe Staatsexamen für Deutsch, Englisch und Erziehungswissenschaften für das Lehramt an Gymnasien studiert und den Magister Artium an der Universität Würzburg gemacht. Nun schliesse ich gerade meine germanistische Promotion ab. Ich arbeitete v.a. in Projekten, die sich mit digitalen Editionen beschäftigten und habe so Kompetenzen im Bereich der Digital Humanities erworben. Seit Oktober 2017 bin ich als «Digital Humanities Spezialistin» am Kunsthistorischen Institut der Universität Zürich tätig [lacht] – bitte lassen Sie mich diesen Begriff jetzt nicht definieren! Als wissenschaftliche Mitarbeiterin arbeite ich im SNF-Projekt zu Heinrich Wölfflin am Lehrstuhl von Prof. Dr. Tristan Weddigen. Als Dozentin unterrichte ich in meinem Lehrprojekt «Digitale Bildwissenschaften/Digital Visual Studies» bzw. «Digital Skills», das von swissuniversities im Rahmen des Projekts «P8-Stärkung von Digital Skills in der Lehre» 2019-2020 gefördert wird.
Könnten Sie uns diese beiden Projekte kurz vorstellen?
Gegenstand unseres Editionsprojekts ist eine kritisch-kommentierte Edition sämtlicher Publikationen Heinrich Wölfflins – er ist für Kunsthistorikerinnen und Kunsthistoriker eine der zentralen Figuren. Wir haben das grosse Glück, dass wir in der Nähe seiner Wirkungsorte tätig sind – einen Teil seines Nachlasses (Foto- und Diasammlung, Bibliothek, Möbel) hat er dem Kunsthistorischen Institut vermacht. Durch die Nähe zur Universität Basel, in der ein Grossteil des archivalischen Nachlasses liegt (Notizhefte, Manuskripte, Korrespondenz), ist es uns möglich, mit bisher unveröffentlichtem Archivmaterial zu arbeiten. Dies war anderen Editionen bisher nicht oder nicht in diesem Masse möglich.
Es entsteht eine klassische Printedition (die ersten Bände sind bereits publiziert), daneben aber auch eine digitale Edition, die sich an aktuellen Technologien und Standards der Digital Humanities orientiert. Das Material wird in der digitalen Edition im Rahmen eines eigenen Wölfflin-Portals nachhaltig erschlossen, einer Forschungsplattform, die Kontextualisierungen möglich macht und v.a. auch Schnittstellen zu anderen Projekten bietet. Dazu werden die Bände, die bereits im Print erschienen sind in XML/TEI konvertiert, um sie «für das Internet fähig zu machen». Das Versehen mit Referenz- bzw. Normdaten für Werke, Personen, Objekte, Orte, historische Termini und bibliographische Angaben ist ein zentrales Anliegen. Das Portal wird auch Bildmaterial mit hochauflösenden Scans nach IIIF-Standard zugänglich machen, zudem Archivmaterial, das zum Teil mit Tools wie Transkribus oder OCR4all erarbeitet wird.
Wir werden eine semantisch angereicherte Edition bereitstellen, die aus Linked Open Data (LOD) besteht. So können wir einen möglichst grossen Nutzen für die Forschungsgemeinschaft erzielen, weil die Daten dadurch nachhaltig sind und Interoperabilität gewährleistet ist.
Und was beinhaltet das Projekt zu «Digital Skills»?
Wir schlugen im Rahmen von «P8» eine «Einführung in digitale Methoden in der Kunstgeschichte» für Bachelor- und Masterstudierende vor. Ursprünglich war der Fokus eher auf den Bildwissenschaften, doch ich merkte in den ersten Sitzungen, dass ich «ganz vorne anfangen» und den Fokus auf «digital skills» im Allgemeinen legen muss. Es mangelt an Grundkompetenzen der Studierenden im Umgang mit digitalen Methoden.
Konkret besprechen wir im Kurs zunächst, was Digital Humanities überhaupt sind, und ganz wichtig, was die Studierenden eigentlich darunter verstehen. Ich möchte wissen, in welchen Bereichen sie schon mit Tools oder digitalen Methoden gearbeitet haben. Jede/Jeder hat z.B. Datenbanken genutzt oder in Katalogen recherchiert, aber meist wissen sie gar nicht, dass das Datenbanken sind oder was genau dahintersteckt.
Man muss auf einer ganz grundlegenden Ebene aufklären und zeigen, welche Möglichkeiten es in einer Disziplin gibt, mit digitalen Methoden zu arbeiten. Wir behandeln Datenbanken, digitale Editionen, Bilderkennung und Bildannotation, IIIF-Formate oder auch Texterkennung mit OCR.
Wichtig ist mir dabei, praxis- bzw. berufsorientiert vorzugehen, wenn wir digitale Werkzeuge ausprobieren: Die Studierenden sollen ganz konkret mit Tools wie z.B. Transkribus arbeiten, weil sie nur dann die Hemmschwelle überwinden, die Angst davor verlieren. Viele denken sich nämlich, «Ich bin keine Informatikerin, kein Informatiker, ich kann das nicht». Wenn man diese Barriere überwindet, kann es durchaus vorkommen, dass Studierende sich vielleicht sogar an eigenen kleinen (Python-)Skripts versuchen, vielleicht mit etwas Unterstützung aus der Informatik oder Computerlinguistik, aber alleine die Tatsache, dass sie sich damit auseinandersetzen – das ist ganz zentral und erfreulich für mich.
Was kann man mit Transkribus oder OCR4all denn konkret machen?
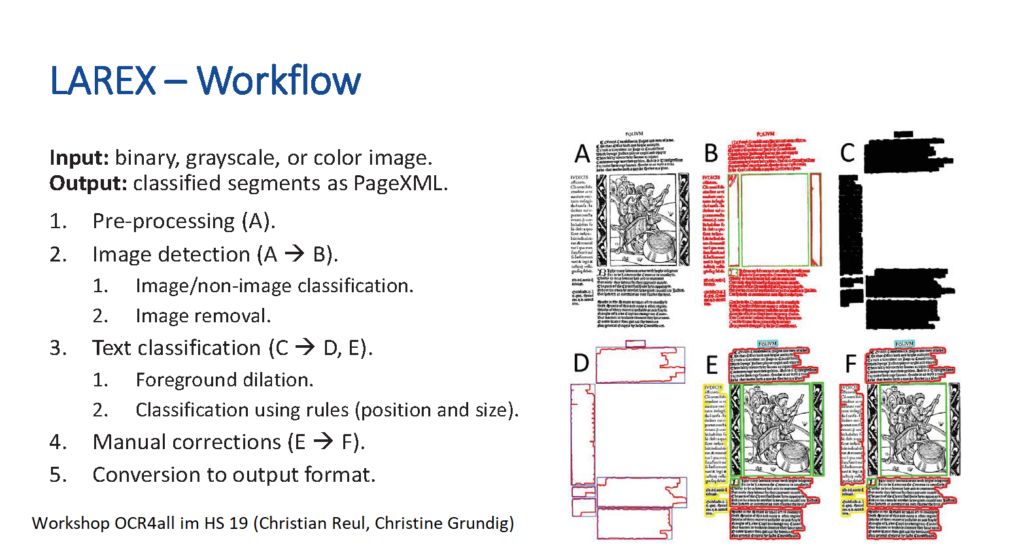
Wenn wir mit Handschriften oder historischen Drucken arbeiten, liegen uns Scans davon vor. Wir schauen dann, wie man diese digital aufbereiten kann: Zeilen segmentieren, einzelne Text- und Bildbereiche voneinander trennen usw. Dafür haben wir z.B. das Segmentierungstool Larex, das zu OCR4all gehört, und das das Layout analysiert: Dies bedeutet, Seiten zu segmentieren, die wir danach transkribieren können. Über die Textdaten, die wir durch die Transkription erhalten, lassen wir «Trainings», also Machine Learning-Algorithmen laufen. Der Output ist zunächst noch fehlerhaft; er wird von Hand korrigiert, um diese optimierten Daten wieder «durch die Maschine laufen zu lassen», sie so weiter anzulernen und dadurch das Ergebnis zu verbessern. Auf diese Weise können selbst Kurrent-Handschriften wie die von Heinrich Wölfflin automatisch erkannt werden, aber auch z.B. Drucke mit Fraktur- oder Antiqua-Schrift, für die es bereits sehr gute Modelle gibt. Diese kommen meist aus dem germanistischen Bereich, stehen aber allen zur Verfügung. So können wir interdisziplinär arbeiten, auf den Modellen aufbauen und die Daten austauschen, sie weiter trainieren.
Beispiel einer Layout Segmentierung mit Larex
Ein Ausschnitt aus der Arbeit mit Transkribus
Wenn Sie sagen, die Hemmschwelle muss überwunden werden – wie gehen Sie da im Unterricht vor, wenn Sie z.B. Daten vor sich haben?
In der Einführung haben wir uns zunächst mit Datenbanken beschäftigt, z.B. was unterscheidet eine Graphdatenbank von einer relationalen Datenbank, welche Datenmodelle stecken dahinter?
In der Hoffnung, dass das Lehrprojekt weitergeführt werden kann, möchte ich unbedingt mehr Seminare anbieten, die auf dieser Einführung aufbauen und konkrete Themen vertiefen. In diesen Seminaren könnte man dann z.B. Daten modellieren oder eigene Daten erheben. Zu jedem der erwähnten Themenbereiche und Tools könnte man eigene Seminare anbieten, die in die Tiefe gehen.
Dennoch bleibt es wichtig, vorher die Grundlagen zu klären: Was ist eine Auszeichnungssprache wie HTML? Was ist XML? Was ist eine Programmiersprache? Die wenigsten wissen, was eigentlich hinter einer Webseite steckt, die sie im Internet aufrufen.
Würden Sie sagen, dass diese Skills innerhalb der eigenen Disziplin unterrichtet werden sollten oder eher fachübergreifend?
Ich denke, es ist wichtig, zunächst im Kleinen anzufangen und am eigenen Institut zu sehen, wie dort das Gefühl, der Bedarf und das Interesse für digitale Methoden sind. Wollen die Studierenden aus den Kunstwissenschaften so ein Angebot überhaupt besuchen? Ich kann Ihnen sagen: Ja. Ich habe nicht damit gerechnet, so viele Anmeldungen zu bekommen, ich musste jedes Mal einen grösseren Raum buchen.
Da ich selbst keine Kunsthistorikerin bin, sondern Germanistin, steht das Thema Interdisziplinarität sowieso im Fokus des Projekts. Die Methoden kann ich genauso gut in der Kunstgeschichte unterrichten wie in der Germanistik oder sie Historikern, Rechtswissenschaftlern oder Theologen anbieten.
Es ist mir ganz wichtig, dass sich hier ein interdisziplinäres, reziprokes Verhältnis, zunächst an der Philosophischen Fakultät, aber auch darüber hinaus entwickelt. In meiner Zusammenarbeit mit der Digital Society Initiative (DSI), die ein «Studium Digitale» vorbereitet, wird mein Einführungskurs im Herbstsemester als einer von drei Kursen pilotiert. Wir möchten sehen, wie so ein fakultätsübergreifendes Angebot mit einem eher fachorientierten Kurs, der an einem Institut angesiedelt ist, harmoniert. Zusätzlich wird der Kurs auch in der Computerlinguistik oder im Minor «Digital Humanities und Text Mining» crossgelistet.
Für den Kurs ist es sehr effizient, ein ganz heterogenes Studierendenfeld zu haben, weil die Teilnehmenden sich gegenseitig inspirieren, voneinander lernen. Einige Studierende kommen von klassischen geisteswissenschaftlichen Methoden, während andere mehr von den Daten her denken. Da verschiedene Perspektiven zusammenkommen, können ganz neue Fragestellungen entstehen.
Was verstehen Sie unter Digital Humanities?
Ich habe Ihnen dazu etwas vorbereitet: Auf der Seite whatisdigitalhumanities.com wird bei jedem Refresh ein neues Zitat zum Thema angezeigt. Mit diesen Zitaten habe ich auch versucht, meine Studierenden an das Thema heranzuführen und so die Vielseitigkeit und Divergenz deutlich zu machen. Ein gutes Beispiel dafür:
«Using digital tools to research the Humanities or using Humanities methods to research the digital.”
Das ist natürlich sehr pauschal, aber ich glaube, man muss offen sein im Umgang mit digitalen Methoden. Lässt man z.B. über fünf Romane ein Tool laufen, das Named Entity Recognition oder Topic Modeling kann (noch, bevor ich meine Fragestellung habe), dann ergeben sich mit Sicherheit Sachverhalte, mit denen man zu Beginn seiner Recherche nicht gerechnet hat. Letztlich sind das ebenso geisteswissenschaftliche Methoden, nur die Quantität ist anders, die Korpora werden grösser.
Ich denke, die digitalen Methoden unterscheiden sich letztlich gar nicht so sehr von den analogen, meine Arbeit wird durch die Hilfsmittel aber einfacher, schneller, interessanter. Das ist für mich auch der Mehrwert – dass ich grosse Mengen an Texten, Bildern und Daten untersuchen kann.
Was für ein Lehrangebot würden Sie sich wünschen?
Für mich ist es entscheidend ist, dass es auch Kurse im Bereich Digital Humanities gibt, für die keine technischen Voraussetzungen nötig sind, sonst würde man einen sehr grossen Teil der Studierenden verlieren. Deshalb wünsche ich mir ein Lehrangebot, das einerseits Grundbausteine bietet, für die keine technologischen Vorkenntnisse relevant sind. Andererseits braucht es aber auch aufbauende Module, die Themen vertiefen. Z.B. eine Übung zu digitalen Editionen, in der die Studierenden einen Text selbst in TEI konvertieren, ein XML Dokument erstellen, vielleicht sogar eine kleine Visualisierung auf einer Webseite erzeugen. Man muss die Studierenden sukzessive heranführen.
Damit Studierende lernen können, mit Daten umzugehen, bräuchte es eigentlich auch ein wenig Infrastruktur, z.B. Webserver oder Datenbanken, die über Server zugänglich sind, nicht?
Ja, das fehlt auf jeden Fall noch. Ich hoffe, dass sich so etwas in einigen Semestern etablieren lässt. Ursprünglich war auch meine Idee für den Kurs, zusammen mit den Studierenden z.B. die EasyDB des Kunsthistorischen Instituts zu nutzen und dort selbst Bilder einzuspeisen, mit Metadaten zu versehen usw. Oder wenn Studierende in einer Arbeit eine kleine Applikation entwickeln – da muss man sich überlegen, wo man diese Daten langfristig ablegt, veröffentlicht und somit nachnutzbar macht.
Möchten Sie noch etwas ansprechen, haben wir ein Thema nicht erwähnt?
Die Evaluationen der Lehrveranstaltung haben deutlich gemacht, dass es den dringenden Bedarf und den Wunsch seitens der Studierenden gibt, dieses Angebot wahrzunehmen und auszubauen.
Die Corona-Krise zeigte, wie wichtig es ist, dass man sein Lehrangebot flexibel anpassen kann. Natürlich fällt das einem Kurs wie meinem, der auf digitale Methoden abzielt wesentlich leichter, die Inhalte auch digital zu vermitteln. Viel Arbeit im laufenden Betrieb war es dennoch – das habe ich aber sehr gern in Kauf genommen.
Es geht nicht nur um digitale Forschungsmethoden, sondern eben auch um digitale Lehrformen. Es ist nicht nur die Frage, welches Konferenztool sich besser eignet, sondern auch, wo ich meine Studierenden «abhole», wie ich sie motivieren kann, zu Hause digital zu arbeiten und sie jede Woche trotzdem das Seminar online besuchen. Ich war begeistert von meinem «Corona-Kurs» und dem Ablauf im letzten Semester – das hat so gut funktioniert, es ging nichts verloren.
Man muss die Krise jetzt als Chance sehen, dieses Angebot zu erweitern. Im Herbstsemester werde ich, wenn möglich, eine Blended Learning Form wählen. Das war ursprünglich gar nicht so angedacht. Doch wir haben im Frühjahrssemester so viel Material produziert – die Studierenden haben selbst Videos erstellt und auf Switch Tube hochgeladen, in denen sie sich z.B. mit bestimmten Datenbanken beschäftigen oder digitale Editionen kritisch besprechen. Dieses riesige Potpourri an digitalem Datenmaterial muss ich jetzt einfach integrieren.
Die Dozierenden brauchen wahrscheinlich auch noch Vorbilder, Modelle, Ideen für den Unterricht…
Richtig, es braucht Hilfestellung und Support; auch auf Dozierendenseite muss die Hemmschwelle überwunden werden. Wenn es ein fakultatives Angebot bleibt, digital zu lehren (als z.B. Blended Learning oder Online-Kurs), dann, so mutmasse ich, entscheiden sich viele dagegen.
Es hat ja vielleicht damit zu tun, dass solche Hilfestellung institutionell verankert sein müsste, nicht nur didaktisch, aber auch Arbeitskraft für die technische Umsetzung – weil die einfach immer viel Zeit braucht…
Genau, und als Ergänzung dazu noch der Hinweis: Die Studierenden empfanden es als sehr problematisch, dass in jedem Kurs mit unterschiedlichen Konferenztools gearbeitet wurde. Da es schnell gehen musste, hat jeder das genutzt, was schon bekannt oder vorhanden war. Auch die Materialien waren sehr verstreut – OLAT, E-Mail, MS Teams… es ist herausfordernd für die Studierenden (aber auch uns Dozierenden), das zu kanalisieren und den Überblick zu behalten – sie haben ja nicht nur einen Kurs. Ich kenne aus einem anderen Kontext z.B. das open source Tool Big Blue Button, das sich gerade auch für Gruppenarbeiten sehr eignet, weil es eine Konferenzsoftware mit einem LMS verbindet.
Ein Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät». In einem schriftlichen Interview mit Barbara Flückiger hören wir von den Möglichkeiten von Deep Learning in der Filmanalyse – und noch vieles mehr. In der Reihe geben Lehrende und Forschende der PhF einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen.
Frau Flückiger, bitte stellen Sie sich vor!
Mein Name ist Barbara Flückiger und ich bin Professorin für Filmwissenschaft. Vor meiner akademischen Karriere war ich international in der Filmproduktion tätig. Diesen beruflichen Hintergrund in Engineering und in der Filmpraxis bringe ich nun konsequent in meine filmwissenschaftliche Forschung und Lehre ein, in der ich mich schwerpunktmässig mit technologischer Innovation und ihren Konsequenzen für die Filmästhetik auseinandersetze. 2015 habe ich mit einem interdisziplinären Projekt einen Advanced Grant des European Research Council zur Untersuchung von historischen Filmfarben eingeworben. Ein komplementäres SNF-Projekt setzt sich mit kulturellen Faktoren der Technikgeschichte auseinander. Ausserdem nehmen wir physikalische und chemische Untersuchungen von Filmmaterialien vor.
Abb. 1 Multi-spektrale Scanner-Einheit für historische Farbfilme, entwickelt im ERC Proof-of-Concept VeCoScan, siehe Video https://vimeo.com/417111087
Obwohl meine Forschung grundlegende Fragen behandelt, sind die Ergebnisse auch für die Anwendung relevant. So entwickle ich mit meinem interdisziplinären Team wissenschaftlich fundierte Methoden für die Digitalisierung des Filmerbes, die sich in technisch avancierten Workflows umsetzen lassen. 2018 habe ich dafür einen Proof-of-Concept des European Research Council erhalten, um die wissenschaftlichen Erkenntnisse auf ihre praktische Umsetzung hin zu untersuchen. Und schliesslich präsentierten wir unsere Forschung mit einer Förderung durch SNF-Agora im letzten Herbst in einer Ausstellung im Fotomuseum Winterthur sowie mit verschiedenen Filmprogrammen einer breiteren Öffentlichkeit.
Abb. 2 Ausstellung Color Mania im Fotomuseum Winterthur
Was verstehen Sie unter «Digital Humanities»?
Ganz allgemein sind Digital Humanities Verfahren und Werkzeuge, die sich digitaler Methoden zur Bearbeitung geisteswissenschaftlicher Fragestellungen bedienen. Sie haben ihre Grundlagen in computergestützten Analysen, die zunächst in den Sprachwissenschaften für Korpusanalysen Verwendung fanden. Heute sind die Sprachwissenschaften nach wie vor sehr dominant. Ein weiteres relativ gut etabliertes Feld sind digitale Methoden in der Bildwissenschaft. Hingegen ist die Analyse von audio-visuellen Bewegtbildern – also Film und Video – noch wenig verbreitet, obwohl es seit rund 20 Jahren immer wieder Ansätze in diesem Bereich gegeben hat. Wegen des hohen Datenumfangs und des komplexen Zusammenspiels von Bild, Bewegung und Ton sind die Anforderungen in diesem Bereich sehr viel höher, sowohl was die Datenverarbeitung betrifft als auch hinsichtlich der Analyse-Instrumente. In den Digital Humanities kommen sowohl qualitative als auch quantitative Methoden zum Einsatz. Zunehmend basieren diese Werkzeuge auf Deep Learning mit neuronalen Netzen.
Abb. 3 Deep Learning Tool zur Gender-Erkennung in Farbfilmen, hier Une femme est une femme (FRA 1961, Jean-Luc Godard), entwickelt im Rahmen von ERC Advanced Grant FilmColors von Marius Högger and Mirko Serbak, Institut für Informatik, Universität Zürich
Könnten Sie uns eines Ihrer Forschungsprojekte im Bereich Digital Humanities vorstellen?
Derzeit untersuchen wir die Technologie und Ästhetik von historischen Filmfarben sowie die kulturelle Kontextualisierung dieser Entwicklungen mit einem interdisziplinären Ansatz. Im ERC Advanced Grant FilmColors haben wir ein Korpus von mehr als 400 Filmen von 1895 bis rund 1995 mit Ansätzen der Digital Humanities untersucht. In einem weiteren SNF-Projekt kommen nun Animationsfilme und neuere digitale Produktionen dazu, für die wir diese Methoden weiterentwickeln.
Abb. 4 Historische Filmfarben aus den ersten drei Dekaden der Filmgeschichte. Mehr als 200 historische Farbfilmverfahren sind systematisiert präsentiert auf der Online-Plattform Timeline of Historical Film Colors, illustriert mit mehr als 20’000 Fotografien von historischen Farbfilmen aus Archiven in Europa, den USA und Japan.
Was sind die spezifischen Methoden «der Digital Humanities», die Sie in diesem Projekt anwenden?
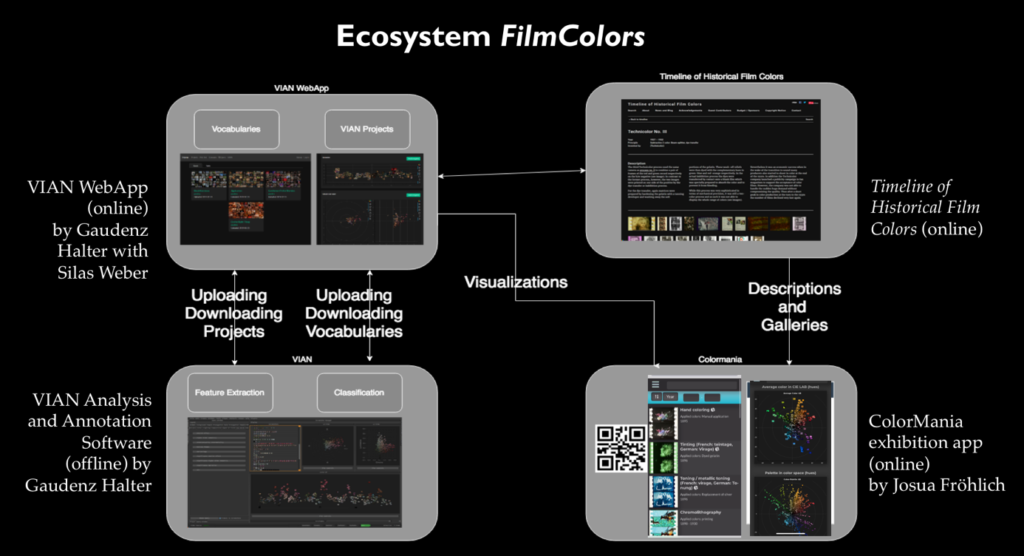
Das Fundament für die derzeitigen Projekte legte die Online-Plattform Timeline of Historical Film Colorszu historischen Farbfilmprozessen. Ab 2012 habe ich sie als umfassende interaktive Ressource für alle Aspekte der technischen Grundlagen, ästhetischen Erscheinungsbilder, Identifikation, Vermessung, Restaurierung und ästhetische Analyse aufgebaut, zunächst mit einer Crowd-Funding-Kampagne und eigenen finanziellen Mitteln. Sie umfasst heute mehrere Hundert Einzeleinträge zu den mannigfaltigen Farbfilmverfahren. Inzwischen haben mein Team und ich mit einem eigens dafür entwickelten Kamera-Set-up mehr als 20’000 Fotos von historischen Farbfilmen in Filmarchiven in Europa, den USA und Japan aufgenommen, die wir online in Galerien präsentieren. Diese Plattform ist Teil eines sich weiter ausdehnenden digitalen Ökosystems.
Abb. 5 Das digitale Ökosystem mit dem Offline-Analyse-Tool VIAN, der Online-Plattform VIAN WebApp zur Auswertung und Visualisierung auf Korpusebene, der Timeline of Historical Film Colors und der ColorMania-App für die Ausstellung im Fotomuseum Winterthur.
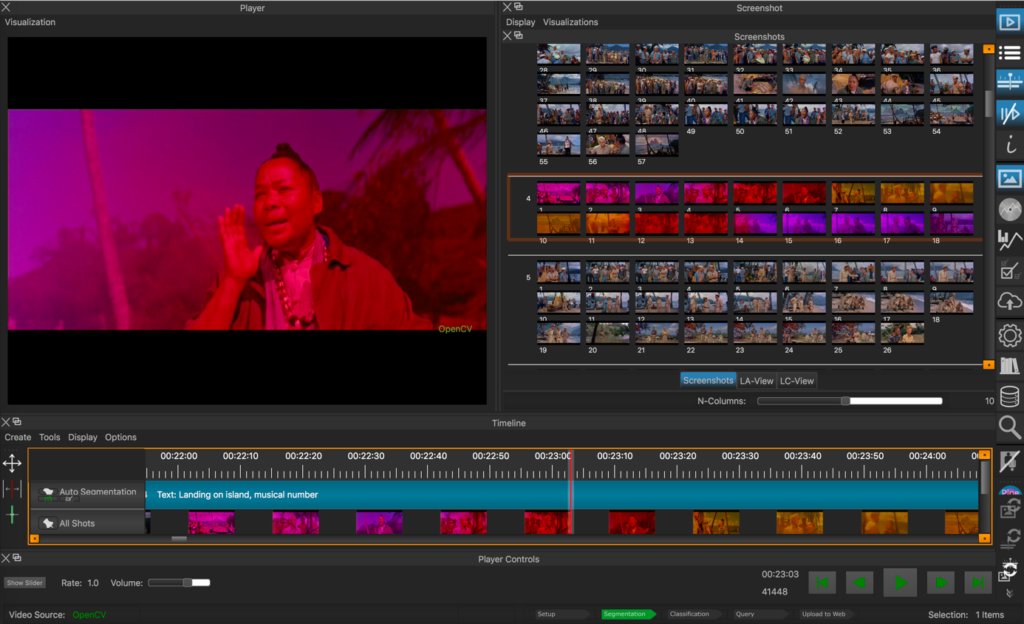
Im ERC Advanced Grant FilmColors entwickeln wir seit 2017 in Zusammenarbeit mit dem Visualization and MultiMedia Lab von Renato Pajarola (IFI UZH) nun das Digital-Humanities-Tool VIAN für die Film-Annotation und -Analyse auch mit Unterstützung durch Digitale Lehre und Forschung, der Digital Society Initiative und Citizen Science. Entwickler ist Gaudenz Halter, der ein fantastisches Werkzeug mit vielen auf die Bedürfnisse der filmästhetischen Forschung zugeschnittenen Features geschaffen hat.
Abb. 6 Analyse- und Annotationssystem VIAN, Interface mit Segmentierungsleiste und Screenshot-Manager. Film: South Pacific (USA 1958, Joshua Logan)
Dieses in Python programmierte Offline-Tool ist mit der Crowdsourcing-Plattform VIAN WebApp verknüpft, die ebenfalls hauptsächlich Gaudenz Halter entwickelt. Dort sind alle Filmanalysen des Korpus für die Auswertung und Visualisierung der Ergebnisse online verfügbar.
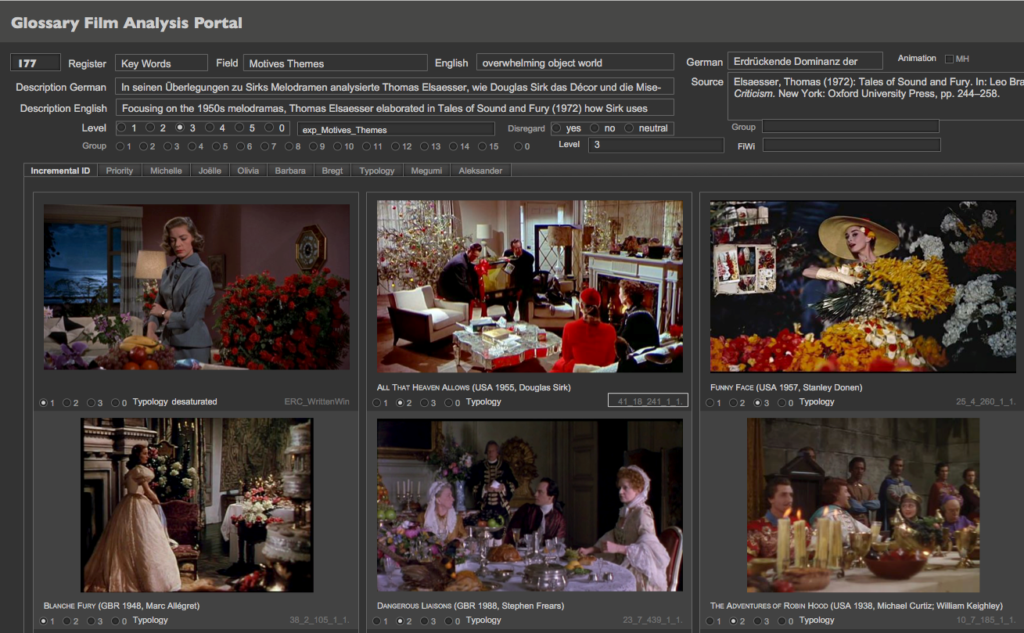
Abb. 7 Kolorimetrische Analyse und Extraktion von Farbpaletten in VIAN. Film: Sedmikrásky [Daisies] (CZE 1966, Vera Chytilová), siehe Tutorial zur Kolorimetrie https://vimeo.com/378587418In VIAN kommen zusätzlich zu manuellen Methoden Deep Learning Tools zum Einsatz, welche unter anderem eine Figur/Grund-Trennung vornimmt oder Figuren und Gender automatisch erkennen kann. Nach und nach implementieren wir zudem automatische Analyse von Bildkompositionen, visueller Komplexität, Farbverteilungen, Mustern und Texturen. Die Filme werden automatisch segmentiert, Screenshots erstellt und gemanagt. Zur Auswertung gehört die Figur-/Grund-Trennung, die kolorimetrische Analyse und viele Visualisierungsmethoden. Diese Features sind in auch in die WebApp integriert, was es ermöglicht, das ganze Korpus oder bestimmte Subkorpora, aber auch einzelne Filme oder Segmente auszuwerten und zu visualisieren. Zu diesem Zweck haben wir im Projekt ERC Advanced Grant FilmColors ein kontrolliertes Vokabular von rund 1’200 analytischen und theoretischen Konzepten definiert. Jedes dieser Konzepte ist in einem Glossar mit exemplarischen Filmbildern dargestellt mit Auswertungen zur Häufigkeit in bestimmten Perioden, Farbprozessen oder Filmgenres.
Abb. 8 Definition und Illustration eines der theoretischen und analytischen Konzepte, die «erdrückende Dominanz der Objektwelt» in der FileMaker-Glossardatenbank. Dieses kontrollierte Vokabular ist nun in VIAN und in die VIAN WebApp integriert.
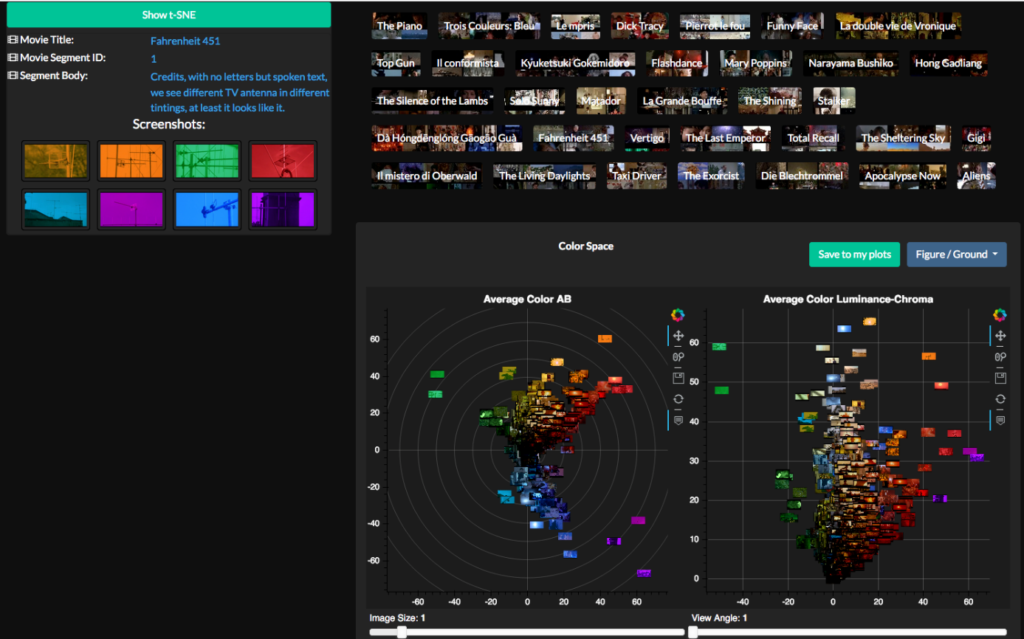
Für die manuelle Annotation haben wir zunächst ein Netzwerk von relationalen Datenbanken in FileMaker erstellt, das ich weitgehend selbst programmierte. So konnte ich sehr flexibel auf Desiderate aus dem Team reagieren. Aus diesen Analysen sind mehr als 170’000 Screenshots und mehr als eine halbe Million Aufsummierungen von Resultaten entstanden. Anschliessend hat Gaudenz Halter alle Resultate in die VIAN WebApp integriert; sowohl als von Menschen lesbare JSON-Dateien wie auch als numerische Werte in HDF5-Daten-Containern.
Abb. 9 Interaktive Visualisierung von Resultaten auf Korpus-Ebene in der VIAN WebApp, hier Abfrage monochrome Filter in Filmen von 1955–1995, siehe Video https://vimeo.com/402360042
Welchen Mehrwert bringen Ihnen diese Methoden in diesen Projekten, verglichen mit «analogen» Ansätzen?
Der Mehrwert ist enorm. Ohne solche Ansätze wäre die kollaborative Arbeit an so grossen Korpora gar nicht möglich. Um solche Tools zu entwickeln, ist jedoch eine vertiefte interdisziplinäre Zusammenarbeit zwischen den Geisteswissenschaften und der Informatik notwendig, denn alle Konzepte, alle Auswertungs- und Analysemethoden, alle Ansätze zur Visualisierung der Analysen müssen aus beiden Disziplinen theoretisiert und reflektiert werden.
Wenn diese Voraussetzungen gegeben sind, lassen sich über Visualisierungen als diagrammatische Methoden neue Einsichten gewinnen, die den sprachlichen Horizont überschreiten und unmittelbar der Anschauung zugänglich sind. Dies ist für das audio-visuelle Medium Film, aber auch für andere visuelle Gegenstandsbereiche von unschätzbarem Wert; ohne solche Methoden der systematischen Untersuchung bleiben Ergebnisse anekdotisch und abstrakt zugleich. Visualisierungen schaffen also neue Formen von Evidenz.
Allerdings fallen einem die Ergebnisse auch mit solchen hochausdifferenzierten Werkzeugen nicht in den Schoss. Sie bedürfen immer der Reflexion, der Kontextualisierung und der Interpretation. Oftmals sind die Ergebnisse weit weniger eindeutig, als man das gerne hätte, und weder eine reine Auswertung noch eine Visualisierung ist bereits ein Ergebnis, sondern die Resultate bedürfen immer der Interpretation. Als Forschende müssen wir daher Hypothesen bilden und mit neuen Abfragen oder Visualisierungen differenziertere Resultate erzeugen.
Deshalb ist es von entscheidendem Wert, dass wir mit VIAN Ergebnisse und Abfragen interaktiv, basierend auf dem individuellen Forschungsinteresse anpassen können. So erhalten wir nicht nur Übersichtsvisualisierungen, sondern wir können von der Korpusebene in die einzelnen Szenen und Bilder hineinzoomen und sie uns anzeigen lassen, um detailliertere Informationen zu bekommen.
Wären diese Ansätze auch für andere Disziplinen anwendbar?
Ja, wir arbeiten nun mit anderen Fachbereichen aus den Geisteswissenschaften zusammen, unter anderem mit der Kunstgeschichte SARI / Digital Visual Studies von Prof. Dr. Tristan Weddigen und mit der Sprachwissenschaft in LiRI von Prof. Dr. Elisabeth Stark. Diese Tools lassen sich grundsätzlich in allen Disziplinen anwenden, die mit Videos oder grossen Bildersammlungen / Visualisierungen arbeiten, so in der Psychologie / Verhaltensforschung, Ethnologie, Soziologie, Politologie, aber auch in naturwissenschaftlichen Fächern wie der Medizin und den Life Sciences, zum Beispiel der Neurowissenschaft. Es sind derzeit sehr viele solche Kooperationsprojekte national und international in der Pipeline. Da habe ich dieses Jahr eine Menge Arbeit vor mir.
Wie und wo bringen Sie diese Methoden in der Lehre ein?
Wir haben seit letztem Jahr zunehmend externe Nutzer als Betatester integriert. Dies sind Doktorand*innen, PostDocs, aber auch Professor*innen der UZH und ausländischer Universitäten. Die Herausforderung besteht im Support, denn wir müssen einerseits die Usability mit den Betatestern überprüfen, andererseits die Software fortlaufend anpassen. Dafür hat uns DLF eine 20%-Stelle finanziert. Es gibt eine umfassende Dokumentation und wir erstellen Video-Tutorials für die Einführung.
Ich habe soeben einen kompetitiven Lehrkredit beantragt, damit wir VIAN im kommenden Jahr auf Bachelor- und Masterstufe in der Lehre einsetzen können. Denn auch die Dozierenden müssen geschult werden und brauchen Unterstützung. Es ist ein Irrglaube, eine solch differenzierte Software sei selbsterklärend. Obwohl VIAN sehr flexibel und intuitiv ist, muss man den Umgang damit doch lernen, und es braucht etwas Übung, bis man effizient damit arbeiten kann.
Die Studierenden erhalten so Gelegenheit, sich mit digitalen Werkzeugen und Methoden auseinanderzusetzen, neue Kompetenzen in der Anwendung zu erwerben und gleichzeitig aktiv an der Weiterentwicklung mitzuarbeiten, indem sie Feedback geben und ihre Bedürfnisse artikulieren.
Welche technischen Kenntnisse sollten Studierende mitbringen?
Das Interface von VIAN verlangt keine besonderen technischen Kenntnisse, denn es ist spezifisch auf den Einsatz durch Geisteswissenschaftler und für die ästhetische bzw. narratologische Analyse entwickelt worden. Allerdings ist es von Vorteil, wenn man technikaffin ist und gerne am Computer arbeitet. Auch eine Vorstellung von Auswertungen und der Arbeit mit Datenbanken ist von Vorteil, lässt sich aber ohne spezifische Grundkenntnisse im Lauf der Anwendung erwerben.
An der Timeline of Historical Film Colors arbeiten Studierende im Datenmanagement mit und kodieren die Quellen in HTML, die sie danach in das Backend der Plattform einpflegen und mit einem Thesaurus annotieren.
Wo sehen Sie Bedarf an Infrastruktur, Informatik-Grundausbildung oder anderem an der Philosophischen Fakultät, um «Digital Humanities» in Ihrem Fachgebiet betreiben und in der Lehre einbringen zu können?
Die Philosophische Fakultät braucht dringend eine Digital-Humanities-Strategie, sie muss verstehen, dass sie es sich nicht leisten kann, auf diese digitalen Ansätze und Methoden in den Geisteswissenschaften zu verzichten. Diese Strategie muss von der Unileitung gestützt und eingefordert werden, denn die Universität Zürich muss sich im internationalen Feld positionieren. International findet zunehmend ein Wettbewerb um die besten Talente statt; die besten Universitäten der Welt bemühen sich sowohl um die begabtesten Studierenden als auch um herausragende Forschende. Mit der Digital Society Initiative haben wir bereits einen Verbund von exzellenten Professor*innen auf Universitätsebene, in dem ich seit der Gründung dabei bin.
Mit meinem Projekt, SARI / Digital Visual Studies sowie LiRI sind wir in einer guten Ausgangsposition, aber diese Einzelinitiativen müssen in einen übergeordneten institutionellen Rahmen eingebettet werden und vor allem müssen für diese Integration finanzielle Mittel gesprochen werden. Digitale Ansätze sind nicht selbsterhaltend, sie sind einem steten Wandel unterworfen und entwickeln sich dynamisch im Verbund mit Hardware und Trends in anderen Anwendungsbereichen. Um den Erhalt zu garantieren, brauchen wir spezialisierte technische Infrastruktur, wir brauchen Entwickler, die unsere Methoden und Werkzeuge verstehen und umsetzen, wir brauchen interdisziplinär denkende Doktorand*innen und PostDocs, wir brauchen Techniker*innen, die sich mit den Anforderungen der Forschung beschäftigen. Anders als in den Naturwissenschaften, in denen es selbstverständlich ist, dass ein Labor Mittel hat, um die technische Infrastruktur à jour zu halten, sind diese Anforderungen in den Geisteswissenschaften noch wenig präsent. Bei uns ist die Förderung in der Regel projektbasiert. In meinem Fall sind die Mittel aus dem ERC Advanced Grant mittlerweile erschöpft; das bedeutet, dass die Weiterentwicklung des gesamten Ökoystems, das wir um VIAN herum aufgebaut haben, akut gefährdet ist. Dies, obwohl das Interesse an den Werkzeugen – sowohl uniintern als auch international, fachbezogen und fachübergreifend – sehr gross ist. Der Ball liegt nun bei der Universität, die Grundsicherung und langfristige Perspektive für solche Methoden und Tools sicherzustellen. Dafür ist eine strukturierte Kommunikation aller Stufen und Einheiten der Universität notwendig sowie auch die Kommunikation nach aussen, denn dieses Feld ist sehr attraktiv.
Dank meiner Vorarbeiten kommen viele potenzielle nationale und internationale Partner aktiv auf mich zu. Sie wollen sich vernetzen und von den Entwicklungen profitieren. Das begrüsse ich sehr und pflege einen kooperativen und offenen Austausch. Mit dem Joint Digital Humanities Fund haben wir bereits eine etablierte Kooperation mit der FU Berlin sowie neu der Hebrew University in Jerusalem. Wir arbeiten mit einem internationalen Konsortium an Standardisierungen, welche die Interoperabilität der Ansätze und Tools sicherstellen soll und planen ein übergeordnetes Ökosystem, in das diese Werkzeuge integriert werden können.
Das vergangene Semester hat gezeigt, dass die digitale Lehre und Forschung ein unverzichtbarer Baustein für die Weiterentwicklung der Universitäten sind. Die UZH darf den Anschluss nicht verpassen.
Gibt es Fragen, die ich nicht gestellt habe, die für die Diskussion aber wichtig sind?
Ja, meine persönlichen Ressourcen. Ich habe eine Professur ad personam, ohne Stellen. Meine Arbeitsbelastung in den vergangenen Jahren war gigantisch, und es sieht nicht nach Besserung aus. Auch wenn ich über sehr viel Energie verfüge und überraschend zäh bin, muss ich zu viel leisten. Auf Dauer ist das nicht machbar.
Aber ich bin auch eine ziemlich unerschütterliche Optimistin und nehme an, dass sich die Dinge am Ende schon zum Positiven entfalten.
Dieser Beitrag entstand im Rahmen einer kleinen Reihe zu «Digital Humanities an der Philosophischen Fakultät». Lehrende und Forschende der PhF geben uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen. Wir diskutieren den Begriff «Digital Humanities» von ganz verschiedenen Perspektiven aus. Heute stellt uns Noah Bubenhofer, Professor am Deutschen Seminar, eine digitale Korpuslinguistik vor.
Herr Bubenhofer, vielen Dank, dass Sie bei dieser Reihe mitmachen – bitte stellen Sie sich kurz vor!
Ich bin germanistischer Linguist, seit September 2019 Professor am Deutschen Seminar der UZH. Ich interessiere mich für eine kultur- und sozialwissenschaftlich orientierte Linguistik, die davon ausgeht, dass Sprache und gesellschaftliches Handeln in einem engen Verhältnis stehen und dass man deshalb über linguistische Analysen etwas darüber lernen kann, wie eine Gesellschaft oder eine Kultur funktioniert.
Ich arbeite sehr stark korpuslinguistisch – ein Korpus ist letztlich eine Sammlung von Textdaten, die meist linguistisch aufbereitet sind und linguistisch analysiert werden. In der Korpuslinguistik verbinde ich quantitative mit qualitativen Methoden, um grössere Textdatenmengen auf Musterhaftigkeit hin analysieren zu können – hier verwende ich natürlich digitale Methoden. Korpuslinguistik gibt es schon sehr lange; mit der Digitalisierung hat sie einen neuen Drive erhalten, weil es sehr viel einfacher geworden ist, sehr grosse Textdatenmengen zu verarbeiten.
Was verstehen Sie unter «Digital Humanities», auch in Bezug zu Ihrem Forschungsgebiet?
Ich erlebe «Digital Humanities» als extrem heterogen, und manchmal ist es gar nicht so klar, ob ich das, was ich mache, auch dazu zählen kann – gerade weil die Korpuslinguistik eigentlich schon eine sehr lange Tradition in der Linguistik hat.
Einerseits bedeutet «Digital Humanities» für mich, digitale Methoden auf digitalen Daten anzuwenden und letztlich geisteswissenschaftliche Fragestellungen zu verfolgen. Andererseits reflektiert man «Digitalität per se» mit geisteswissenschaftlichen Theorien: Was macht «Verdatung» mit Informationen, was ist eigentlich ein Algorithmus, und so weiter.
Die Kombination dieser beider Aspekte macht das Alleinstellungsmerkmal von «Digital Humanities» im Vergleich zu anderen Disziplinen aus, die auch mit digitalen Daten und Methoden arbeiten, wie z.B. Informatik, Data Mining o.ä.
Sie sagten «Disziplin» im Zusammenhang mit Digital Humanities …
[lacht] Dieselbe Debatte gibt es auch in der Korpuslinguistik – ist sie eine Subdisziplin der Linguistik oder ist sie eher ein Denkstil? Ich argumentiere immer für Letzteres, da es eine bestimmte Art und Weise ist, Sprache anzusehen.
Ferdinand de Saussure führte die Unterscheidung von «langue» und «parole» ein, dabei ist «langue» sozusagen das Sprachsystem und «parole» die tatsächlich geäusserte Sprache. Lange interessierte sich die Linguistik hauptsächlich für die «langue». Die Korpuslinguistik machte erst den Fokus auf die «parole» stark, indem die Musterhaftigkeit in der gesprochenen und geschriebenen Sprache untersucht wurde.
Diese Verschiebung der Perspektive findet man in den Digital Humanities teilweise wieder. Man ist an anderen Aspekten der Daten interessiert und hat dadurch auch ein anderes theoretisches Modell im Hintergrund. Deshalb sind die Digital Humanities für mich auch eine Denkrichtung, die versucht, mit spezifischen Methoden einen neuen Blick auf die vorhandenen Daten zu erhalten.
Können Sie uns ein Beispiel geben, vielleicht an einem Ihrer Forschungsprojekte?
In einem Projekt habe ich Alltagserzählungen, genauer Geburtsberichte gesammelt. In diesen schrieben Mütter nieder, wie sie die Geburt ihres Kindes erlebt hatten. Die Berichte stammen aus Threads in Online-Foren, die genau für dieses Genre vorgesehen sind. Ich habe nun 14’000 Berichte aus sechs unterschiedlichen deutschsprachigen Foren gesammelt, analysiert und dabei eine Diskrepanz zwischen diesem sehr individuellen Erlebnis und der Erzählung darüber aufgezeigt: In der Erzählung konnte eine extreme Musterhaftigkeit mit einem bestimmten erzähltypischen Ablauf festgestellt werden, mit bestimmten Themen und Motiven, die sich wiederholten. Die Musterhaftigkeit dieser Erzählungen konnte mit Hilfe digitaler Methoden freigelegt werden.
Genau hier kommt auch wieder der Unterschied z.B. zu reinem Data Mining ins Spiel, wo Fragen wie Narrativität und Sequenzialität zu kurz kommen. In den Geisteswissenschaften ist es uns dagegen klar, dass diese Aspekte eine Rolle spielen: Man kann einen Text nicht einfach als «Sack von Wörtern» (bag of words) auffassen, sondern es spielt eine Rolle, in welcher Sequenz diese Wörter vorkommen.
Es ging in diesem Projekt also auch darum, die Methodik so anzupassen, dass man diese narrativen Strukturen identifizieren kann.
Wie gehen Sie (technisch) vor, um eine solche Analyse durchzuführen?
Zunächst müssen die Daten «gecrawlt», d.h. automatisiert vom Web heruntergeladen werden. In einem aktuellen Projekt zu COVID19 News-Kommentaren haben wir z.B. mit Python und Selenium gearbeitet. Dabei übernimmt Selenium die «Benutzerinteraktion» auf einer dynamischen Webseite – diese sind heute ja nicht mehr einfach statisches HTML.
Diese Daten werden nun linguistisch, d.h. mit Wortarten-Tagging, syntaktischem Parsing, semantischen Annotationen etc. versehen. Dafür verwenden wir an unserem Lehrstuhl das UIMA-Framework, das mit Modulen oder eigenen Python-Skripts erweitert werden kann, die das Tagging oder andere Verarbeitungsschritte auf diesen Textdaten durchführen.
Im nächsten Schritt gehen diese verarbeiteten Daten in die Corpus Workbench, eine Datenbank, die spezialisiert ist, korpuslinguistisch annotierte Daten zu verwalten und zu analysieren. Für die Analyse wichtig sind in unserem Gebiet die n-Gramme – Gruppen von n Wörtern, sprachliche Muster –, die wir mit unserer selbst entwickelten Software cwb-n-grams berechnen können. Wie diese n-Gramme berechnet werden, kann dabei ganz unterschiedlich sein: Nimmt man als Basis die Grundformen der Wörter, reduziert man Redundanzen, behält man «Füllwörter» oder nicht, wie lange soll das n-Gramm sein, etc. Wir haben die Methodik zudem so erweitert, dass wir zusätzlich auch die erstellten Annotationen mit einbeziehen.
Die (statistische) Analyse selber kann man schliesslich z.B. mit R und plotly durchführen, für das ein Paket existiert, das direkt auf die Corpus Workbench zugreifen kann. Hier vergleichen wir die Häufigkeiten jeweils mit einem Referenzkorpus, um statistisch signifikante n-Gramme finden zu können. Signifikant heisst in dem Zusammenhang: Welche n-Gramme sind typisch für Geburtsberichte und nicht aus anderen Gründen häufig vorgekommen.
Der Output kann z.B. eine interaktive Grafik sein – hier das Beispiel zum Projekt «Geburtsgeschichten», das typische Positionen der n-Gramme im Verlauf der Erzählung darstellt. Man sieht an den n-Grammen, dass diese sprachlichen Muster über die 14’000 Texte hinweg immer wieder gleich und an ähnlichen Positionen in der Erzählung vorkommen. Die y-Achse zeigt die Standardabweichung bezüglich Position in der Geschichte: Je weiter oben ein n-Gramm erscheint, desto variabler war die Position im Verlauf. Auf der Grafik sind bestimmte Cluster von n-Grammen sichtbar, die aber weniger variabel waren, gegen Ende der Erzählung z.B. das n-Gramm «gleich auf den Bauch gelegt».
Eine rhetorische Frage: Was ist der Mehrwert gegenüber analogen Methoden?
[lacht] … Genau, was bringt’s wirklich? Zum einen, 14’000 Geschichten kann ich nicht einfach durchlesen. Aber im Ernst: Es zeigt sich eine Musterhaftigkeit in der Sprache, die nicht auffallen kann, wenn man nur Einzeltexte vor sich hat. Ich finde dieses datengeleitete Paradigma wichtig: Welche Strukturen ergeben sich eigentlich datengeleitet und nicht theoriegeleitet? Sehr wichtig ist dabei, dass wir im Anschluss eine geisteswissenschaftliche Interpretation davon machen. Man hat nicht zuerst eine theoriegeleitete Hypothese, die man stützen oder verwerfen kann, sondern generiert die Hypothese vielleicht erst durch diese Interpretation. Natürlich muss man dann wieder zurück in die Daten und prüfen, ob diese Hypothese wirklich stimmt – und man darf nicht vergessen, dass man trotz des induktiven Vorgehens noch Prämissen gesetzt hat: Allein die Definition, was als Wort aufgefasst wird, welche Daten wähle ich aus, etc.
Eine Challenge in der Linguistik ist heute, dass die Informatik uns neuronale Lernmethoden gibt, die statistische Modelle aus den praktisch unverarbeiteten Daten lernen. Der Algorithmus muss gar nicht mehr wissen, was ein Wort oder eine Wortart ist. Die Idee ist dann, dass sich die Musterhaftigkeit und allenfalls Kategorien wie Wortarten aus den Daten ergeben. Dies stellt natürlich die klassische Linguistik in Frage – wir experimentieren aber damit und fragen uns, inwiefern linguistische Theorien helfen zu verstehen, warum solche Methoden überhaupt funktionieren und wie sie verbessert werden können. Und doch ist es auch hier wichtig zu sehen, dass neuronale Lernmethoden keinesfalls objektive, neutrale Modellierungen von Sprache darstellen, sondern mit der Datenauswahl und den gewählten Parametern eben spezifischen Sprachgebrauch abbilden. Die Modelle sind genauso voller Verzerrungen – wir würden sagen: diskursiv geprägt – wie ihre Datengrundlage, was z.B. bei AI-Anwendungen problematische Folgen haben kann.
Für die Bearbeitung dieser Fragestellungen werden sehr viele verschiedene Technologiekenntnisse, aber auch sehr viel theoretisches Wissen vorausgesetzt – wie kann man die Studierenden da heranführen?
Man kann heute nicht Linguistik studieren, ohne eine Vorstellung zu haben, was algorithmisch möglich ist. Sie müssen verstehen, was ein Skript machen kann, wie HTML, XML und Datenbanken funktionieren, oder auch, was Machine Learning ist.
Als ich noch in Dresden war, haben wir eine Einführung in die Programmierung für Germanistinnen und Germanisten gegeben, die sich sehr bewährt hat. Der Kurs war sehr niederschwellig, die Studierenden sollten ein kleines Skript zu einem linguistischen Projekt schreiben. Einige Studierende vertiefen diese Kenntnisse weiter, andere nicht – doch zumindest können sie auf Augenhöhe mit Personen sprechen, die sie vielleicht in weiteren Projekten unterstützen.
Hier an der UZH plane ich gerade, hoffentlich mit einem Lehrkredit, ein E-Learning Modul zu Programmierkompetenzen für Geisteswissenschaftlerinnen und Geisteswissenschaftler. Das Modul soll aus Bausteinen bestehen, die man auch gut in andere, bereits bestehende Module einbinden kann und die teilweise auch curricular verpflichtend sind.
Heisst das, dass die Programmierkenntnisse disziplinär gebunden unterrichtet werden sollen? Oder lernt man besser Python in einem Pythonkurs, SQL in einem SQL-Kurs etc.?
Es gibt natürlich unterschiedliche Lerntypen, doch m.E. ist eine disziplinäre Verortung für die Mehrheit der Studierenden in den Geisteswissenschaften wichtig, weil man an den geisteswissenschaftlichen Fragen interessiert ist. Sonst hätte man vielleicht Informatik studiert. Es ist viel einfacher, wenn man eine konkrete Forschungsfrage hat, der man nachgehen kann und entlang derer man die nötigen Kenntnisse erwirbt. Man ist so einfach viel motivierter.
Hier schliesst sich auch der Bogen zur Frage, was «Digital Humanities» sein könnten…
Ja, denn für uns Geisteswissenschaftlerinnen und Geisteswissenschaftler ist eine Methode dann interessant, wenn sie «nahrhaft» für Interpretation ist, d.h. wenn ich daraus etwas machen kann, das mir in meinen Fragen weiterhilft. Es ist eine andere Art von Nützlichkeit als eine rein technologische für eine Anwendung, aber natürlich benötigen wir die Hilfe von anderen Disziplinen, wir haben das Know-How nicht, z.B. einen Part-of-speech-Tagger oder statistische Methoden zu verbessern.
Haben wir ein wichtiges Thema in der Diskussion ausgelassen, haben Sie eine Ergänzung oder einen Ausblick?
In meiner Habilitationsschrift, die demnächst erscheint, geht es um die «Diagrammatik», nämlich wie Darstellungen und Visualisierungen helfen, Daten anders zu verstehen. Es geht hier nicht nur um quantitative Aspekte, sondern darum, wie verschiedene Darstellungsformen neue Sichtweisen auf Daten ermöglichen.
Ein Beispiel ist die «Konkordanzliste»: Man hat hier einen Suchausdruck und sieht dessen unmittelbaren Kontext in verschiedenen Texten. Die Konkordanzdarstellung gibt es schon seit dem Mittelalter, er bricht die Einheit des Textes auf und versucht, einen Blick auf Fundstellen listenförmig darzustellen. Dadurch wird der Text «zerstört», aber gleichzeitig gewinnt man ganz viel, weil man eine neue Sicht erhält.
Für mich ist auch das auch eine Frage für die Digital Humanities, weil wir eigentlich ständig versuchen, unsere Daten in andere Ansichten zu transformieren, um etwas Neues daraus zu gewinnen. Viele dieser Visualisierungen sind erst mit den digitalen Mitteln möglich geworden.
In diesem Beispiel werden Gesprächstranskripte visualisiert: Die drei Gesprächsteilnehmerinnen und Gesprächsteilnehmer sind als Kreiszentren dargestellt. Die Jahresringe stellen einzelne Beiträge der Teilnehmenden dar. Je mehr Ringe, desto mehr sogenannte „turns“ wurden von dieser Person beigetragen. Die verschiedenen Durchmesser der Jahresringe ergeben sich aus den Beitragslängen. Einige Beispiele können auf Noah Bubenhofers Seite gleich ausprobiert werden.
Herr Bubenhofer, ich danke Ihnen für dieses Gespräch!
Geobrowser sind Visualisierungstools zur Darstellung von geographischen Punkten oder Routen. In den Geisteswissenschaften können sie unter anderem gewinnbringend für Forschungsfragen eingesetzt werden. Durch die umfassende geographische Visualisierung erschliessen sich oftmals neue Zusammenhänge oder Fragestellungen. So kann man beispielsweise mithilfe eines Textkorpus evaluieren, welche Adjektive gehäuft bei der Beschreibung einer bestimmten Ortschaft vorkommen, oder an welchen Orten die meisten Handschriften gefunden wurden.
Im Folgenden sollen vier webbasierte Tools zur geographischen Visualisierung kurz mit ihren Vor- und Nachteilen vorgestellt werden: DARIAH DE Geobrowser, Palladio, Nodegoat, sowie Google My Maps.
Am 22. Oktober wurde der Cappelli gehackt! Dank der zahlreichen engagierten „Hacker“ konnten sämtliche 14’356 Abkürzungen digitalisiert werden! Doch es gibt noch mehr zu tun, denn nun müssen sämtliche Abkürzungen auf Schreib-, Tipp- und Positionierungsfehler überprüft werden.
Helfen auch Sie mit, die eingegebenen Abkürzungen zu überprüfen und zu kontrollieren!
Das Team von «Ad fontes» hackt Cappelli und braucht Deine Hilfe!
Sie wollen das Lexicon abbreviaturarum von Adriano Cappelli digital in seine Einzelteile zerlegen und jede Abkürzung systematisch suchbar machen.
Der Cappelli stellt seit 1899 einen Meilenstein in der Forschung dar. Das Werk enthält eine alphabetische Übersicht und die Auflösung von ca. 15’000 lateinischen sowie italienischen Abkürzungen.
Mit dem Crowdsourcing des Cappelli werden die Abkürzungen nicht nur digitalisiert, sondern anhand eines eigens dafür entwickelten Webinterfaces strukturell systematisiert, um Suchfunktionalität zu erhöhen und Nutzbarkeit zu optimieren. Somit erübrigt sich das zeitaufwändige Blättern im Buch. Künftig lässt sich direkt nach erkennbaren Buchstaben in den Abkürzungen, oder nach Positionen der Abkürzungszeichen suchen. Dies alles natürlich frei und kostenlos und mit der Möglichkeit die erhobenen Daten runterzuladen.
Unser Ziel ist die vollständige Erfassung des Cappelli bis Ende 2015. Aufbauend auf diesen Daten wollen wir ein Tool zur Aufnahme weiterer Abkürzungen in Handschriften realisieren.
Hilf mit den Cappelli zu hacken und einen neuen Meilenstein der Forschung zu realisieren:
Am Donnerstag 22. Oktober 2015 findet im Hauptgebäude der Universität Zürich, Rämistrasse 71, der Cappelli-Hackathon statt. Zwischen 14:00 und 23:00 Uhr gilt es gemeinsam sämtliche im Cappelli enthaltenen Abkürzungen zu digitalisieren und zu kategorisieren.
Die Computer stehen bereit, aber auch eigene Laptops können mitgebracht werden.
Machen Sie mit und unterstützen Sie dieses Projekt!